







文章目录
- 前言
- 什么是k8s?
- k8s组件有哪些?
- 是什么?作用?原理?
- kube-apiserver介绍
- kube-scheduler介绍
- controller-manager介绍
- etcd部分
- kube-proxy部分
- ingress部分
- Ingress annotations详解
- Ingress采用https方式访问
- service部分
- 容器退出状态码总结
- pod部分
- configmap部分
- secret部分
- configmap&&secret使用subPath(防止覆盖目录,但是更新完configmap后,容器不会更新)
- serviceAccount部分
- CoreDNS部分
- RBAC部分(权限控制机制)
- 控制器部分
- HPA
- Lable&&selector(标签于选择器部分)
- 资源配额
- 资源预留配置
- Qos服务质量
- volumes部分
- PV&&PVC部分
- K8S集群网络部分
- Flannel部分
- Calico
- Flannel与Calico的优缺点
- 使用一条路由命令让非k8s集群的机器直接访问到集群内的pod
师傅领进门.修行看个人!全文从k8s官网的架构图说起
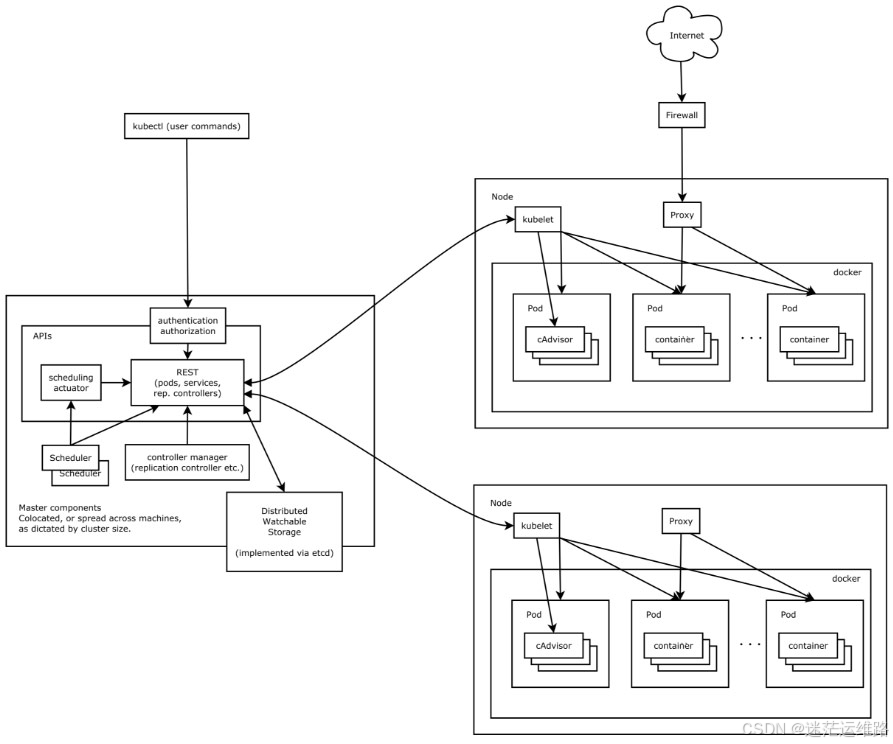
前言
本篇文章主要是我在学习k8s时自己整理的学习笔记,内容主要偏入门和基础,可以在学习k8s时用做参考,该
什么是k8s?
是一个开源的容器编排和管理平台。它允许用户自动部署、扩展和操作容器化应用程序,并提供管理这些应用程序所需的一系列工具和机制。它可以将组成应用程序的容器分组为逻辑单元,从而方便管理和发现这些容器,以及提供与应用程序相关的服务,例如负载均衡、网络、存储等。该平台基于谷歌15年生产环境中的运行经验,并结合来自社区的最佳方法和实践构建而成。
k8s组件有哪些?
master节点组件:
apiserver(处理资源操作的请求)、
controller-manager(控制器)、
scheduler(调度器)、
etcd(键值存储数据库)、
kubectl、
CoreDNS
apiserver: 暴露k8sAPI,资源的请求/调用操作都是通过kube-apiserver提供的接口进行。
controller-manager: 运行管理控制器,是集群中处理常规任务的后台线程。包括:Node节点控制器、Replication副本控制器、Endpoints控制器、serviceAccount和token控制器
schedule: 调度pod至合理的node节点
etcd: 存储集群数据(pod的内部ip是保存在endpoints中,则endpoints存储在etcd)
node节点组件: kube-proxy、kubelet
是什么?作用?原理?
kube-apiserver介绍
是集群的统一管理入口,并且提供了k8s各类资源对象的增删改查以及http Rest接口,提供kubectl命令工具与apiserver交互;
原理: 提供了K8s的rest api,实现了认证、授权、准入控制等安全校验功能,同时也负责集群状态的存储操作.
