






花书本将正则化定义为减少泛化误差而不是训练误差
约束和惩罚
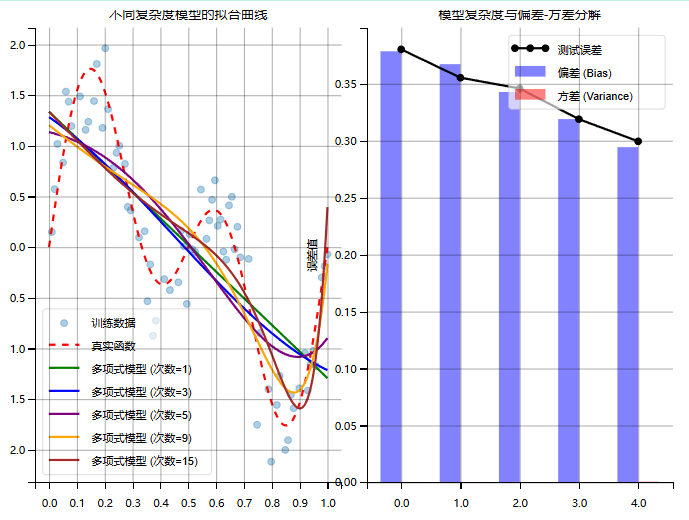
估计的正则化以偏差的增加换取方差的减少

训练的数据分布和真实的数据分布一定是有偏差的
对训练中权重的扰动
高方差与机器学习中的分布
为什么过拟合是高方差问题?
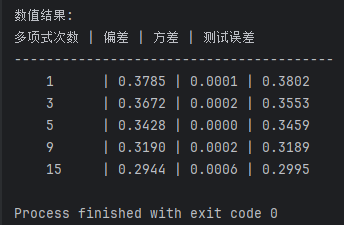
在机器学习中,预测误差可以分解为三个部分:
- 偏差(Bias):模型预测的系统性偏离,表示模型假设与真实情况的差距
- 方差(Variance):模型预测在不同训练数据下的波动程度
- 不可约误差:数据本身的随机性造成的误差
过拟合被称为高方差问题,因为:
- 高敏感性:过拟合的模型对训练数据的微小变化极为敏感
- 不稳定预测:如果用略微不同的训练集重新训练模型,预测结果会有很大差异
- 过度自由度:模型参数过多,能够"记忆"训练数据中的随机噪声
比喻:射击靶心多次:
- 低偏差高方差:弹着点分散在靶子周围,平均位置接近靶心,但每次都差别很大(过拟合)
- 高偏差低方差:弹着点集中在一个区域,但这个区域偏离靶心(欠拟合)
- 低偏差低方差:弹着点集中在靶心周围(理想模型)
所有模型都是学习一个分布吗?
从本质上讲,是的。所有监督学习模型都在尝试学习数据的条件分布 P(Y|X),即给定输入X,输出Y的概率分布:
- 回归模型:通常学习条件期望 E[Y|X](分布的均值)
- 分类模型:学习条件概率 P(Y=类别|X)
- 概率模型:直接建模完整的条件概率分布
正则化的有效性在于它改变了模型学习分布的方式,加入先验知识:
- 无正则化:纯粹从数据学习分布,容易过分信任噪声
- L2正则化:假设参数服从正态分布(多数参数应该较小)
- L1正则化:假设参数服从拉普拉斯分布(多数参数应该为零)
从数学角度理解过拟合与正则化
1. 偏差-方差分解
假设我们有真实函数 f ( x ) f(x) f(x) 和训练数据 D D D,基于 D D D训练的模型为 f ^ ( x ; D ) \hat{f}(x;D) f^(x;D)。对于任意输入 x x x,预测的期望平方误差可以分解为:
E [ ( y − f ^ ( x ; D ) ) 2 ] = Bias 2 + Variance + σ ϵ 2 E[(y - \hat{f}(x;D))^2] = \text{Bias}^2 + \text{Variance} + \sigma^2_\epsilon E[(y−f^(x;D))2]=Bias2+Variance+σϵ2
其中:
- Bias = E [ f ^ ( x ; D ) ] − f ( x ) \text{Bias} = E[\hat{f}(x;D)] - f(x) Bias=E[f^(x;D)]−f(x):模型预测的平均值与真实值的差距
- Variance = E [ ( f ^ ( x ; D ) − E [ f ^ ( x ; D ) ] ) 2 ] \text{Variance} = E[(\hat{f}(x;D) - E[\hat{f}(x;D)])^2] Variance=E[(f^(x;D)−E[f^(x;D)])2]:模型预测在不同训练集上的波动程度
- σ ϵ 2 \sigma^2_\epsilon σϵ2:不可约误差(数据固有噪声)
过拟合的模型有高方差是因为:预测对训练数据的微小变化极为敏感,数学上表现为方差项过大。
2. 线性回归的过拟合
考虑线性模型 y = X β + ϵ y = X\beta + \epsilon y=Xβ+ϵ,使用最小二乘法估计参数:
β ^ O L S = ( X T X ) − 1 X T y \hat{\beta}_{OLS} = (X^TX)^{-1}X^Ty β^OLS=(XTX)−1XTy
当特征数量接近或超过样本数量时, X T X X^TX XTX 接近奇异矩阵,导致:
- 参数估计的方差极大: Var ( β ^ O L S ) = σ 2 ( X T X ) − 1 \text{Var}(\hat{\beta}_{OLS}) = \sigma^2(X^TX)^{-1} Var(β^OLS)=σ2(XTX)−1
- 矩阵的条件数很大,小的数据扰动会导致系数的巨大变化
3. 正则化的数学形式与效果
L2正则化 (Ridge)
添加L2惩罚后的目标函数:
min β ∣ y − X β ∣ 2 2 + λ ∣ β ∣ 2 2 \min_{\beta} |y - X\beta|^2_2 + \lambda|\beta|^2_2 βmin∣y−Xβ∣22+λ∣β∣22
闭式解为:
β ^ r i d g e = ( X T X + λ I ) − 1 X T y \hat{\beta}_{ridge} = (X^TX + \lambda I)^{-1}X^Ty β^ridge=(XTX+λI)−1XTy
从数学上看,这相当于在矩阵 X T X X^TX XTX 的对角线上添加常数 λ \lambda λ,改善了矩阵的条件数,减小了参数估计的方差:
Var ( β ^ r i d g e ) = σ 2 ( X T X + λ I ) − 1 X T X ( X T X + λ I ) − 1 < σ 2 ( X T X ) − 1 \text{Var}(\hat{\beta}_{ridge}) = \sigma^2(X^TX + \lambda I)^{-1}X^TX(X^TX + \lambda I)^{-1} < \sigma^2(X^TX)^{-1} Var(β^ridge)=σ2(XTX+λI)−1XTX(XTX+λI)−1<σ2(XTX)−1
