






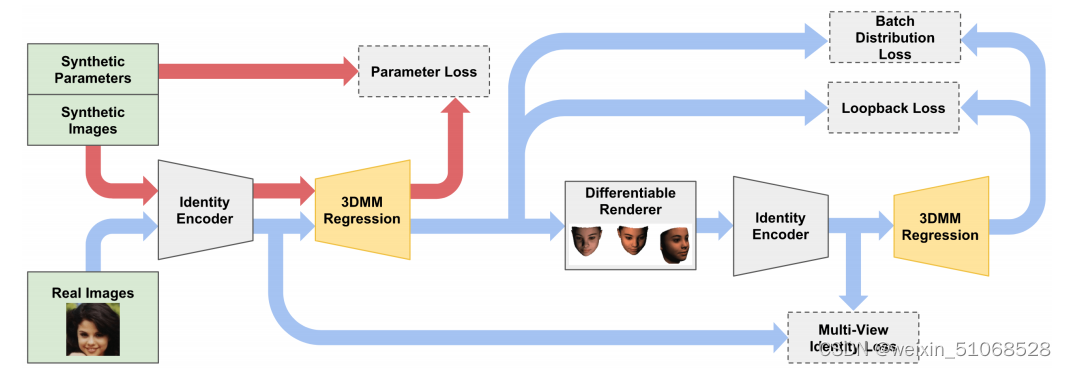
这篇文章描述的模型是一个用于从图像像素到3D可变形模型坐标的回归网络。这个网络采用了编码器-解码器架构,允许进行端到端的无监督学习,用于3D几何形状和纹理的可变形模型参数。
编码器部分
- 编码器使用:网络使用了FaceNet作为编码器,因为其特征已被证明在生成面部图像方面非常有效。
- 特征提取:编码器的输出是FaceNet架构中的1024维平均池化层的输出,这些输出然后用作解码器的输入。
解码器部分(解码功能是由标注为“3DMM Regression”的部分实现的,它接收来自身份编码器的特征输出,并生成用于3D建模的参数,然后这些参数被送入可微分渲染器以生成最终的面部图像)
- 解码器功能:解码器根据编码器输出的特征生成巴塞尔面部模型2017年版3DMM的参数。这包括形状和纹理网格的参数。
- 参数化:形状和纹理参数化为向量,通过应用PCA基和权重来调整这些向量,从而生成最终的3D面部模型。
- 训练和输出:解码器训练预测面部的398个形状和纹理向量参数。表情向量在当前模型中不进行预测,并设置为零。
损失函数(创新点,具体公式参考论文)
- 多种损失函数:为了训练这个网络,使用了多种损失函数,包括批量分布损失、回环损失和多视角身份损失,这些都是为了确保网络输出的鲁棒性和与身份特征的一致性。
这个系统的训练使用了未标记的面部图片和一个3D面部模型,展示了在无需监督数据的情况下通过利用面部识别网络的高级特征进行训练的可能性。整个网络的设计注重于通过各种条件(表情、姿势和照明等)保持身份特征的一致性,同时避免网络欺骗效应,即生成在特征空间中匹配但在视觉上看起来不自然的面部。
实验部分
4.1 定性分析
在这个实验中,研究者们通过在一个包含84张图片的测试集上比较了几种不同的面部识别技术。这些技术包括他们自己的方法以及其他几个研究小组的方法,如Tran et al. [30]、Tewari et al. [28](MoFA)、和Sela et al. [26]。
实验的主要目的是评估和展示他们的方法在面部特征识别上的改进,特别是在眼睛、眉毛和鼻子的形状以及肤色和肤色保真度方面。具体来说:
- 对比分析:他们的方法与其他几种方法进行了比较,特别强调在保持面部特征真实性和色彩保真度方面的优势。
- 技术细节:使用了称为“批量分布损失”的技术,这一技术允许每个面孔相对于巴塞尔模型(通常为浅肤色)的平均值有所不同,只要这些面孔在总体上与平均值相匹配。这与其他方法不同,后者通常将每个面孔规范化到模型分布的平均值,通常会导致整体肤色偏浅。
- 结果显示:他们的方法在减少身份和表情的混淆、以及肤色和光照混淆方面表现更为出色,而Sela等的非结构化方法仅预测形状,没有考虑身份和表情的区分,从而稳健性较低。
4.2 Neutral Pose Reconstruction on MICC
在这个实验中,研究人员使用一个名为MICC Florence 3D Faces数据集的数据集来评估他们的3D人脸重建模型的准确性。这个数据集包括53位白种人受试者的中性表情的地面真实3D扫描。此外,每个受试者都有在不同条件下拍摄的三个视频,这些条件分别标记为'合作'、'室内'和'室外'。
实验的程序包括:
-
运行重建算法:研究人员在视频的每一帧上运行他们的重建方法。然后,他们平均每个视频中所有帧的重建结果,为每种条件创建一个单一的重建。
-
与先前研究比较:他们将自己的结果与先前由Tran等人进行的研究的结果进行比较。为了比较,他们使用了相同的结果平均方法,但将其应用于数据的不同方面(即Tran等人平均处理网格,而作者平均处理他们的编码器嵌入)。
-
对齐和裁剪扫描:为了评估他们的预测,他们将地面真实扫描裁剪到鼻尖周围的特定区域,并使用一种称为迭代最接近点(ICP)的方法,并调整各向同性比例来对齐重建和地面真实。
-
误差测量:他们使用对称的点到平面距离来测量误差,该距离在ICP对齐定义的区域内进行测量。这一指标比较了重建扫描和实际扫描表面之间的平均距离,考虑到方法和地面真实之间的顶点密度变化。
-
统计分析:他们以平均误差和标准偏差的形式呈现其在数据集不同环境条件下的结果,指出与以前研究相比,他们的方法在准确性(平均误差)和一致性(标准偏差)方面都有所改进。
