




 本文介绍了一个使用大模型LLM(大型语言模型)根据自然语言生成SQL的简单Demo,讲解了从大模型概念、为什么选择LLM到系统架构和编码实战的全过程。通过结合后端技术与LLM,实现了将用户问题转化为执行SQL的功能,从而提升了系统的智能化水平。
本文介绍了一个使用大模型LLM(大型语言模型)根据自然语言生成SQL的简单Demo,讲解了从大模型概念、为什么选择LLM到系统架构和编码实战的全过程。通过结合后端技术与LLM,实现了将用户问题转化为执行SQL的功能,从而提升了系统的智能化水平。
文章目录
引言
本篇文章主要是关于实现一个类似Chat2DB的根据自然语言生成SQL的简单Demo,根据此Demo可以入门大模型应用开发,结合大模型开发出属于自己的大模型应用,让自己的应用智能化,可以根据用户不同问题做出不同的回答。
一、什么是大模型
如果各位有关注一些技术文章,难免会注意到这几年有一个词非常火,没错这就是“大模型”!
那大模型是什么?有什么用呢?
“大模型”是可以指任何规模较大、参数众多的机器学习模型,不仅限于自然语言处理(NLP),也可以包括计算机视觉、语音识别等其他领域的模型。大模型的特点是它们通常需要大量的数据来训练,以及相对较大的计算资源。
大模型的用途十分广泛,在很多领域都有不错的应用价值:
- 自然语言的生成和理解:大模型可以根据用户的问题生成连贯的文本回答、或是总结某些文章。ChatGPT就是一个不错的例子。
- 图像的处理:例如OpenAI的DALL·E模型,它可以根据用户问题,生成新的图像。
- 语言的识别和生成:大模型可以将文本信息转化为人类的语言。
- 推荐系统:大模型可以根据用户的行为或某些数据,推测用户的行为爱好,实现个性化推荐。
大模型的应用十分广泛,除了上面举的例子外,还有很多例子,这里就不一一举例了。

下面我会使用大模型的其中一种**大型语言模型(Large Language Model,简称LLM)**开发出一些简单的应用Demo,读者可以根据这样的思路进一步完善。
在此之前,先来介绍一下LLM是何物。LLM是指专门用来处理和理解自然语言的大型机器学习模型,LLM通常通过在大量文本数据上进行预训练来学习语言的结构和语义,从而能够执行各种语言处理任务,如文本生成、翻译、摘要、问答和情感分析等。
二、为什么选择LLM
LLM大模型是一款专注于理解和生成自然语言的大模型,那我们系统中无论是Redis还是MySQL的数据,都是文本形式的,将这些文本信息的数据交与大模型处理,能够有针对性地获取到我们想要的数据。
其次,LLM的使用成本较低,国内的大模型无论是讯飞星火大模型还是其他互联网厂商自研的大模型都为开发者提供了不少的免费Token,使得学习成本大大降低。
LLM大模型也是我们大部分人群目前接触最多的大模型,学习成本大幅度降低,只需要知道如何和大模型进行聊天即可懂得如何开发,不需要任何额外的学习成本。

