







一、实验目的
掌握各种内部排序的方法并通过实验能够根据不同问题的要求选择合适的排序方法
二、实验内容1
-
问题描述
定义一个无序序列,使用直接插入排序、折半插入排序、希尔排序、冒泡排序、快速排序、堆排序、归并排序方法使之有序; -
数据结构及算法设计
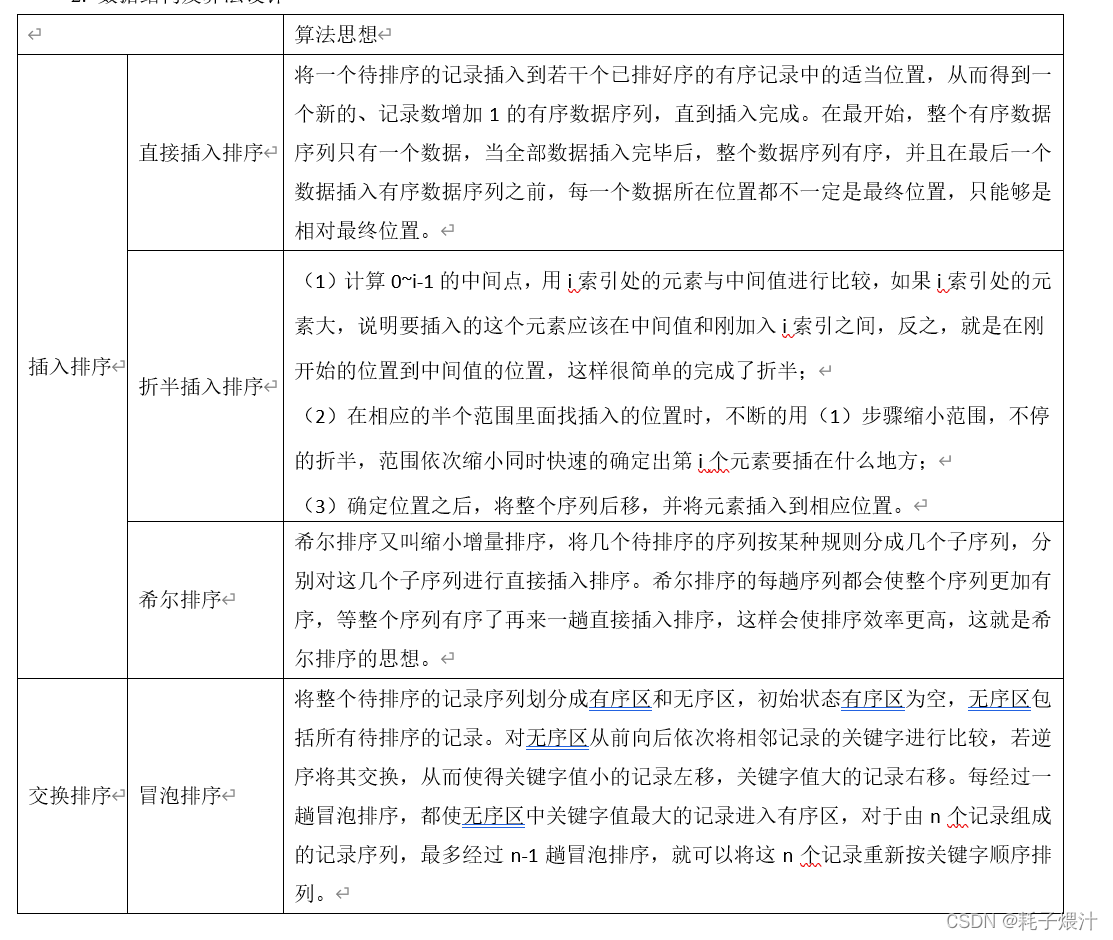

