






一、维度的基本概念
维度是维度建模的基础和灵魂。在维度建模中,将度量称为“事实”将环境描述为“维度”,维度是用于分析事实所需要的多样环境。例如在分析交易过程时,可以通过买家、卖家、商品和时间等维度描述交易发生的环境。
维度所包含的表示维度的列,称为维度属性。维度属性是查询约束条件、分组和报表标签生成的基本来源,是数据易用性的关键。例如,在查询请求中,获取某类目的商品、正常状态的商品等,是通过约束商品类目属性和商品状态属性来实现的;统计淘宝不同商品类目的每日成交金额,是通过商品维度的类目属性进行分组的;我们在报表中看到的类目、BC类型(B指天猫,C指集市)等,都是维度属性。所以维度的作用一般是查询约束、分类汇总以及排序等。
我们假设在分析交易过程中,用数据表模拟事实表和维度表的关系,并展示如何通过维度属性进行查询约束、分组和排序操作。
import pandas as pd
# 模拟事实表 (交易表)
facts = pd.DataFrame({
'transaction_id': [1, 2, 3, 4, 5],
'buyer_id': [101, 102, 103, 101, 104],
'seller_id': [201, 202, 201, 203, 202],
'product_id': [301, 302, 303, 301, 304],
'amount': [500, 300, 700, 100, 200],
'transaction_date': ['2023-01-01', '2023-01-02', '2023-01-02', '2023-01-03', '2023-01-03']
})
# 模拟维度表 (商品维度)
products = pd.DataFrame({
'product_id': [301, 302, 303, 304],
'category': ['Electronics', 'Clothing', 'Clothing', 'Electronics'],
'status': ['Normal', 'Normal', 'Discounted', 'Normal'],
'bc_type': ['B', 'C', 'B', 'C']
})
# 将事实表和维度表合并
df = pd.merge(facts, products, on='product_id')
# 查看合并后的表
print("合并后的数据表:")
print(df)
# 查询约束:获取正常状态的商品交易
normal_transactions = df[df['status'] == 'Normal']
print("\n正常状态商品的交易:")
print(normal_transactions)
# 分类汇总:统计每个商品类目的总交易金额
category_summary = df.groupby('category')['amount'].sum().reset_index()
print("\n按商品类目统计的总交易金额:")
print(category_summary)
# 排序:按交易金额降序排序
sorted_transactions = df.sort_values(by='amount', ascending=False)
print("\n按交易金额降序排序的交易记录:")
print(sorted_transactions)
- 查询约束:通过维度属性(如
status)筛选出特定条件的交易。 - 分类汇总:利用维度属性(如
category)进行分组统计,得到每类商品的总交易金额。 - 排序:根据度量(
amount)进行降序排序,便于分析高价值交易。
可见无论是where、group by还是order by,后跟的都可以称为维度。
维度使用主键标识其唯一性,主键也是确保与之相连的任何事实表之间存在引用完整性的基础。主键有两种:代理键和自然键,它们都是用于标识某维度的具体值。但代理键是不具有业务含义的键,一般用于处理缓慢变化维;自然键是具有业务含义的键。比如商品,在ETL过程中,对于商品维表的每一行,可以生成一个唯一的代理键与之对应,商品本身的自然键可能是商品ID等。
其实对于前台应用系统来说,商品ID是代理键,而对于数据仓库系统来说,商品ID则属于自然键。
前台应用系统中的商品ID:代理键
在前台应用系统中,商品ID通常是系统内部生成的唯一标识符,可能是自增的整数值或 UUID,作为商品的 代理键。
- 特点:
- 用于系统内部逻辑的唯一标识。
- 无实际业务意义,仅为数据库主键服务。
- 例如,一个电商平台的商品ID可能是 1001、1002……,这些ID并没有透露商品的具体业务信息。
数据仓库系统中的商品ID:自然键
在数据仓库中,商品ID被视为 自然键,因为它代表商品的实际业务意义,用来连接和描述商品与其关联的数据(比如销量、库存等)。
- 特点:
- 用来反映实际的业务逻辑。
- 作为不同数据表之间的关联桥梁。例如,通过商品ID关联商品表和销售表,进行分析统计。
- 在数据仓库中,它是数据分析和查询的关键字段。
为什么会有这种差异?