L1正则化 (Lasso)
min β ∣ y − X β ∣ 2 2 + λ ∣ β ∣ 1 \min_{\beta} |y - X\beta|^2_2 + \lambda|\beta|_1 βmin∣y−Xβ∣22+λ∣β∣1
L1正则化没有闭式解,但可以证明,当 λ \lambda λ 足够大时,解的某些分量严格为零。
4. 贝叶斯视角下的数学解释
从贝叶斯角度看,正则化等价于对参数引入先验分布:
- 无正则化:对应最大似然估计 P ( θ ∣ D ) ∝ P ( D ∣ θ ) P(\theta|D) \propto P(D|\theta) P(θ∣D)∝P(D∣θ)
- L2正则化:对应高斯先验
P
(
θ
)
∝
exp
(
−
λ
2
∣
θ
∣
2
2
)
P(\theta) \propto \exp(-\frac{\lambda}{2}|\theta|^2_2)
P(θ)∝exp(−2λ∣θ∣22)
- 后验分布: P ( θ ∣ D ) ∝ P ( D ∣ θ ) P ( θ ) P(\theta|D) \propto P(D|\theta)P(\theta) P(θ∣D)∝P(D∣θ)P(θ)
- MAP估计: θ ^ M A P = arg max θ log P ( D ∣ θ ) − λ 2 ∣ θ ∣ 2 2 \hat{\theta}_{MAP} = \arg\max_{\theta} \log P(D|\theta) - \frac{\lambda}{2}|\theta|^2_2 θ^MAP=argθmaxlogP(D∣θ)−2λ∣θ∣22
- L1正则化:对应拉普拉斯先验
P
(
θ
)
∝
exp
(
−
λ
∣
θ
∣
1
)
P(\theta) \propto \exp(-\lambda|\theta|_1)
P(θ)∝exp(−λ∣θ∣1)
- MAP估计: θ ^ M A P = arg max θ log P ( D ∣ θ ) − λ ∣ θ ∣ 1 \hat{\theta}_{MAP} = \arg\max_{\theta} \log P(D|\theta) - \lambda|\theta|_1 θ^MAP=argθmaxlogP(D∣θ)−λ∣θ∣1
5. 几何解释
在参数空间中,L2正则化的约束区域是球形( ∣ β ∣ 2 ≤ t |\beta|_2 \leq t ∣β∣2≤t),而L1正则化的约束区域是菱形( ∣ β ∣ 1 ≤ t |\beta|_1 \leq t ∣β∣1≤t)。
在优化过程中,目标函数的等高线与约束区域相切于解点:
- L2约束:球形与等高线相切,倾向于产生较小但非零的系数
- L1约束:菱形与等高线相切常发生在菱形的角上,对应某些参数正好为零
6. 渐近分析
假设数据生成过程为 y = X β ∗ + ϵ y = X\beta^* + \epsilon y=Xβ∗+ϵ,且样本数量 n → ∞ n \rightarrow \infty n→∞:
- 无正则化: β ^ O L S → P β ∗ \hat{\beta}_{OLS} \xrightarrow{P} \beta^* β^OLSPβ∗(一致性估计)
- L2正则化: β ^ r i d g e → P β r i d g e ∗ ≠ β ∗ \hat{\beta}_{ridge} \xrightarrow{P} \beta^*_{ridge} \neq \beta^* β^ridgePβridge∗=β∗(产生有偏估计)
- L1正则化:在稀疏性假设下, β ^ l a s s o \hat{\beta}_{lasso} β^lasso 可以保持一致性,同时实现变量选择
神经网络中的正则化:数学视角
1. 神经网络的过拟合问题
神经网络特别容易过拟合,因为:
- 参数空间极大:典型CNN可能有数百万参数,远超训练样本数
- 表达能力极强:有足够神经元的网络理论上可以拟合任意函数
- 优化难度大:损失函数非凸,容易陷入过拟合的局部最小值
在数学上,一个L层神经网络可表示为嵌套函数:
f ( x ; θ ) = f L ( f L − 1 ( . . . f 1 ( x ; θ 1 ) . . . ; θ L − 1 ) ; θ L ) f(x; \theta) = f_L(f_{L-1}(...f_1(x; \theta_1)...; \theta_{L-1}); \theta_L) f(x;θ)=fL(fL−1(...f1(x;θ1)...;θL−1);θL)
其中 θ = θ 1 , θ 2 , . . . , θ L \theta = {\theta_1, \theta_2, ..., \theta_L} θ=θ1,θ2,...,θL 包含所有权重和偏置。
2. 神经网络的经典正则化方法
权重正则化 (Weight Regularization)
L r e g = L o r i g i n a l + λ ∑ l = 1 L Ω ( θ l ) L_{reg} = L_{original} + \lambda \sum_{l=1}^L \Omega(\theta_l) Lreg=Loriginal+λl=1∑LΩ(θl)
其中:
- L2正则化(Weight Decay): Ω ( θ l ) = ∣ θ l ∣ 2 2 \Omega(\theta_l) = |\theta_l|_2^2 Ω(θl)=∣θl∣22