研究结果突出显示,与先前的研究相比,作者的方法不仅将绝对误差降低了20-25%,而且还在不同个体和条件下取得了更一致的结果,误差测量的变异性显著降低。此外,他们的方法在不同的测试条件(合作、室内、室外)下表现出更好的稳定性,展示了其方法的健壮性。
4.3 Face Recognition Results
这个实验通过使用VGG-Face识别网络的激活来量化评估3D人脸重建模型的相似性。研究者选择使用VGG-Face是因为他们在训练损失中使用了FaceNet,这使得FaceNet不适合作为评估指标。具体实验步骤如下:
1.相似性度量的计算:对于评估数据集中的每张面部图像,研究人员计算输入图像和他们输出几何体的渲染之间的VGG-Face φ(` t) 层的余弦相似性。
2.相似性分布的展示:他们在论文中展示了Labeled Faces in the Wild (LFW)、MICC和MoFA-Test数据集的相似性分布。为了进行比较,他们还展示了LFW数据集中所有照片对(按同一人和不同人分开)的相似性。
3.平均相似性:在MoFA测试数据集上,他们的方法在渲染和照片之间的平均相似性为0.403。相比之下,LFW数据集中同一人的照片对中有22.7%的得分低于0.403,不同人的照片对中只有0.04%的得分高于0.403。
在这个实验中,"得分"特指通过VGG-Face网络计算得到的余弦相似性值。这个得分用来量化两个面部图像或一个面部图像与一个3D渲染面部之间的相似性。
余弦相似性是一种常用的相似性度量方法,用来比较两个向量在方向上的相似度。在计算VGG-Face网络特征层的激活时,每个图像或3D渲染可以被表示为一个特征向量。余弦相似性通过测量这两个特征向量的夹角的余弦值来计算它们之间的相似度
具体来说,这些得分表达了以下几个方面:
-
相似性的量度:余弦相似性得分是一个介于-1和1之间的值,其中1表示完全相同的特征激活(即完全相似),0表示无相关性,而-1表示完全相反的特征激活。在这个上下文中,较高的正值(接近1)意味着高度相似。
-
比较标准:在MoFA测试数据集中,他们的方法在渲染和照片之间的平均相似性为0.403。这个数值用来与LFW数据集中的相似性分布进行比较。例如,在LFW数据集中,同一人的照片对中有22.7%的对得分低于0.403,而不同人的照片对中只有0.04%的对得分高于0.403。这表明0.403是一个相对较高的得分,能够区分同一人与不同人的面部图像。
-
性能指标:这个得分还被用作评估3D重建模型性能的一个指标。通过比较渲染的3D模型与原始照片之间的相似性得分,研究人员可以评估模型重建的质量和准确性。得分越高,表示重建的质量越好,与原始图像的相似度越高。
4.EMD验证:通过计算地球移动者距离 (Earth Mover’s Distance, EMD) 来进一步验证他们的方法。这个距离衡量了所有对比方法的结果与LFW同一人和不同人分布之间的距离。他们的方法的结果更接近同一人的分布,而其他方法的结果则更接近不同人的分布。
EMD衡量的是,将一个概率分布转换为另一个概率分布所需的“工作量”或“成本”。在形象的说法中,可以想象为将一堆沙子(第一个分布)移动并改形成另一堆沙子(第二个分布)所需的最小劳力。如果两个分布非常相似,所需的工作量就很小,因此EMD值也小;如果两个分布差异很大,所需的工作量就高,EMD值也大。
在这项研究中,研究人员使用EMD来比较以下两个概率分布:
-
同一人的照片对分布(Same-person distribution):这是LFW(Labeled Faces in the Wild)数据集中,同一个人的不同照片之间的相似性分布。这个分布反映了相同身份的不同照片在面部特征上的内在一致性。
-
不同人的照片对分布(Different-person distribution):这是LFW数据集中,不同人之间的照片对的相似性分布。这个分布反映了不同身份之间面部特征的差异。
研究人员使用EMD来衡量由他们的方法和其他方法生成的面部重建结果与这两个分布的接近程度。具体来说,他们的目标是确定哪些方法生成的重建结果的相似性分布更接近“同一人的照片对分布”,从而表明重建结果保持了个体的独特面部特征。