-
在 前台应用系统 中:
- 商品ID通常是内部生成的无意义标识符,主要用于快速、高效地操作数据库。
- 它是数据库的技术手段,和业务逻辑无关,所以称为代理键。
-
在 数据仓库系统 中:
- 商品ID承载着业务逻辑,是唯一标识商品的业务属性,能用于维度建模或多表关联。
- 它的意义源自业务本身,反映了商品的业务特性,因此称为自然键。
二、维度的设计过程
维度的设计过程就是确定维度属性的过程,如何生成维度属性,以 及所生成的维度属性的优劣,决定了维度使用的方便性,成为数据仓库 易用性的关键。正如Kimball所说的,数据仓库的能力直接与维度属性 的质量和深度成正比。
下面以淘宝的商品维度为例对维度设计方法进行详细说明。
第一步:选择维度或新建维度。
作为维度建模的核心,在企业级数据仓库中必须保证维度的唯一性。以淘宝商品维度为例,有且只允许有一个维度定义。
- 假设企业级数据仓库中已经有一个 "商品维度" 定义(包含商品相关信息,如商品名称、类目、价格等)。
- 此时,在构建新的分析模型时,不应该重复创建商品维度,而是直接复用这个维度。
- 如果没有定义过商品维度,则需要新建商品维度,并明确其范围和作用(如用于商品分析、库存管理等)。
第二步:确定主维表。
此处的主维表一般是ODS表(操作数据层),直接与业务系统同步。以淘宝商品维度为例,s_auction_auctions是与前台商品中心 系统同步的商品表,此表即是主维表。主维表用于提供维度的基础信息,例如商品维度中的商品ID、商品名称等.
主维表不是事实表,它是一个维度表。
在数据仓库设计中,主维表属于维度表的范畴,用于存储描述性数据,也就是“维度属性”。这些属性为事实表中的度量提供环境和上下文信息,例如商品的名称、分类、品牌等。
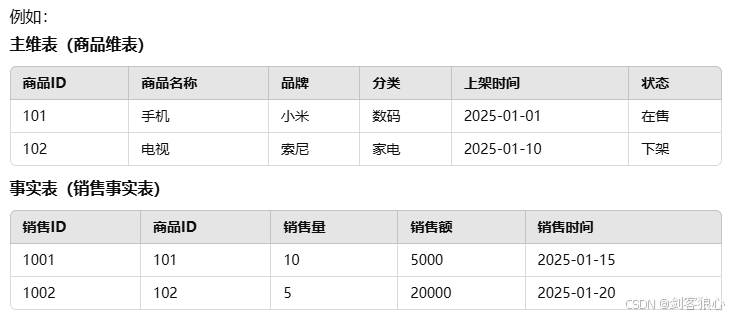
可以看出销售事实表记录的是一条条业务信息,什么时间点谁卖出了多少A商品,而主维表记录的可能是商品信息,可能是地点信息,都只是某一部分信息的详细情况。
一个完整的s_auction_auctions表如下:
| 字段名称 | 字段类型 | 描述 |
|---|
| auction_id | BIGINT | 商品唯一标识(商品ID) |
| auction_name | VARCHAR(255) | 商品名称 |
| category_id | BIGINT | 商品所属类目ID |
| category_name | VARCHAR(255) | 商品所属类目名称 |
| seller_id | BIGINT | 卖家ID |
| shop_id | BIGINT | 店铺ID |
| price | DECIMAL(10, 2) | 商品价格 |
| stock | INT | 商品库存 |
| status | TINYINT | 商品状态(0:下架,1:在售等) |
| created_time | DATETIME | 商品创建时间 |
| updated_time | DATETIME | 商品更新时间 |
| on_shelf_time | DATETIME | 商品上架时间 |
| off_shelf_time | DATETIME | 商品下架时间 |
| is_promotion | TINYINT | 是否促销商品(0:否,1:是) |
