






1、分库分表是什么
分库:把一个库拆分成多个库
分表:把一个表拆分成多个表
2、为什么要分库分表
提高性能、提高可用性。
假设一个库支持1000个连接,QPS为3000,拆分成三个库分散连接压力。
随着单表的数据量变大,即使做了索引层面上的优化,还是存在性能瓶颈,就需要根据一定的规则分表。
如果就一个库,然后挂掉了,影响率就是100%,如果有两个库,其中一个挂掉了,那影响率就是50%。
3、怎么分库分表
不是所有情况都需要分库分表
数据库QPS过高连接数量不够,只分库不分表。
单表数据量太大,性能遇到瓶颈,只分表不分库。
连接数量不够,数据量大,分库加分表。
阿里巴巴的Java开发手册中说:单表行数超过500万行,或者单表容量超过2G,就推荐分库分表。
那我们是不是要非要等到超过500万行数据才分表,肯定并不能只看到当下,要预测未来的数据量,提前分库分表
4、分表策略
4.1、根据维度范围
假设这里有个订单表,我们根据order_id的范围,或者其它维度来进行分表。
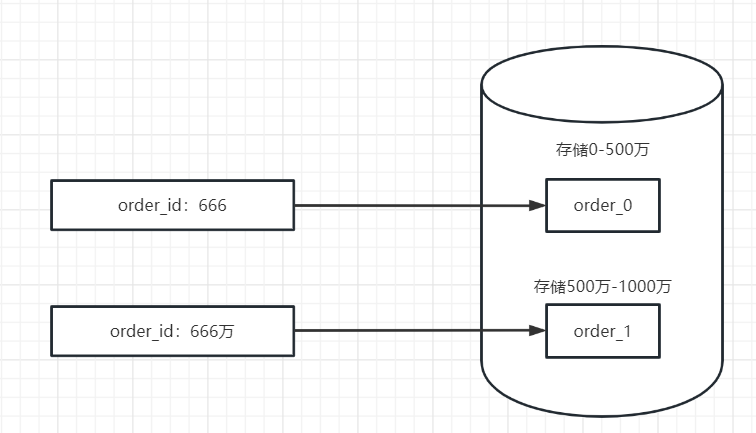
其它维度比如时间,但是不推荐,这个月双十一,那遇到的订单ID都在500万-1000万这样,就会造成热点问题,请求都打到order_1这个表上。
4.2、根据hash取模
假设这里有个订单表,我们根据order_id进行hash取模,然后将数据保存到对应的表。
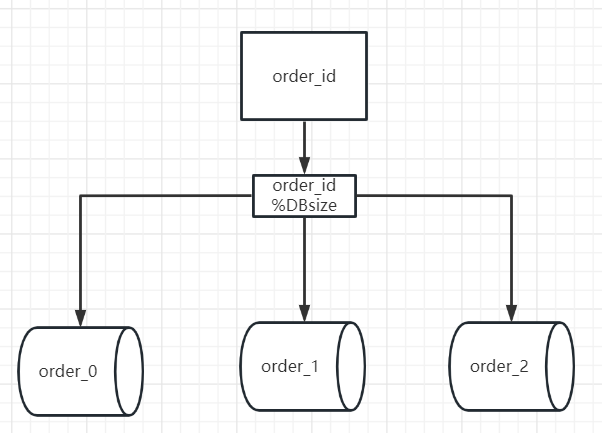
如果order_id为6,那6%3=0,就把该数据放到order_0表中。
