







分组丢失和延时是怎样发生的?
在路由器缓冲区的分组队列
- 分组到达链路的速率超过了链路输出的能力
- 分组等待排到对头、被传输
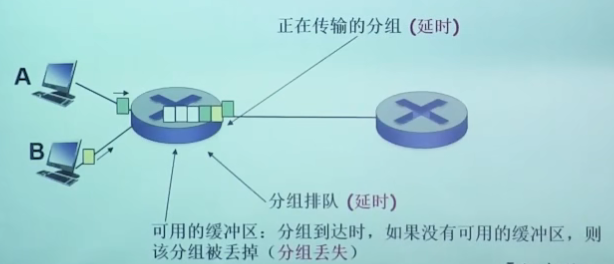
【队列也是有限的,如果对列已经溢出了,那么分组就会被丢弃。但是分组队列不能太长,因为排队时间太长也会影响应用用户体验,有一个能够容忍的等待时间上限】
四种分组延时
1. 节点处理延时(processing)【时间是确定的】
- 检查bit级差错
- 检查分组首部和决定将分组向何处
2. 排队延时(queueing)【时间取决于当前网络的使用情况,是随机的】
- 在输出链路上等待传输的时间
- 依赖于路由器的拥塞程度
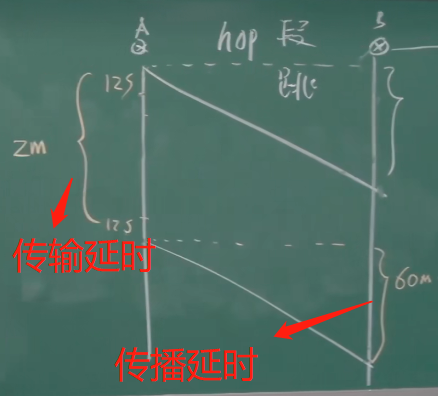
3. 传输延时(transmission)
- R = 链路带宽(bps)
- L = 分组长度(bits)
- 将分组发送到链路的时间 = L / R
- 存储转发延迟
【假设,R = 1Mbps,L = 1Mbps,那么打一个比特需要多长时间?传输L需要多上时间?】
答:
一个比特需要
1 / R = 1μs
因为R = 1Mbps,所以打1M需要1s,那么1bit就是 1 / R,1 兆字节(m)=8388608 比特(bit)。所以传输1个比特是需要持续一段时间的,不是一个点。
L / R = 1s
【发送就是接收,所以在算传输延时的时候只能算1次】
4. 传播延时(propagation)
- d = 物理链路的长度
- s = 在媒体上的传播速度(~2×10^8m / sec)
- 传播延时 = d / s
【如果两个节点距离很近,传播延时可以忽略】
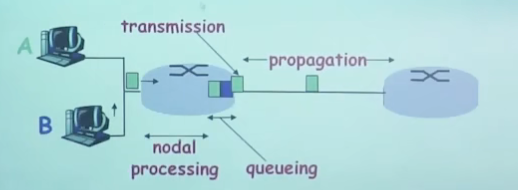
【WAN: 在传输完了,才开始传播】

【LAN: 整个分组还没传输完,第一个bit就已经到了下一个路由器了】
【信道容量:WAN可以传播很多个分组,所以容量更大。LAN容量就几乎没有】
节点延时
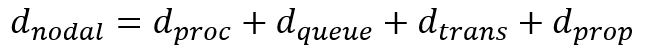
- d_proc = 处理延时
- 通常是微妙数量级或更少
- d_queue = 排队延时
- 取决于拥塞程度
- d_trans = 传输延时
- = L / R,对低速率的链路而言很大(如拨号),通常为微秒级到毫秒级
- d_prop = 传播延时
- 几微妙到几百毫秒
排队延时
- R = 链路带宽(bps)
- L = 分组长度(bits)
- a = 分组到达队列的速率
流量强度 I = La / R
- La / R ~ 0(接近于0) : 平均排队延时很小
- La / R -> 1(趋近于1): 延时变得很大
- La / R > 1(大于1) :比特到达队列的速率超过了从该队列输出的速率,平均排队延时将趋于无穷大
设计系统时流量强度不能大于1!