| property | TEXT | 商品属性(如品牌、颜色等,key:value 格式) |
| spu_id | BIGINT | 标准化商品单元ID(SPU) |
| sku_count | INT | 该商品关联的SKU数量 |
| image_url | VARCHAR(255) | 商品主图URL |
| description | TEXT | 商品描述 |
| delivery_type | VARCHAR(50) | 配送方式(如快递、自提等) |
| region_id | BIGINT | 商品所属地区ID |
| brand | VARCHAR(100) | 商品品牌(如 Apple、Nike) |
| sales_volume | INT | 商品销售量 |
| rating | DECIMAL(3, 2) | 商品评分(如 4.5/5) |
第三步:确定相关维表。
数据仓库是业务源系统的数据整合,不同业务系统或者同一业务系统中的表之间存在关联性。根据对业务的理解,确定哪些表和主维表存在关联关系,并选择其中的某些表用于生成维度属性。以淘宝商品维度为例,根据对业务逻辑的理,可以得到商品与类目、SPU、卖家、店铺等维度存在关联关系。
- 商品维度需要更多的属性来支持复杂的分析,例如:
- 类目表 提供商品的类目信息(如商品属于电子类或服装类)。
- SPU表 提供商品的标准化单元信息(如一组 iPhone 15 的不同规格的商品共用一个 SPU)。
- 卖家表 提供与商品相关的卖家信息(如卖家名称、信誉等级等)。
- 店铺表 提供商品所属店铺的信息(如店铺ID、店铺评分等)。
- 通过这些相关表,可以生成商品类目、SPU编号、卖家名称、店铺名称等维度属性。
第四步:确定维度属性。
本步骤主要包括两个阶段,其中第一个阶段是从主维表中选择维度属性或生成新的维度属性;第二个阶段是从相 关维表中选择维度属性或生成新的维度属性。以淘宝商品维度为例,从 主维表(sauction auctions)和类目、SPU、卖家、店铺等相关维表中 选择维度属性或生成新的维度属性。
阶段 1:从主维表中选择或生成维度属性
- 主维表
sauctionauctions是商品维度的核心表,其中包含以下字段:- 商品价格
- 商品发布时间
- 商品状态(如在售、下架)
- 商品名称
- 商品ID
- 直接选择的维度属性:
- 商品ID(唯一标识商品)
- 商品名称
- 加工生成的新维度属性:
- 商品状态可以映射成更具描述性的状态值,如将数字状态 "1" 转换为 "在售"。
- 商品发布时间可以派生为 "商品上架年份" 或 "商品上架季度" 等时间维度。
阶段 2:从相关维表中选择或生成维度属性
- 相关维表包括类目表、SPU表、卖家表、店铺表等。这些表提供了商品的上下文信息,可以从中选择或生成新的维度属性:
- 店铺表:
- 直接选择:店铺ID、店铺名称。
- 派生生成:店铺评分(如“综合评分”)。
- 卖家表:
- 直接选择:卖家ID、卖家名称。
- 派生生成:卖家信誉级别(如“钻石卖家”)。
- SPU表:
- 直接选择:商品的SPU编号。
- 派生生成:商品的规格组(如“颜色”和“存储容量”)。
- 类目表:
- 直接选择:商品类目(如“电子产品”、“服装”)。
- 派生生成:商品的一级类目(如“家电”)和二级类目(如“电视机”)。
- 店铺表:
为何需要两个阶段?
