







 本文详细介绍了KMP算法的比较过程,并结合实例解析了KMP算法的核心思想。通过观看推荐视频,辅助理解字符串最长相等前后缀的构建及在算法中的作用。同时,文章探讨了KMP改进算法,提出利用nextval数组避免重复比较,提升效率。
本文详细介绍了KMP算法的比较过程,并结合实例解析了KMP算法的核心思想。通过观看推荐视频,辅助理解字符串最长相等前后缀的构建及在算法中的作用。同时,文章探讨了KMP改进算法,提出利用nextval数组避免重复比较,提升效率。
Kmp算法
推荐视频 : https://www.bilibili.com/video/BV1Px411z7Yo?t=669 学习过程中,是参考这个Kmp讲解视频来学习的。
1.先理解Kmp算法的比较过程
推荐视频 : https://v.qq.com/x/page/t0386qcr36t.html
这里有Kmp的具体比较过程。
2.自己对Kmp算法的一个文字理解
为什么要弄一个回溯的a数组:
因为 
1.先创建一个a数组,储存待比较的字符串的最长相等前后缀。
1.1示例图 :
字符串 A B A B C A B A 的示例图

A的最长相等前后缀默认为0 ,所以可以创建出一个这样的数组。
a [8] = {0 , 0 ,1 ,2 ,0 ,1 ,2 ,0};
1.2核心算法理解 :
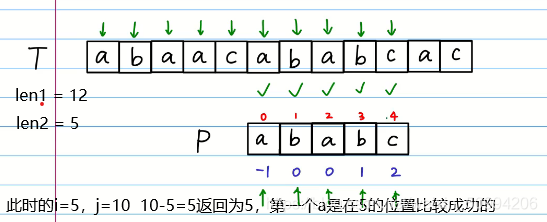
假设字符串str2 { a b c }是要在字符串str {a b c a b d a}中找到一个相同的子串。
用 j = 0 指向 str的第一个字符位置。
用 i = 0指向 str2的第一个字符位置。
len1 = str.size();
len2 = str2.size();
在j < len1 的条件下
先写出跳出循环的条件:如果i已经指向了str2的末端,也就是 i == len2,此时跳出循环,并且返回 字符串比较开始的位置。也就是
j - len2 1
还有一个跳出循环的条件,就是当** j == len1** 的时候,j已经指向 str 的末尾了,在判断完是否成功的条件后再判段** j == len1**,如果成立,则说明比较失败了,返回 -1 。
然后判断str[j] != str2[i],
在str[j] != str2[i] 成立的条件下,如果 i (i > 0)不是指向第一个字符时,就让 i 回溯到此时字符位置所对应的a[i-1] 2的位置,否则就让j++(也就是i=0时,因为第一个字符就不相同的话就没有回溯的意义了)
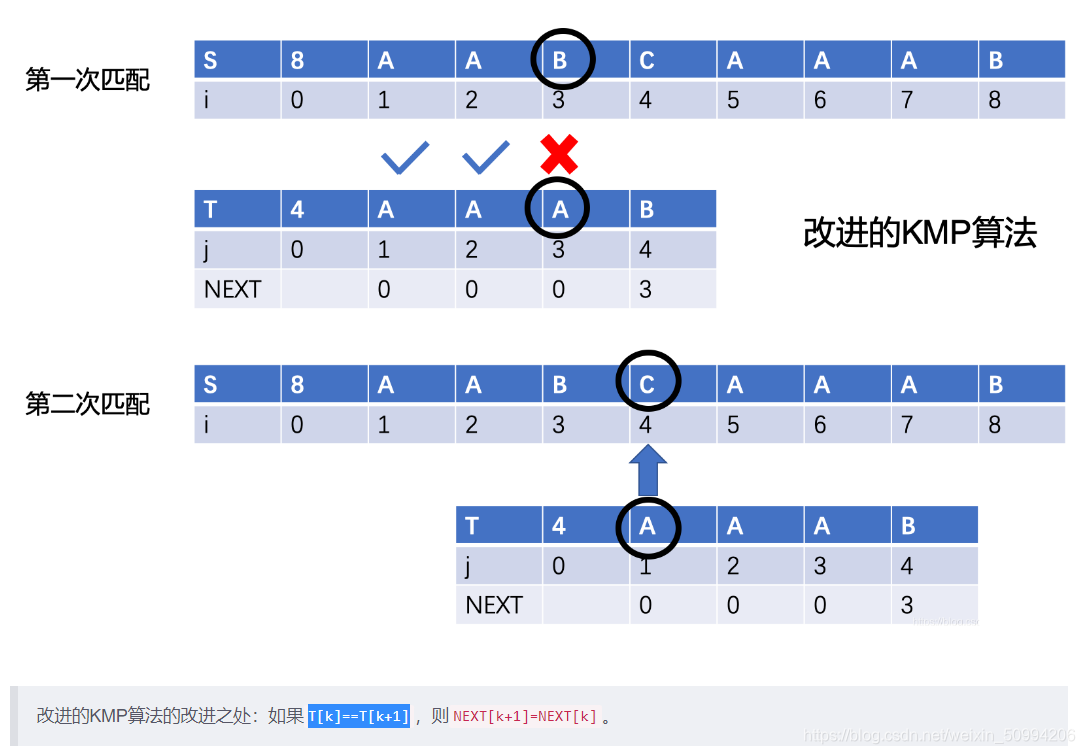
KMP改进算法的理解 ————
####### 就是因为之前的next数组中存放的是最长相等前后缀和,所以子串跳到next 所储存的位置其实还是和此时比较失败的字符是相同的,也就是意味着在做重复的比较,所以可以先创建一个nextval数组,在next数组的基础上更新变成nextval数组,转变的原理是,如果next储存的位置上的字符和此时的字符相同的话就对next指向的字符做重复的操作,将下一个字符与下下个字符进行比较。

















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