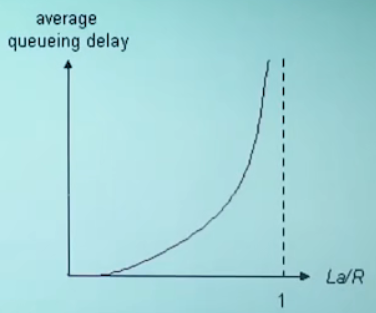
ps:
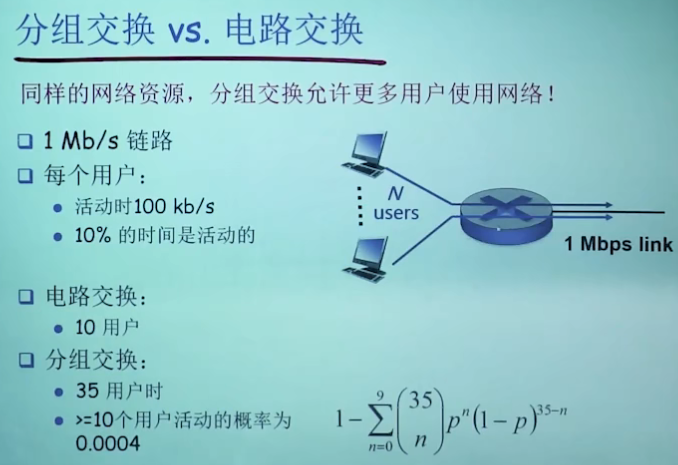
【选择9的原因:如果选择10就会挂了】
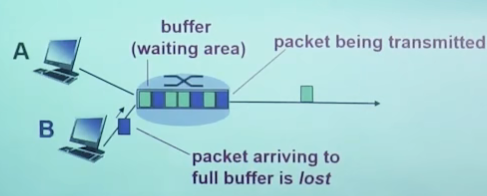
分组丢失
- 链路的丢列缓冲区容量有限
- 当分组到达一个满的队列时,该分组将会被丢失
- 丢失的分组可能会被前一个节点(链路可靠,需要有应答,如WiFi,WLAN。物理链路比较可靠的情况下,上层的链路层协议就会放弃可靠的事情)或源端系统重传(链路不可靠,如以太网。以太网向上层提供的链路服务时不可靠的,因为地下比较可靠),或根本不会重传(应用进程如果通过UDP,就不会重传)
吞吐量
- 吞吐量:在源端和目标端之间传输的速率(数据量 / 单位时间)
- 瞬间吞吐量:在一个时间点的速率
- 平均吞吐量:在一个长时间内平均值
【吐出去,对方能够收到的有效的数据量】
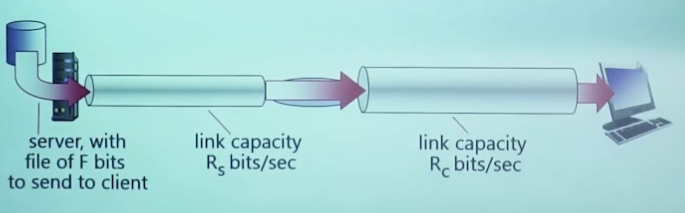
link capacity:链路容量
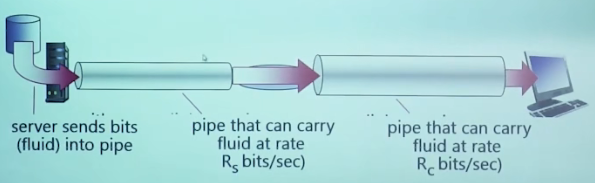
pipe that can carry fluid at rate: 可以快速输送液体的管道
【一个细一点,一个粗一点,吞吐量取决于细的】
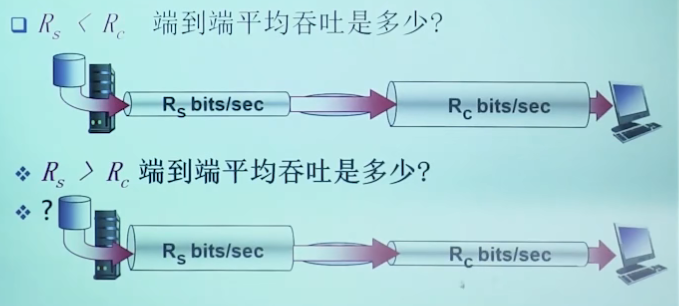
瓶颈链路:端到端路径上,限制端到端吞吐的链路
其他节点都不传输,吞吐量min{Rs, Rc}
【木桶效应】
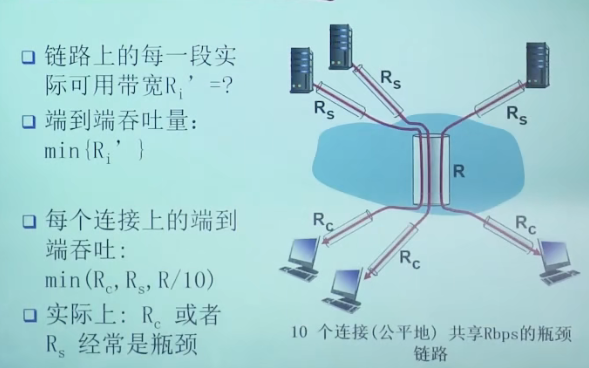
【第 i 跳会有 n 个通信对在用,那么每个通信对能获得的第 i 跳带宽就是1 / n】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