- L1正则化: Ω ( θ l ) = ∣ θ l ∣ 1 \Omega(\theta_l) = |\theta_l|_1 Ω(θl)=∣θl∣1
Dropout
数学表示为在训练时对每层输出随机置零:
y ~ ( l ) = r ( l ) ⊙ y ( l ) \tilde{y}^{(l)} = r^{(l)} \odot y^{(l)} y~(l)=r(l)⊙y(l)
其中 r ( l ) ∼ Bernoulli ( p ) r^{(l)} \sim \text{Bernoulli}(p) r(l)∼Bernoulli(p) 是二元随机变量向量, ⊙ \odot ⊙ 表示元素乘积。
在测试时,通过缩放保持期望一致: y ^ ( l ) = p y ( l ) \hat{y}^{(l)} = py^{(l)} y^(l)=py(l)
批量归一化 (Batch Normalization)
对每一层的输出进行标准化:
z ^ ( l ) = z ( l ) − μ B σ B 2 + ϵ \hat{z}^{(l)} = \frac{z^{(l)} - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}} z^(l)=σB2+ϵz(l)−μB
y ( l ) = γ z ^ ( l ) + β y^{(l)} = \gamma\hat{z}^{(l)} + \beta y(l)=γz^(l)+β
其中 μ B \mu_B μB 和 σ B 2 \sigma_B^2 σB2 是当前mini-batch的均值和方差, γ \gamma γ 和 β \beta β 是可学习参数。
3. 高级正则化技术
早停法 (Early Stopping)
θ ∗ = θ t where t = arg min t L v a l ( θ t ) \theta^* = \theta_t \text{ where } t = \arg\min_t L_{val}(\theta_t) θ∗=θt where t=argtminLval(θt)
数据增强 (Data Augmentation)
L a u g = E x ∼ D , T ∼ T [ L ( f ( T ( x ) ; θ ) , y ) ] L_{aug} = \mathbb{E}_{x \sim D, T \sim \mathcal{T}}[L(f(T(x); \theta), y)] Laug=Ex∼D,T∼T[L(f(T(x);θ),y)]
对抗训练 (Adversarial Training)
min θ E ( x , y ) ∼ D [ max ∣ δ ∣ p ≤ ϵ L ( f ( x + δ ; θ ) , y ) ] \min_\theta \mathbb{E}_{(x,y) \sim D}[\max_{|\delta|_p \leq \epsilon} L(f(x+\delta; \theta), y)] θminE(x,y)∼D[∣δ∣p≤ϵmaxL(f(x+δ;θ),y)]
4. 正则化的统一数学视角
在神经网络中,所有正则化方法都可以视为对以下目标的优化:
min θ E ( x , y ) ∼ D t r a i n [ L ( f ( x ; θ ) , y ) ] + λ ⋅ 复杂度 ( θ ) \min_\theta \mathbb{E}_{(x,y) \sim D_{train}}[L(f(x; \theta), y)] + \lambda \cdot \text{复杂度}(\theta) θminE(x,y)∼Dtrain[L(f(x;θ),y)]+λ⋅复杂度(θ)
不同之处在于如何定义复杂度:
- 参数范数:直接约束权重大小
- 函数平滑度:约束输出对输入的敏感度
- 随机扰动鲁棒性:约束模型对数据/参数的微小变化稳定性
5. 深度学习中特有的现象
神经网络与经典模型的一个重要区别是"双下降(Double Descent)"现象:
- 当模型复杂度超过某个阈值后,测试误差可能再次下降
- 过参数化(over-parameterization)模型在无正则化下也能泛化良好
这与参数空间的几何特性有关,SGD等优化算法倾向于找到平坦的最小值区域,具有隐式正则化效果。
L2正则化对神经网络梯度下降表达式的影响
下面我将对比加入L2正则化前后神经网络梯度下降表达式的区别,并用数学公式清晰地展示其差异。
1. 未加入L2正则化的梯度下降
在神经网络训练中,我们通常使用梯度下降法最小化损失函数 L ( θ ) \mathcal{L}(\theta) L(θ),其中 θ \theta θ 表示模型的参数(权重和偏置)。
对于一个包含 N N N 个样本的数据集,损失函数可以定义为:
L ( θ ) = 1 N ∑ i = 1 N ℓ ( f ( x i ; θ ) , y i ) \mathcal{L}(\theta) = \frac{1}{N} \sum_{i=1}^{N} \ell(f(x_i; \theta), y_i) L(θ)=N1i=1∑Nℓ(f(xi;θ),yi)
其中:
- N N N:数据样本数量
- f ( x i ; θ ) f(x_i; \theta) f(xi;θ):模型对输入 x i x_i xi 的预测
- y i y_i yi:实际标签
- ℓ \ell ℓ:单个样本的损失函数
在标准梯度下降中,参数 θ \theta θ 的更新规则为:
θ t + 1 = θ t − η ∇ θ L ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}(\theta_t) θt+1=θt−η∇θL(θt)
其中:
- η \eta η:学习率
- ∇ θ L ( θ t ) \nabla_\theta \mathcal{L}(\theta_t) ∇θL(θt):损失函数关于 θ \theta θ 的梯度
- t t t:当前迭代步
2. 加入L2正则化的梯度下降
L2正则化通过在损失函数中添加参数平方和的惩罚项来防止过拟合。带有L2正则化的损失函数定义为:
L reg ( θ ) = L ( θ ) + λ 2 ∣ θ ∣ 2 2 \mathcal{L}_{\text{reg}}(\theta) = \mathcal{L}(\theta) + \frac{\lambda}{2} | \theta |_2^2 Lreg(θ)=L(θ)+2λ∣θ∣22
其中:
- λ \lambda λ:正则化系数,控制正则化强度
- ∣ θ ∣ 2 2 = ∑ j θ j 2 | \theta |_2^2 = \sum_{j} \theta_j^2 ∣θ∣22=∑jθj2:参数的L2范数平方
计算新的损失函数 L reg ( θ ) \mathcal{L}_{\text{reg}}(\theta) Lreg(θ) 的梯度:
∇ θ L reg ( θ ) = ∇ θ ( L ( θ ) + λ 2 ∣ θ ∣ 2 2 ) \nabla_\theta \mathcal{L}_{\text{reg}}(\theta) = \nabla_\theta \left( \mathcal{L}(\theta) + \frac{\lambda}{2} | \theta |_2^2 \right) ∇θLreg(θ)=∇θ(L(θ)+2λ∣θ∣22)
利用梯度的线性性质:
∇ θ L reg ( θ ) = ∇ θ L ( θ ) + ∇ θ ( λ 2 ∣ θ ∣ 2 2 ) \nabla_\theta \mathcal{L}_{\text{reg}}(\theta) = \nabla_\theta \mathcal{L}(\theta) + \nabla_\theta \left( \frac{\lambda}{2} | \theta |_2^2 \right) ∇θLreg(θ)=∇θL(θ)+∇θ(2λ∣θ∣22)
计算正则化项的梯度:
∇ θ ( λ 2 ∣ θ ∣ 2 2 ) = ∇ θ ( λ 2 ∑ j θ j 2 ) = λ 2 ⋅ 2 θ = λ θ \nabla_\theta \left( \frac{\lambda}{2} | \theta |_2^2 \right) = \nabla_\theta \left( \frac{\lambda}{2} \sum_{j} \theta_j^2 \right) = \frac{\lambda}{2} \cdot 2 \theta = \lambda \theta ∇θ(2λ∣θ∣22)=∇θ(2λj∑θj2)=2λ⋅2θ=λθ
因此,总梯度为:
∇ θ L reg ( θ ) = ∇ θ L ( θ ) + λ θ \nabla_\theta \mathcal{L}_{\text{reg}}(\theta) = \nabla_\theta \mathcal{L}(\theta) + \lambda \theta ∇θLreg(θ)=∇θL(θ)+λθ
代入梯度下降的更新公式:
θ t + 1 = θ t − η ∇ θ L reg ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}_{\text{reg}}(\theta_t) θt+1=θt−η∇θLreg(θt) θ t + 1 = θ t − η ( ∇ θ L ( θ t ) + λ θ t ) \theta_{t+1} = \theta_t - \eta \left( \nabla_\theta \mathcal{L}(\theta_t) + \lambda \theta_t \right) θt+1=θt−η(∇θL(θt)+λθt)
整理得到:
θ t + 1 = θ t − η ∇ θ L ( θ t ) − η λ θ t \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}(\theta_t) - \eta \lambda \theta_t θt+1=θt−η∇θL(θt)−ηλθt θ t + 1 = ( 1 − η λ ) θ t − η ∇ θ L ( θ t ) \theta_{t+1} = (1 - \eta \lambda) \theta_t - \eta \nabla_\theta \mathcal{L}(\theta_t) θt+1=(1−ηλ)θt−η∇θL(θt)
3. 两种情况的对比
未加入L2正则化:
θ t + 1 = θ t − η ∇ θ L ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}(\theta_t) θt+1=θt−η∇θL(θt)
加入L2正则化:
θ t + 1 = ( 1 − η λ ) θ t − η ∇ θ L ( θ t ) \theta_{t+1} = (1 - \eta \lambda) \theta_t - \eta \nabla_\theta \mathcal{L}(\theta_t) θt+1=(1−ηλ)θt−η∇θL(θt)