- 从主维表中选择维度属性 是为了保证维度的基础完整性,确保维度的核心字段涵盖最基础的信息。
- 从相关维表中选择维度属性 则是为了提升维度的丰富性,使得维度在分析中具备更强的上下文描述能力。
- 两者结合,能够确保维度既有深度(主维表)又有广度(相关维表)。
三、一致性维度和交叉探查
构建企业级数据仓库不可能一蹴而就,一般采用迭代式的构建过程。而单独构建存在的问题是形成独立型数据集市,导致严重的不一致性。
Kimball的数据仓库总线架构提供了一种分解企业级数据仓库规划任务的合理方法,通过构建企业范围内一致性维度和事实来构建总线架构。
数据仓库总线架构的重要基石之一就是一致性维度。在针对不同数据域进行迭代构建或并行构建时,存在很多需求是对于不同数据域的业务过程或者同一数据域的不同业务过程合并在一起观察。比如对于日志数据域,统计了商品维度的最近一天的PV和UV;对于交易数据域,统计了商品维度的最近一天的下单GMV。现在将不同数据域的商品的事实合并在一起进行数据探查,如计算转化率等,称为交叉探查。
如果不同数据域的计算过程使用的维度不一致,就会导致交叉探查存在问题。当存在重复的维度,但维度属性或维度属性的值不一致时,会导致交叉探查无法进行或交叉探查结果错误。接上个例子,假设对于日志数据域,统计使用的是商品维度1:对于交易数据域,统计使用的是商品维度2。商品维度1包含维度属性BC类型,而商品维度2无此属性,则无法在BC类型上进行交叉探查;商品维度1的商品上架时间这一维度属性时间格式是yyyy-MM-ddHH:mm:ss,商品维度2的商品上架时间这一维度属性时间格式是UNIXtimestamp,进行交叉探查时如果需要根据商品上架时间做限制,则复杂性较高;商品维度1不包含阿里旅行的商品,商品维度2包含全部的淘系商品,交叉探查也无法进行。还有很多种形式的不一致,这里不再一一列举,但基本可以划分为维度格式和内容不一致两种类型。
上面对维度不一致性进行了详细分析,下面总结维度一致性的几种表现形式。
1)共享维表。比如在阿里巴巴的数据仓库中,商品、卖家、买家、类目等维度有且只有一个。所以基于这些公共维度进行的交叉探查不会存在任何问题。
案例:阿里巴巴商品维表
- 商品维度:商品维表中存储商品的属性(如商品ID、名称、品牌等),用于描述商品的环境。
- 卖家维度:卖家维表中存储卖家的相关属性(如卖家ID、卖家名称、信誉等级等)。
- 买家维度:买家维表中存储买家的相关属性(如买家ID、买家姓名、购买习惯等)。
通过共享这些维表,不同的分析(如买家行为分析、商品销售分析、卖家绩效分析)都能基于一致的维度属性,避免因多版本维表导致的数据矛盾。
2)一致性上卷,其中一个维度的维度属性是另一个维度的维度属性的子集,且两个维度的公共维度属性结构和内容相同。比如在阿里巴巴的商品体系中,有商品维度和类目维度,其中类目维度的
维度属性是商品维度的维度属性的子集,且有相同的维度属性和维度属性值。这样基于类目维度进行不同业务过程的交叉探查也不会存在任何问题。
案例:商品维度和类目维度
- 商品维度:包含具体商品的信息,例如商品ID、名称、品牌、类目等。
- 类目维度:仅包含类目信息(如一级类目、二级类目等)。
在阿里巴巴商品体系中:
- 类目维度是商品维度的子集(类目维度中的类目属性是商品维度中类目属性的一个投影)。
- 两个维度具有相同的类目属性和属性值,例如“手机类目”在两个维度中是一致的。
因此,可以基于类目维度对不同业务过程(如商品销售分析和类目总览分析)进行交叉分析。
3)交叉属性,两个维度具有部分相同的维度属性。比如在商品维度中具有类目属性,在卖家维度中具有主营类目属性,两个维度具有相同的类目属性,则可以在相同的类目属性上进行不同业务过程的交叉探查。
案例:商品维度和卖家维度
- 商品维度:包含商品的属性,例如商品ID、类目、品牌等。
- 卖家维度:包含卖家的属性,例如卖家ID、主营类目、信誉等级等。
两者的交叉属性:
- 类目属性:商品维度中有类目属性,用于描述商品的分类。
- 主营类目属性:卖家维度中有主营类目属性,用于描述卖家主营商品的分类。
相同的类目属性允许以下分析:
- 不同卖家的主营类目在某些商品分类上的表现。
- 某类目商品的销量与不同卖家的类目分布之间的关系。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