三、开发技术说明
本文使用的大模型为讯飞星火大模型,但是咱们不限于任何厂商的大模型,有能力的ChatGPT也可以,作者只是觉得讯飞星火大模型送的Token比较多,非常适合初学者。
读者需要自行前往讯飞星火认知大模型-AI大语言模型-星火大模型-科大讯飞 (xfyun.cn)进行领取免费Token,领取教程这里就不多讲了,网上大把教程,不懂的可以下面留言。
其次,该教程后端方面需要懂得使用SpringBoot进行开发,也就是简单的一个接口开发,没有任何的前端。
最后,开发出来的Demo只是一个抛砖引玉的作用,开发过程中不会考虑太多的规范和其他一些限制,只是单纯把一个小功能实现,代码量也不多,一千行不到。
如果这些都准备好了,那么下面开始发车。
四、系统架构说明
本篇文章会带大家结合后端技术与讯飞星火大模型实现实现根据用户的自然语言问题生成SQL的工具。
自然语言生成SQL?是不是很熟悉,没错,这里是参考了阿里开源的Chat2DB数据库管理功能,不过这里是作者对这个功能自主实现的Demo,没有翻阅过Chat2DB源码,故这里的实现可能并不是Chat2DB的底层实现原理
怎么根据用户的自然语言描述生成用户想要的SQL呢?下面我们来分析分析
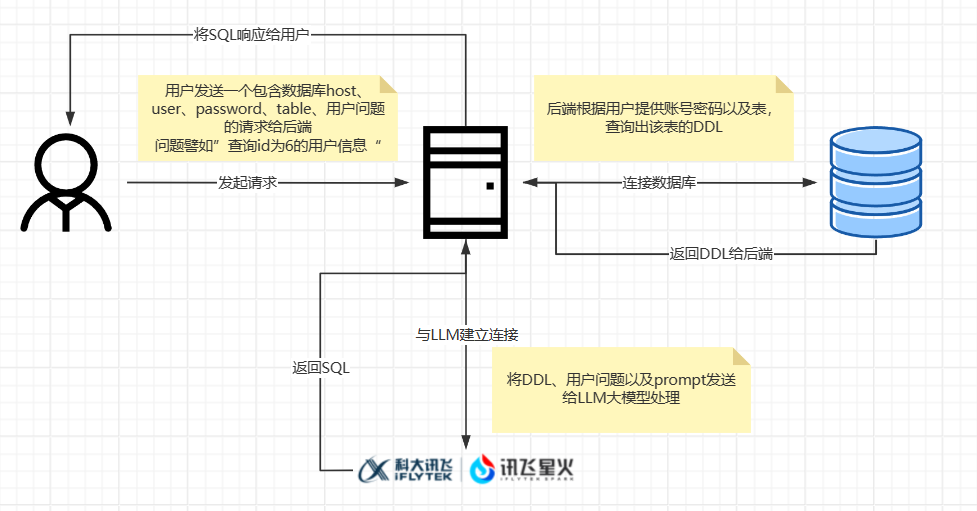
- 首先,用户发送一个包含数据库host、user、password、table、用户问题的请求给后端
- 后端根据用户提供的数据库信息,连接数据库查询出该表的DDL
- 后端与LLM建立连接,将DDL、用户问题、prompt发送给LLM
- LLM根据后端提供的数据以及问题,推测分析并生成SQL,将SQL返回给后端
- 后端将SQL返回响应给用户
也就是说,后端需要获取并整理数据,然后与LLM建立连接,将数据发送给LLM,LLM再根据数据做出回答,返回给后端SQL,这样就实现了自然语言生成SQL
五、编码实战
了解了整体架构是如何之后,我们进入了编码实战阶段,编码整体来说比较简单,重要的理解整体的架构
1. Maven
构建SpringBoot项目,引入一些我们需要的Maven依赖
<dependencies>
<!-- SpringBoot Web容器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-annotations -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.12.3</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--okhttp3-->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.fastjson2</groupId>
<artifactId>fastjson2</artifactId>
<version>2.0.43</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version> <!-- 根据你需要的版本进行调整 -->
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
2. 讯飞大模型配置类
为了方便维护,需要将讯飞星火大模型配置成一个类,方便日后维护
并根据接口文档的内容生成鉴权信息
星火认知大模型Web API文档 | 讯飞开放平台文档中心 (xfyun.cn)
@ConfigurationProperties("xun-fei.xing-huo")
@Component
@Data
public class XFLlmConfig {
private String appId;
private String domain;
private String wsUrl;
private String role;
private String host;
private String path;
private String apiSecret;
private String apiKey;
private Long maxResponseTime;
private String prompt;
public String getWsUrl() {
try {
String httpUrl = wsUrl.replaceAll("wss", "https");
Date date = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("EEE, dd MMM yyyy HH:mm:ss z", Locale.US);
sdf.setTimeZone(TimeZone.getTimeZone("GMT" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3142
3142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