关键区别
-
权重衰减项:加入L2正则化后,参数 θ t \theta_t θt 在每一步更新时乘以系数 ( 1 − η λ ) (1 - \eta \lambda) (1−ηλ),这个系数小于1,因此对参数施加了衰减效应。
-
参数约束:衰减项 − η λ θ t -\eta \lambda \theta_t −ηλθt 与参数大小成正比,参数越大,受到的惩罚越大,这有效限制了模型复杂度,防止过拟合。
- 在实际应用中,L2正则化通常只应用于权重参数,而不用于偏置项
- 正则化系数 λ \lambda λ 是一个超参数,需要通过交叉验证等方法选择适当的值
- 常见的 λ \lambda λ 值范围在 0.0001 到 0.1 之间
L1正则化在神经网络梯度下降中的影响
1. 未加入正则化的梯度下降
在神经网络训练中,未加入正则化时,我们的目标是最小化损失函数 L ( θ ) \mathcal{L}(\theta) L(θ),其中 θ \theta θ 表示模型的参数(权重和偏置)。
对于一个包含 N N N 个样本的数据集,损失函数可以定义为:
L ( θ ) = 1 N ∑ i = 1 N ℓ ( f ( x i ; θ ) , y i ) \mathcal{L}(\theta) = \frac{1}{N} \sum_{i=1}^{N} \ell(f(x_i; \theta), y_i) L(θ)=N1i=1∑Nℓ(f(xi;θ),yi)
其中:
- N N N:数据样本数量
- f ( x i ; θ ) f(x_i; \theta) f(xi;θ):模型对输入 x i x_i xi 的预测
- y i y_i yi:实际标签
- ℓ \ell ℓ:单个样本的损失函数
在标准梯度下降中,参数 θ \theta θ 的更新规则为:
θ t + 1 = θ t − η ∇ θ L ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}(\theta_t) θt+1=θt−η∇θL(θt)
其中:
- η \eta η:学习率
- ∇ θ L ( θ t ) \nabla_\theta \mathcal{L}(\theta_t) ∇θL(θt):损失函数关于 θ \theta θ 的梯度
- t t t:当前迭代步
2. 加入L1正则化的梯度下降
L1正则化通过在损失函数中添加参数绝对值之和的惩罚项来防止过拟合并促进模型稀疏性。带有L1正则化的损失函数定义为:
L reg ( θ ) = L ( θ ) + λ ∣ θ ∣ 1 \mathcal{L}_{\text{reg}}(\theta) = \mathcal{L}(\theta) + \lambda | \theta |_1 Lreg(θ)=L(θ)+λ∣θ∣1
其中:
- λ \lambda λ:正则化系数,控制正则化强度
- ∣ θ ∣ 1 = ∑ j ∣ θ j ∣ | \theta |_1 = \sum_{j} |\theta_j| ∣θ∣1=∑j∣θj∣:参数的L1范数(绝对值之和)
计算新的损失函数 L reg ( θ ) \mathcal{L}_{\text{reg}}(\theta) Lreg(θ) 的梯度:
∇ θ L reg ( θ ) = ∇ θ L ( θ ) + λ ∇ θ ∣ θ ∣ 1 \nabla_\theta \mathcal{L}_{\text{reg}}(\theta) = \nabla_\theta \mathcal{L}(\theta) + \lambda \nabla_\theta | \theta |_1 ∇θLreg(θ)=∇θL(θ)+λ∇θ∣θ∣1
L1范数在 θ j = 0 \theta_j = 0 θj=0 处不可导,需要使用次梯度(subgradient)来处理。L1范数的次梯度为:
∇ θ ∣ θ ∣ 1 = sign ( θ ) \nabla_\theta | \theta |_1 = \text{sign}(\theta) ∇θ∣θ∣1=sign(θ)
其中, sign ( θ ) \text{sign}(\theta) sign(θ) 是一个向量,每个分量定义为:
sign ( θ j ) = { 1 if θ j > 0 0 if θ j = 0 − 1 if θ j < 0 \text{sign}(\theta_j) = \begin{cases} 1 & \text{if } \theta_j > 0 \ 0 & \text{if } \theta_j = 0 \ -1 & \text{if } \theta_j < 0 \end{cases} sign(θj)={1if θj>0 0if θj=0 −1if θj<0
因此,总梯度为:
∇ θ L reg ( θ ) = ∇ θ L ( θ ) + λ ⋅ sign ( θ ) \nabla_\theta \mathcal{L}_{\text{reg}}(\theta) = \nabla_\theta \mathcal{L}(\theta) + \lambda \cdot \text{sign}(\theta) ∇θLreg(θ)=∇θL(θ)+λ⋅sign(θ)
代入梯度下降的更新公式:
θ t + 1 = θ t − η ∇ θ L reg ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}_{\text{reg}}(\theta_t) θt+1=θt−η∇θLreg(θt) θ t + 1 = θ t − η ( ∇ θ L ( θ t ) + λ ⋅ sign ( θ t ) ) \theta_{t+1} = \theta_t - \eta \left( \nabla_\theta \mathcal{L}(\theta_t) + \lambda \cdot \text{sign}(\theta_t) \right) θt+1=θt−η(∇θL(θt)+λ⋅sign(θt))
整理得到:
θ t + 1 = θ t − η ∇ θ L ( θ t ) − η λ ⋅ sign ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}(\theta_t) - \eta \lambda \cdot \text{sign}(\theta_t) θt+1=θt−η∇θL(θt)−ηλ⋅sign(θt)
3. 两种情况的对比
未加入L1正则化:
θ t + 1 = θ t − η ∇ θ L ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}(\theta_t) θt+1=θt−η∇θL(θt)
加入L1正则化:
θ t + 1 = θ t − η ∇ θ L ( θ t ) − η λ ⋅ sign ( θ t ) \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L}(\theta_t) - \eta \lambda \cdot \text{sign}(\theta_t) θt+1=θt−η∇θL(θt)−ηλ⋅sign(θt)
关键区别
- 固定惩罚项:L1正则化添加了一个与参数符号相关的固定惩罚项 − η λ ⋅ sign ( θ t ) -\eta \lambda \cdot \text{sign}(\theta_t) −ηλ⋅sign(θt)。这个惩罚项的大小为 η λ \eta \lambda ηλ,与参数的绝对值无关,仅依赖于其正负性。
- 稀疏性促进:由于惩罚项是固定的,L1正则化强烈倾向于将参数推向0,特别是当参数较小时。这使得L1正则化在特征选择和模型稀疏化方面非常有效。
- 次梯度处理:L1范数在0处不可导,需要使用次梯度方法处理,这在实现上比L2正则化更复杂。
直观理解
L1正则化对参数施加了"剪切"效应:
- 对于正参数:减去固定值 η λ \eta \lambda ηλ,使其减小
- 对于负参数:加上固定值 η λ \eta \lambda ηλ,使其增大
- 当参数接近0时,固定惩罚可能将其直接推至0
例如,假设 η = 0.01 \eta = 0.01 η=0.01, λ = 0.1 \lambda = 0.1 λ=0.1:
- 若 θ t = 0.005 \theta_t = 0.005 θt=0.005,更新后 θ t + 1 = 0.004 − η ∇ θ L ( θ t ) \theta_{t+1} = 0.004 - \eta \nabla_\theta \mathcal{L}(\theta_t) θt+1=0.004−η∇θL(θt)(不考虑梯度项)
- 若 θ t = 0.0005 \theta_t = 0.0005 θt=0.0005,更新后可能变为负值,但实践中通常会截断为0
L1正则化的主要优势
- 产生稀疏解:许多参数被精确地置为0,自动实现特征选择
- 模型简化:减少非零参数数量,降低计算复杂度
- 抗噪能力:忽略不重要的特征,提高模型对噪声的鲁棒性
实践应用注意事项
- L1正则化通常只应用于权重参数,而不用于偏置项
- 正则化系数 λ \lambda λ 是重要的超参数,需要通过交叉验证等方法选择适当的值
- 在参数接近0时,可能需要特殊处理以避免数值不稳定性
L1正则化通过促进参数稀疏性,在优化损失的同时实现了模型简化和自动特征选择,这是其在神经网络训练中的独特价值。
基本矩阵形式问题
假设我们有一个线性回归问题,用矩阵表示为:
y = X w y = Xw y=Xw
其中: y = [ 10 8 15 − 6 4 ] ∈ R 5 , X = [ 2 1 3 0 1 0 2 − 1 3 2 0 1 − 1 1 − 2 0 2 − 1 1 2 ] ∈ R 5 × 4 , w = [ w 1 w 2 w 3 w 4 ] ∈ R 4 y = \begin{bmatrix} 10 \ 8 \ 15 \ -6 \ 4 \end{bmatrix} \in \mathbb{R}^5, \quad X = \begin{bmatrix} 2 & 1 & 3 & 0 \ 1 & 0 & 2 & -1 \ 3 & 2 & 0 & 1 \ -1 & 1 & -2 & 0 \ 2 & -1 & 1 & 2 \end{bmatrix} \in \mathbb{R}^{5 \times 4}, \quad w = \begin{bmatrix} w_1 \ w_2 \ w_3 \ w_4 \end{bmatrix} \in \mathbb{R}^4 y=[10 8 15 −6 4]∈R5,X=[2130 102−1 3201 −11−20 2−112]∈R5×4,w=[w1 w2 w3 w4]∈R4
1. 无正则化的梯度下降
标准损失函数为均方误差: L ( w ) = ∣ y − X w ∣ 2 2 \mathcal{L}(w) = |y - Xw|^2_2 L(w)=∣y−Xw∣22
