



burp验证码爆破插件_captcha-killer-modified
前期准备,安装包下载
插件下载:https://github.com/f0ng/captcha-killer-modified
python模块安装,requirement.txt里添加ddddocr,flask不用指定版本,下面是模块和安装命令
flask
ddddocr
Pillow==9.5.0
aiohttp==3.8.3
argparse==1.1
pip install -r requirement.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
运行脚本,作者提供的脚本我用的有问题所以改了一下
# -*- encoding=utf-8 -*-
import argparse
import ddddocr # 导入 ddddocr
from aiohttp import web
ocr = ddddocr.DdddOcr()
async def handle_cb(request):
return web.Response(text=ocr.classification(await request.text()))
app = web.Application()
app.add_routes([web.post('/reg', handle_cb)])
if __name__ == '__main__':
web.run_app(app,host='127.0.0.1',port=8389)
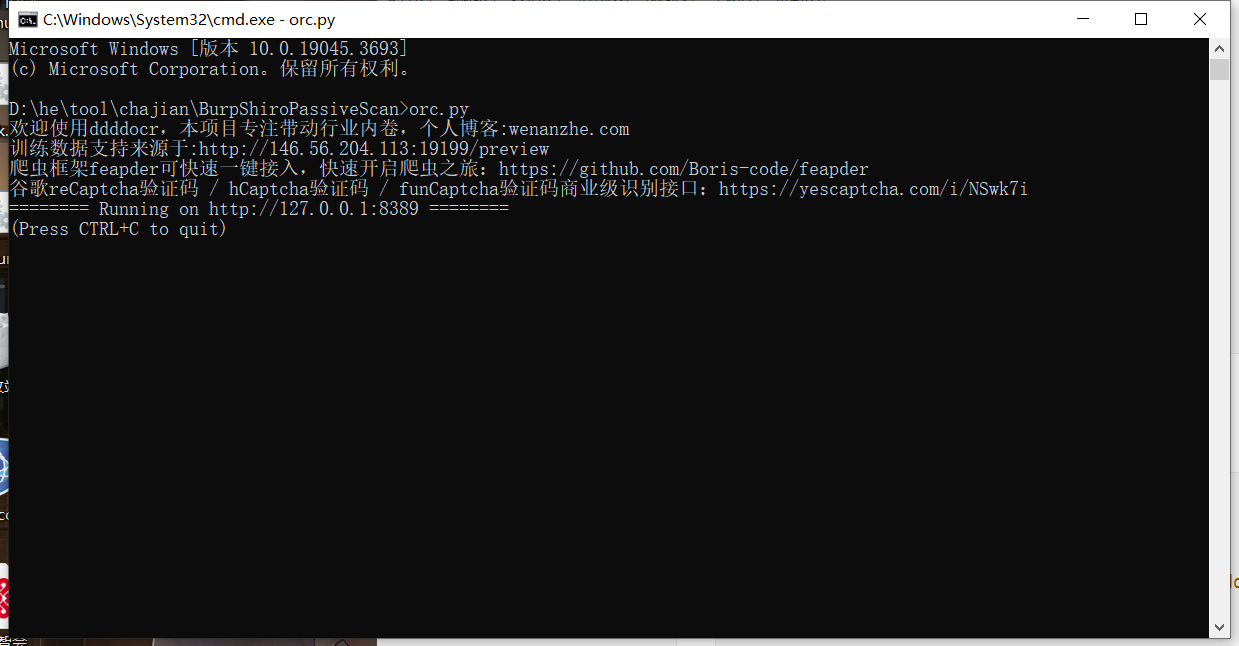
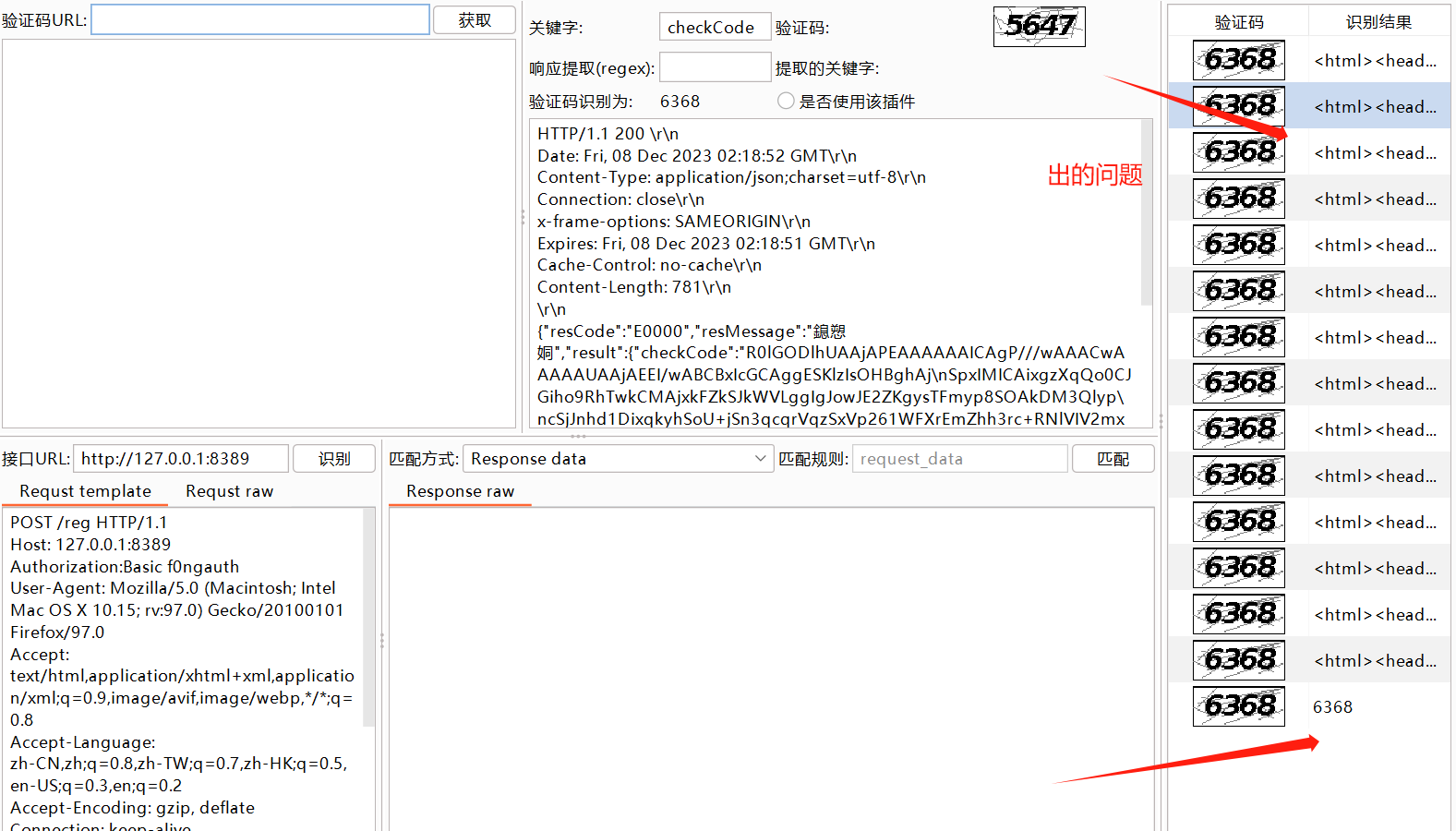
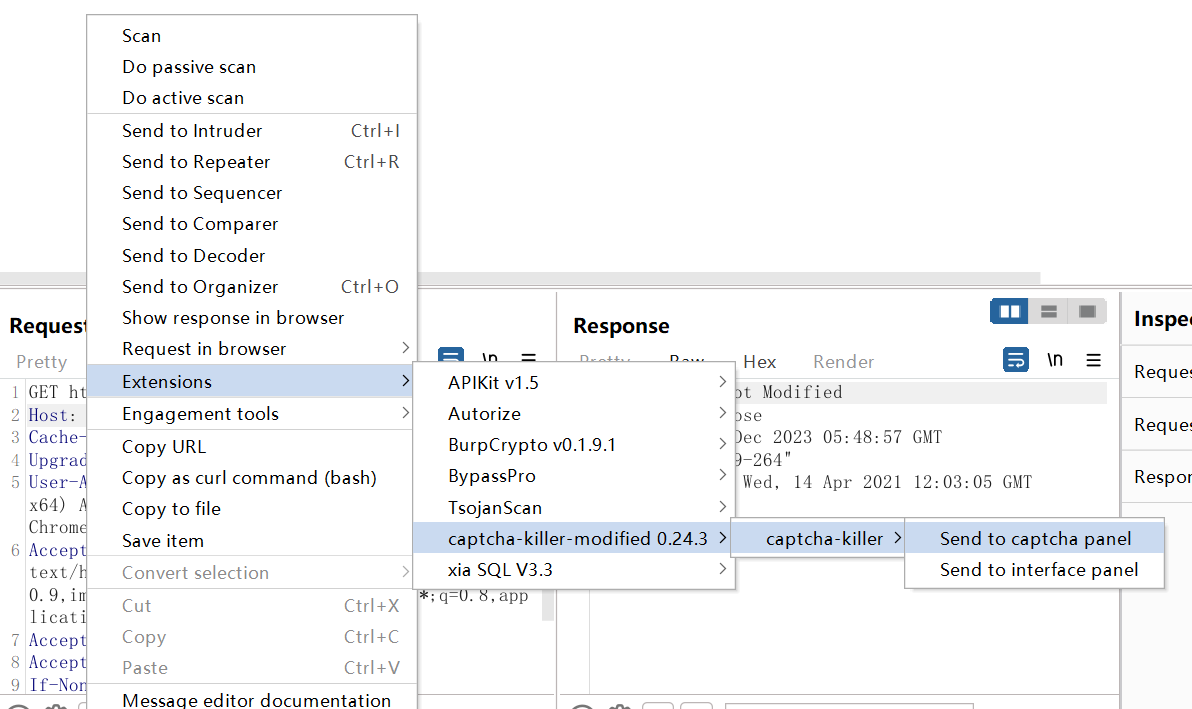
使用方法
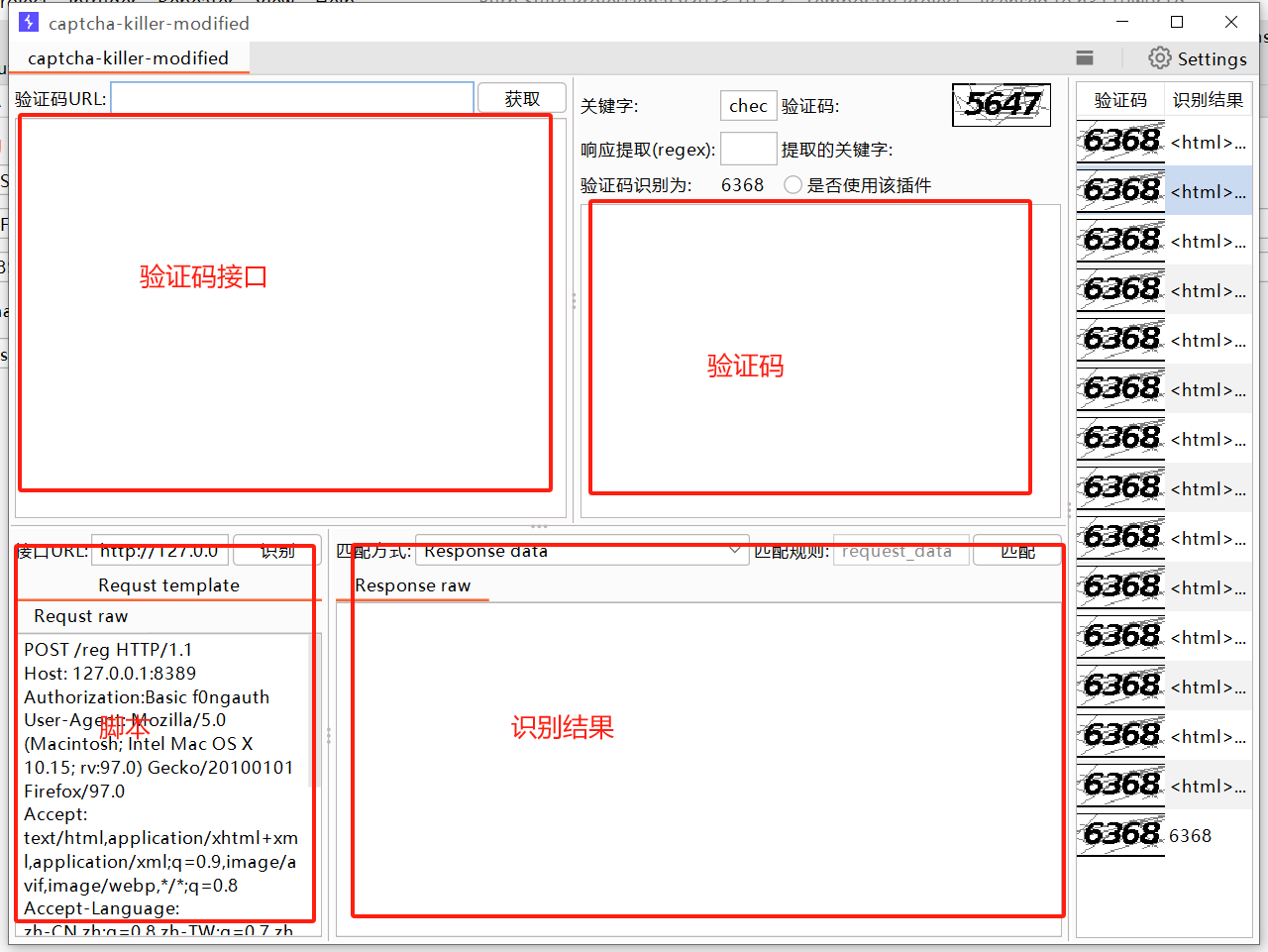
最后来个图



















 9286
9286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