根据实验结果,研究人员发现他们的方法生成的结果在EMD度量上更接近同一人的照片对分布,而其他方法的结果则更接近不同人的照片对分布。这表明,相比于其他方法,他们的重建结果在面部特征的保真度和个体识别方面表现得更好。换言之,他们的方法在重建个体独有的面部特征上更为准确和一致,从而在面部识别和验证的应用中可能表现更佳。
5.身份聚类回忆测试:使用VGG-Face距离对MoFA-Test和LFW进行身份聚类回忆测试。给定一个渲染网格,任务是通过查找根据VGG-Face φ(` t) 余弦相似性的最近邻照片来恢复未知源身份。Top-1和Top-5显示了正确身份的照片被回忆为最近邻或最近5个邻居的比例。
身份聚类回忆测试是一个用来评估面部识别系统效果的方法。具体来说,它涉及到如何通过人脸识别技术确定某个渲染的3D面部模型的身份。这是通过比较模型和一组照片之间的相似度完成的,使用的是VGG-Face模型提供的特征来计算余弦相似性。
测试流程:
-
渲染网格:
- 渲染网格指的是通过3D建模技术生成的面部模型,这个模型是基于实际人物的面部特征渲染出的数字化3D图像。
-
使用VGG-Face计算相似性:
- VGG-Face是一个深度学习模型,专门用于面部识别,它可以提取面部图像的特征。通过这些特征,可以计算任意两张面部图像之间的余弦相似度。
-
最近邻照片查找:
- 给定一个3D渲染的面部模型,系统会在一个数据集中查找与之最相似的照片(即特征空间中的最近邻)。这个数据集可以是MoFA-Test或LFW等公认的面部识别数据集。
-
Top-1 和 Top-5 召回率:
- Top-1召回率指的是系统找到的与3D模型最相似的那一张照片正确匹配到原始人物身份的比例。
- Top-5召回率则是指系统找到的最相似的前五张照片中有任意一张正确匹配到原始人物身份的比例。
6.性能和基线比较:他们还比较了MICC数据集中的地面真实3D面部扫描与其输入照片的相似性分布,提供了相似性得分的上限。他们的方法尚未达到地面真实基线的性能。
这个实验表明,通过使用VGG-Face网络的特定层的激活作为相似性的量化指标,可以有效评估3D人脸重建模型的性能,特别是在识别相似性方面。
4.4Face Clustering
这段描述了如何通过执行聚类任务来验证生成的3D网格模型在恢复个体身份方面的可识别性。具体步骤和结果概述如下:
-
数据集和方法应用:
- 研究者在两个数据集(LFW和MoFA-Test)上运行了他们的重建方法。
- LFW(Labeled Faces in the Wild)数据集包含约13,000张照片和超过5,000个身份。
- MoFA-Test数据集则包含84张图像和78个不同的身份。
-
3D模型的渲染和近邻查找:
- 对数据集中的所有面部进行3D重建,并渲染输出的几何结构。
- 对于每个渲染的3D模型,使用VGG-Face φ(` t) 距离找到与之最相近的邻居(nearest neighbors)。
-
身份回调效果(Identity Recall):
- 表格3显示了能够将源身份的照片作为最近邻居回调的网格的比例,以及在最近的五个邻居中找到源身份照片的比例。
- 在MoFA-Test上,他们的方法实现了87%的Top-1回调率,显著高于Tran等人的25%和MoFA的19%。
- 在更大的LFW数据集上,尽管竞争身份数量庞大,他们的方法仍实现了51%的Top-5回调率。
研究者得出结论,他们的方法能够生成在包含数千个候选身份的测试集中依然可识别的3D可变形模型。这说明他们的重建方法在保持人脸特征的准确性和独特性方面表现出色,使得重建的3D模型能够有效地被识别并与原始身份相匹配。
总结
文章讲述的是一个回归网络如何利用面部身份特征向量作为输入,从而在姿态、表情、光照、遮挡和分辨率发生变化时仍能保持鲁棒性,同时对身份的变化保持敏感。这种网络能够在各种条件变化下为单一主题生成一致的输出,体现了其稳健性。
此外,描述中还提到了该网络能从非写实的艺术作品中重建出可信的肖像,这在传统的基于逆渲染方法中可能难以实现。这种能力得益于网络对高级身份特征的处理,这些特征对非现实的像素级信息保持不变,且网络的无监督损失聚焦于重建中对识别重要的方面。
总的来说,这说明了该回归网络在处理各种复杂视觉信息时的高效性和应用潜力,尤其是在面部识别和图像重建领域。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