梯度计算: ∇ w L ( w ) = − 2 X T ( y − X w ) \nabla_w \mathcal{L}(w) = -2X^T(y - Xw) ∇wL(w)=−2XT(y−Xw)
更新方程: w t + 1 = w t − η ∇ w L ( w t ) = w t + 2 η X T ( y − X w t ) w_{t+1} = w_t - \eta \nabla_w \mathcal{L}(w_t) = w_t + 2\eta X^T(y - Xw_t) wt+1=wt−η∇wL(wt)=wt+2ηXT(y−Xwt)
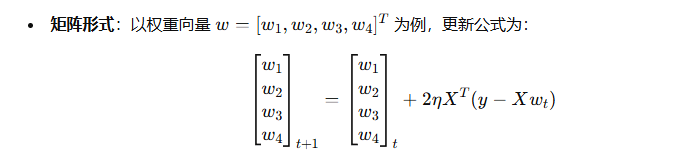
2. L2正则化的梯度下降
L2正则化损失函数: L L 2 ( w ) = ∣ y − X w ∣ 2 2 + λ ∣ w ∣ 2 2 \mathcal{L}_{L2}(w) = |y - Xw|^2_2 + \lambda|w|^2_2 LL2(w)=∣y−Xw∣22+λ∣w∣22
梯度计算: ∇ w L L 2 ( w ) = − 2 X T ( y − X w ) + 2 λ w \nabla_w \mathcal{L}_{L2}(w) = -2X^T(y - Xw) + 2\lambda w ∇wLL2(w)=−2XT(y−Xw)+2λw
更新方程: w t + 1 = w t − η ∇ w L L 2 ( w t ) = w t + 2 η X T ( y − X w t ) − 2 η λ w t w_{t+1} = w_t - \eta \nabla_w \mathcal{L}_{L2}(w_t) = w_t + 2\eta X^T(y - Xw_t) - 2\eta\lambda w_t wt+1=wt−η∇wLL2(wt)=wt+2ηXT(y−Xwt)−2ηλwt w t + 1 = ( 1 − 2 η λ ) w t + 2 η X T ( y − X w t ) w_{t+1} = (1-2\eta\lambda)w_t + 2\eta X^T(y - Xw_t) wt+1=(1−2ηλ)wt+2ηXT(y−Xwt)
矩阵形式: [ w 1 w 2 w 3 w 4 ] t + 1 = ( 1 − 2 η λ ) [ w 1 w 2 w 3 w 4 ] t + 2 η [ 2 1 3 − 1 2 1 0 2 1 − 1 3 2 0 − 2 1 0 − 1 1 0 2 ] ( [ 10 8 15 − 6 4 ] − [ 2 1 3 0 1 0 2 − 1 3 2 0 1 − 1 1 − 2 0 2 − 1 1 2 ] [ w 1 w 2 w 3 w 4 ] t ) \begin{bmatrix} w_1 \ w_2 \ w_3 \ w_4 \end{bmatrix}_{t+1} = (1-2\eta\lambda)\begin{bmatrix} w_1 \ w_2 \ w_3 \ w_4 \end{bmatrix}_{t} + 2\eta \begin{bmatrix} 2 & 1 & 3 & -1 & 2 \ 1 & 0 & 2 & 1 & -1 \ 3 & 2 & 0 & -2 & 1 \ 0 & -1 & 1 & 0 & 2 \end{bmatrix} \left( \begin{bmatrix} 10 \ 8 \ 15 \ -6 \ 4 \end{bmatrix} - \begin{bmatrix} 2 & 1 & 3 & 0 \ 1 & 0 & 2 & -1 \ 3 & 2 & 0 & 1 \ -1 & 1 & -2 & 0 \ 2 & -1 & 1 & 2 \end{bmatrix} \begin{bmatrix} w_1 \ w_2 \ w_3 \ w_4 \end{bmatrix}_{t} \right) [w1 w2 w3 w4]t+1=(1−2ηλ)[w1 w2 w3 w4]t+2η[213−12 1021−1 320−21 0−1102]([10 8 15 −6 4]−[2130 102−1 3201 −11−20 2−112][w1 w2 w3 w4]t)
3. L1正则化的梯度下降
L1正则化损失函数: L L 1 ( w ) = ∣ y − X w ∣ 2 2 + λ ∣ w ∣ 1 \mathcal{L}_{L1}(w) = |y - Xw|^2_2 + \lambda|w|_1 LL1(w)=∣y−Xw∣22+λ∣w∣1
梯度计算: ∇ w L L 1 ( w ) = − 2 X T ( y − X w ) + λ ⋅ sign ( w ) \nabla_w \mathcal{L}_{L1}(w) = -2X^T(y - Xw) + \lambda \cdot \text{sign}(w) ∇wLL1(w)=−2XT(y−Xw)+λ⋅sign(w)
更新方程: w t + 1 = w t − η ∇ w L L 1 ( w t ) = w t + 2 η X T ( y − X w t ) − η λ ⋅ sign ( w t ) w_{t+1} = w_t - \eta \nabla_w \mathcal{L}_{L1}(w_t) = w_t + 2\eta X^T(y - Xw_t) - \eta\lambda \cdot \text{sign}(w_t) wt+1=wt−η∇wLL1(wt)=wt+2ηXT(y−Xwt)−ηλ⋅sign(wt)