-
程序实现
-
测试
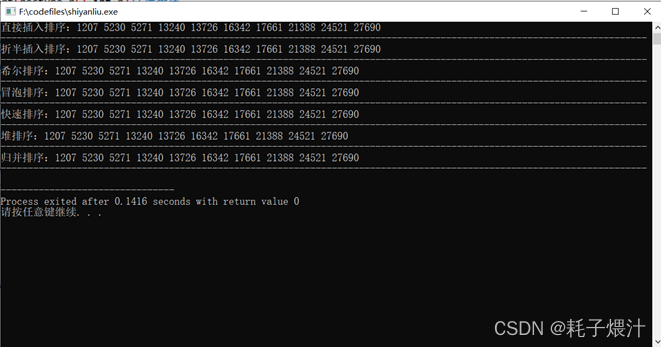
三、实验内容2
-
问题描述
对直接插入排序、折半插入排序、希尔排序、冒泡排序、快速排序、堆排序、归并排序进行性能比较; -
数据结构及算法设计
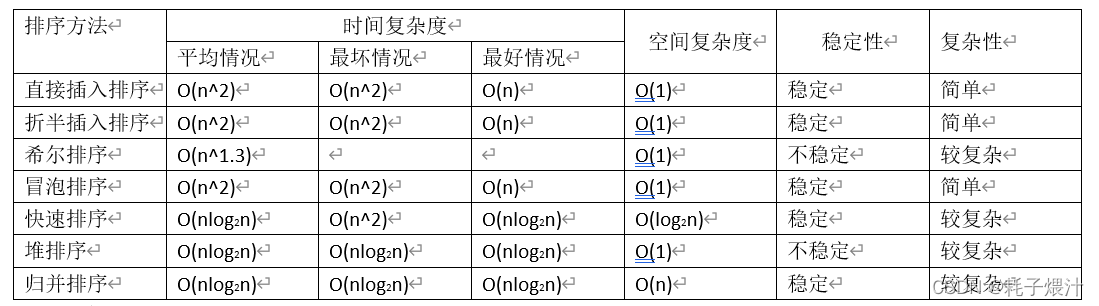
运用clock函数计算各类排序花费的时间
clock_t为CPU时钟计时单元数
clock()函数返回此时CPU时钟计时单元数
分别计算排序前(start)CPU时钟计时单元数和排序后(finish)的CPU时钟计时单元数
finish与start的差值即为程序运行花费的CPU时钟单元数量,再除每秒CPU有多少个时钟单元,即为程序耗时 -
程序实现
-
测试
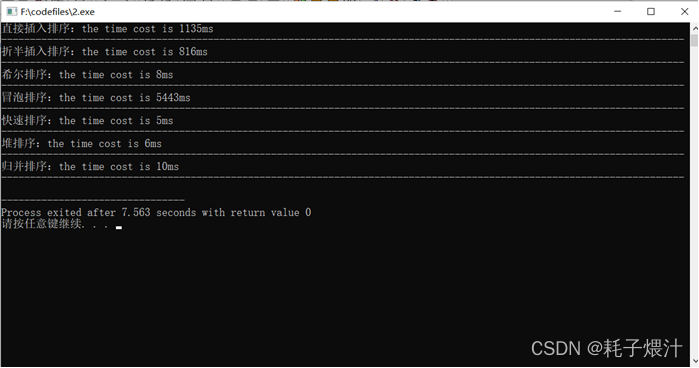
总结
通过本次实验,我加深了对各类排序算法的理解。因为不同的排序方法适应不同的应用环境和要求,所以选择合适的排序方法应综合考虑下列因素:①待排序的记录数目n;
(1)若n较小(如n≤50),可采用直接插入或直接选择排序。
(2)若文件初始状态基本有序(指正序),则应选用直接插人、冒泡或随机的快速排序为宜;
(3)若n较大,则应采用时间复杂度为O(nlgn)的排序方法:快速排序、堆排序或归并排序。
②记录的大小(规模);③关键字的结构及其初始状态;④对稳定性的要求;⑤语言工具的条件;⑥存储结构;⑦时间和辅助空间复杂度等。
排序是数据结构中重要的一部分,所以必须理解学会以及熟练的运用各种不同的排序算法。
源代码
https://download.youkuaiyun.com/download/weixin_51273415/60989488


















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