如果order_id为7,那7%3=1,就把该数据放到order_1表中。
像hash取模就不会遇到明显的热点问题,但是扩容缩容就是个迁移问题了,所以一定要提前规划好,或者一致性hash
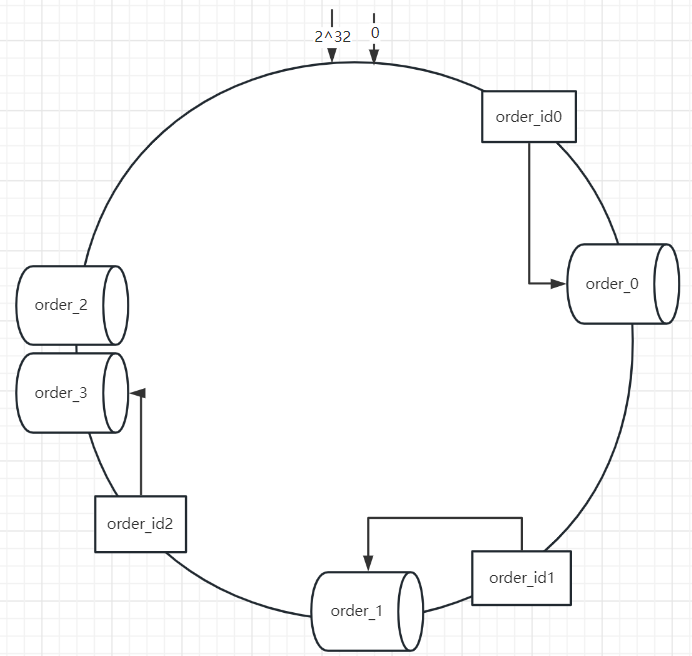
4.3、一致性hash
一致哈希算法也用了取模运算,哈希算法是对节点的数量进行取模运算,而一致哈希算法是对 2^32 进行取模运算,是一个固定的值。
把取模结果组织一个首尾相连的圆,这个圆叫哈希环。一致性hash将数据和存储节点都映射到环上。
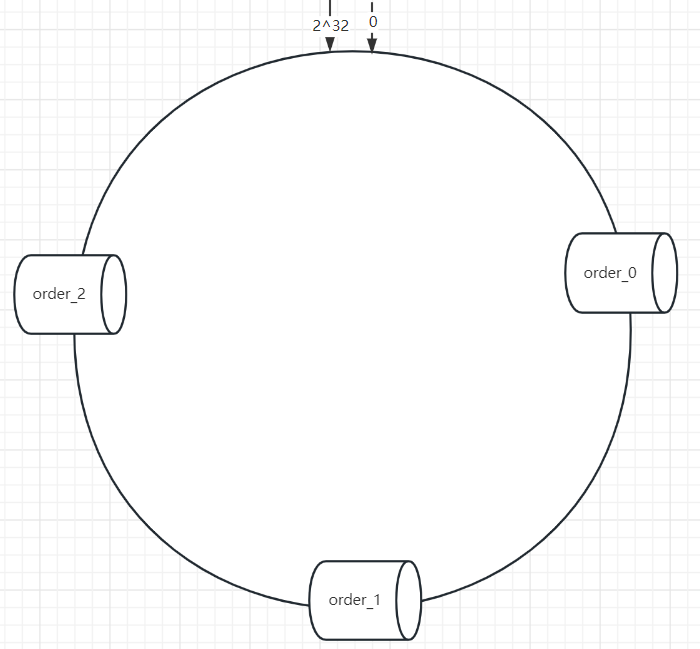
当我们要查找数据,要先进行取模获取到数据在环上的位置,接着顺时针走,碰到的第一个节点就是存储节点。
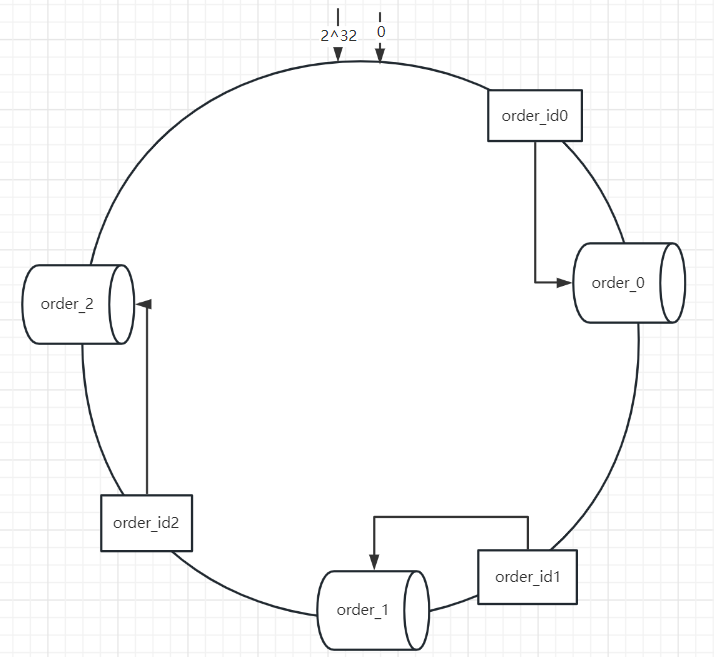
增加了一个节点,只需要对order_id2进行数据迁移就行。
5、垂直分表,垂直分库,水平分表,水平分库
垂直分表:以字段为依据,按照字段活跃,将字段拆分到不同的表。
垂直分库:以表为依据,根据业务,将不同的表拆分到不同的库。
水平分表:以字段为依据,根据一定的策略(hash…),把一个表的数据拆分到多个表。
水平分库:以表为依据,根据一定的策略(hash…),把一个库的数据拆分到多个库。

















 1507
1507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