矩阵形式: [ w 1 w 2 w 3 w 4 ] t + 1 = [ w 1 w 2 w 3 w 4 ] t + 2 η [ 2 1 3 − 1 2 1 0 2 1 − 1 3 2 0 − 2 1 0 − 1 1 0 2 ] ( [ 10 8 15 − 6 4 ] − [ 2 1 3 0 1 0 2 − 1 3 2 0 1 − 1 1 − 2 0 2 − 1 1 2 ] [ w 1 w 2 w 3 w 4 ] t ) − η λ [ sign ( w 1 ) sign ( w 2 ) sign ( w 3 ) sign ( w 4 ) ] t \begin{bmatrix} w_1 \ w_2 \ w_3 \ w_4 \end{bmatrix}_{t+1} = \begin{bmatrix} w_1 \ w_2 \ w_3 \ w_4 \end{bmatrix}_{t} + 2\eta \begin{bmatrix} 2 & 1 & 3 & -1 & 2 \ 1 & 0 & 2 & 1 & -1 \ 3 & 2 & 0 & -2 & 1 \ 0 & -1 & 1 & 0 & 2 \end{bmatrix} \left( \begin{bmatrix} 10 \ 8 \ 15 \ -6 \ 4 \end{bmatrix} - \begin{bmatrix} 2 & 1 & 3 & 0 \ 1 & 0 & 2 & -1 \ 3 & 2 & 0 & 1 \ -1 & 1 & -2 & 0 \ 2 & -1 & 1 & 2 \end{bmatrix} \begin{bmatrix} w_1 \ w_2 \ w_3 \ w_4 \end{bmatrix}_{t} \right) - \eta\lambda \begin{bmatrix} \text{sign}(w_1) \ \text{sign}(w_2) \ \text{sign}(w_3) \ \text{sign}(w_4) \end{bmatrix}_{t} [w1 w2 w3 w4]t+1=[w1 w2 w3 w4]t+2η[213−12 1021−1 320−21 0−1102]([10 8 15 −6 4]−[2130 102−1 3201 −11−20 2−112][w1 w2 w3 w4]t)−ηλ[sign(w1) sign(w2) sign(w3) sign(w4)]t
关键区别对比
假设在某一迭代步,权重为 w t = [ 2.5 , − 1.2 , 0.8 , 0.05 ] T w_t = [2.5, -1.2, 0.8, 0.05]^T wt=[2.5,−1.2,0.8,0.05]T,学习率 η = 0.01 \eta = 0.01 η=0.01,正则化系数 λ = 0.1 \lambda = 0.1 λ=0.1:
L2正则化惩罚项:
$$-2\eta\lambda w_t = -2 \times 0.01 \times 0.1 \times \begin{bmatrix} 2.5 \ -1.2 \ 0.8 \ 0.05 \end{bmatrix}
\begin{bmatrix} -0.005 \ 0.0024 \ -0.0016 \ -0.0001 \end{bmatrix}$$
L1正则化惩罚项:
$$-\eta\lambda \cdot \text{sign}(w_t) = -0.01 \times 0.1 \times \begin{bmatrix} 1 \ -1 \ 1 \ 1 \end{bmatrix}
\begin{bmatrix} -0.001 \ 0.001 \ -0.001 \ -0.001 \end{bmatrix}$$
两种正则化的效果比较
-
L2正则化效果:
- 参数更新公式中包含因子 ( 1 − 2 η λ ) (1-2\eta\lambda) (1−2ηλ),相当于在每次迭代中对权重进行了比例缩减
- 惩罚大小与参数值成正比:参数越大,受到的惩罚越大
- 对于示例中的 w 1 = 2.5 w_1 = 2.5 w1=2.5,L2惩罚为 − 0.005 -0.005 −0.005,相对值为 0.005 / 2.5 = 0.2 0.005/2.5 = 0.2 0.005/2.5=0.2
- 对于示例中的 w 4 = 0.05 w_4 = 0.05 w4=0.05,L2惩罚为 − 0.0001 -0.0001 −0.0001,相对值为 0.0001 / 0.05 = 0.2 0.0001/0.05 = 0.2 0.0001/0.05=0.2
-
L1正则化效果:
- 施加固定大小的惩罚,方向与参数符号相反
- 对所有非零参数的惩罚绝对值相同:都是 η λ = 0.001 \eta\lambda = 0.001 ηλ=0.001
- 对于示例中的 w 1 = 2.5 w_1 = 2.5 w1=2.5,L1惩罚为 − 0.001 -0.001 −0.001,相对值为 0.001 / 2.5 = 0.04 0.001/2.5 = 0.04 0.001/2.5=0.04
- 对于示例中的 w 4 = 0.05 w_4 = 0.05 w4=0.05,L1惩罚为 − 0.001 -0.001 −0.001,相对值为 0.001 / 0.05 = 2 0.001/0.05 = 2 0.001/0.05=2


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