kube-scheduler介绍
调度器,为pod分配合适的Node节点。主要作用就是根据特定的调度算法和调度策略将 Pod 调度到合适的 Node 节点上去,是一个独立的二进制程序,启动之后会一直监听 API Server,获取到 PodSpec.NodeName 为空的 Pod,对每个 Pod 都会创建一个 binding。调度器在调度时,首先要确保调度后该节点上所有Pod的CPU和内存的Requests总和,不超过该节点能提供给Pod使用的CPU和Memory的最大容量值
schedule调度过程:
1、首先,客户端通过 API Server 的 REST API 或者 kubectl 工具创建 Pod 资源
2、API Server 收到用户请求后,存储相关数据到 etcd 数据库中
3、调度器监听 API Server 查看为调度(bind)的 Pod 列表,循环遍历地为每个 Pod 尝试分配节点,这个分配过程就是我们上面提到的两个阶段:
预选阶段(Predicates): 过滤节点,调度器用一组规则过滤掉不符合要求的 Node 节点,比如 Pod 设置了资源的 request,那么可用资源比 Pod 需要的资源少的主机显然就会被过滤掉
优选阶段(Priorities): 为节点的优先级打分,将上一阶段过滤出来的 Node 列表进行打分,调度器会考虑一些整体的优化策略,比如把 Deployment 控制的多个 Pod 副本分布到不同的主机上,使用最低负载的主机等等策略
4、经过上面的阶段过滤后选择打分最高的 Node 节点和 Pod 进行 binding 操作,将节点名称绑定到pod的spec上(NodeAffinity),然后将结果存储到 etcd 中.
5、最后被选择出来的 Node 节点对应的 kubelet 去执行创建 Pod 的相关操作(调用cni、csi等插件去创建网络空间、存储空间等),并将pod的spec修改为running,并将结果返回给apiserver写到etcd中
调度分为:
预选过程: 过滤掉不满足条件的节点,这个过程称为Predicates
优选过程: 对通过的节点按照优先级排序,称之为Priorities
controller-manager介绍
集群内部的管理控制中心,负责集群内部的Node、pod副本、endpoints、namespace等管理,当某个Node宕机时,会及时发现并执行自动化修复流程,确保集群始终处于预期工作状态。
etcd部分
存储集群数据,以key-value键值对的形式存储.存储pod相关信息、集群网络信息等
补充: etcd备份示例
etcd备份,以cronjob资源类型进行定时任务,并将备份保存到pvc中
1、创建一个名为etcd-backup的ConfigMap,里面包含etcd备份脚本和其他需要的配置信息
apiVersion: v1
kind: ConfigMap
metadata:
name: etcd-backup
data:
backup.sh: |
#!/bin/bash
set -euo pipefail
ETCDCTL_API=3 /usr/local/bin/etcdctl \
--endpoints="https://etcd-0.etcd.default.svc.cluster.local:2379,https://etcd-1.etcd.default.svc.cluster.local:2379,https://etcd-2.etcd.default.svc.cluster.local:2379" \
--cert="/etc/etcd/tls/etcd-client.crt" \
--key="/etc/etcd/tls/etcd-client.key" \
--cacert="/etc/etcd/tls/ca.crt" \
snapshot save /var/lib/etcd-backup/$(date "+%Y%m%d%H%M%S").db //备份
snapshot restore /var/lib/etcd-backup/$(date "+%Y%m%d%H%M%S").db //恢复
retention: "7" #表示备份保留天数。
2、创建一个名为etcd-backup-pvc的PersistentVolumeClaim,用于存储备份文件
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: etcd-backup-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
3、创建一个名为etcd-backup-job的CronJob,在指定时间执行备份脚本,并将备份文件存储到etcd-backup-pvc中
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: etcd-backup-job
spec:
schedule: "0 0 */3 * *" # 每三天执行一次备份,UTC时间
jobTemplate:
spec:
template:
spec:
containers:
- name: etcd-backup-container
image: busybox:latest
command: ["/bin/sh"]
args: ["-c", "source /mnt/etcd-backup-config/backup.sh"]
volumeMounts:
- name: etcd-backup-config-volume
mountPath: "/mnt/etcd-backup-config"
- name: etcd-backup-pvc
mountPath: "/var/lib/etcd-backup"
volumes:
- name: etcd-backup-config-volume
configMap:
name: etcd-backup
restartPolicy: Never
volumes:
- name: etcd-backup-pvc
persistentVolumeClaim:
claimName: etcd-backup-pvc
etcd常用命令
1、为etcdctl工具创建别名
alias etcdctl='etcdctl --endpoints=https://127.0.0.1:2379 --cacert=/etc/kubernetes/pki/etcd/ca.crt --cert=/etc/kubernetes/pki/etcd/healthcheck-client.crt --key=/etc/kubernetes/pki/etcd/healthcheck-client.key'
#把上面这串别名复制到 /etc/profile 文件里,然后重新登录shell终端即可
2、列出etcd集群一共有几个节点 -w table 输出为表格式
etcdctl member list -w table
3、查看个节点状态
etcdctl endpoint status
4、查看etcd是否健康
etcdctl endpoint health
kube-proxy部分
当节点关闭ip_forward对clusterip访问影响
节点与Pod的ip无法互通
容器ip之间无法互通
容器内无法访问clusterip和nodeport
kube-proxy作用
作用:
kube-proxy是k8s网络代理核心组件,部署在每个Node节点上,主要维护节点上的网络规则,它是实现service的通信与负载均衡机制的重要组件,kube-proxy负责为pod创建代理服务,通过watch机制会根据 service 和 endpoints,node资源对象的改变来实时刷新iptables或者ipvs规则。使发往 Service 的流量(通过ClusterIP和NodePort)负载均衡到正确的后端Pod。
总结:
1、kube-proxy是管理service的访问入口,包括集群内pod到service的访问和集群外访问service;
2、kube-proxy管理service的Endpoints;
3、kube-proxy主要作用就是负责service的实现
缺点:
kube-proxy 目前仅支持 TCP 和 UDP,不支持 HTTP 路由,并且也没有健康检查机制。这些可以通过自定义 "Ingress Controller" 的方法来解决。
kube-proxy工作模式介绍
工作模式: (查看kube-proxy的工作模式 kubectl get cm kube-proxy -n kube-system -o yaml | grep mode)
userspace(已经弃用): 请求是从用户态-->内核态-->用户态,转发是在用户态进行的,效率不高且容易丢包
iptables(默认的工作模式):
相比于userspace模式免去了一次内核态到用户态的切换!!
1、kube-proxy通过Api-server的watch接口实时监测service和endpoint对象的变化,当有service创建时,kube-proxy在iptables中追加新的规则
2、在该模式下,kube-proxy为service后端的每个pod创建对应的iptables规则,直接将发向cluster ip的请求重定向到一个pod ip
3、在该模式下,kube-proxy不承担四层代理的角色,只负责创建iptables规则
ipvs:
1、kube-proxy ipvs模式是基于NAT实现的,对访问k8s service的请求进行虚拟ip到pod ip的转发
工作原理:
当创建一个svc后,ipvs模式的kube-proxy会做以下三件事
1、确保kube-ipvs0网卡的存在。因为ipvs的netfilter钩子挂载input链.需要把svc的访问IP绑定在该网卡上让内核觉得虚IP就是本机IP,从而进入input链。
2、把svc的访问ip绑定在该网卡上
3、通过socket调用,创建ipvs的虚拟服务和真实服务,分别对应svc和endpoints
注意事项:
ipvs用于流量转发,无法处理kube-proxy中的其他问题,例如把包过滤、SNAT等。因此在以下四种情况下kube-proxy依赖iptables:
1、kube-proxy配置启动参数masquerade-all=true,即集群中所有经过kube-proxy的包都做一次SNAT;
2、kube-proxy启动参数指定集群IP地址范围;
3、支持loadbalance类型的服务
4、支持nodeport类型的服务
iptables和ipvs模式的区别以及优缺点
区别:
1、iptables是Linux系统内置的一种防火墙,可以通过iptables规则来实现包过滤、NAT转发等功能
2、ipvs是由Linux提供的一种仅工作在Linux内核态的4层高性能的负载均衡,通过多种算法实现负载均衡,并支持动态扩展和收缩。支持三种负载均衡模式(性能从高到底分别是DR-->NAT-->ipip,但DR、ipip不支持端口映射无法支撑svc的所有常场景);支持多种负载均衡算法(rr、lc(最小连接)、dh(目的地址哈希)、sh(源地址哈希)、sed(最短时延))
优缺点:
1、iptables优点:
可以通过iptables规则精细地控制流量转发
缺点: 由于线性查找匹配、全量更新的特点,当规则较多时,规则列表会变得很长,导致iptables性能下降,服务器CPU飙高,同时iptables不能处理TCP、UDP的SYN包
2、ipvs的优点在于它使用内核空间实现负载均衡,采用hash表,当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能.
3、在并发为1000时,对比iptables,ipvs在端到端的吞吐率和平均时延方面有30%左右的性能提升.iptables时延为125ms,ipvs为30ms。
4、资源消耗方面,当svc数量为1000个时,ipvs消耗386MB内存、iptables消耗1.1GB内存资源;ipvs消耗0%cpu使用率,而iptables的cpu消耗率在50%左右。
kube-proxy原理剖析
需要明白iptables链路图,结合下图对clusterIP和Nodeport两种暴露模式进行追踪
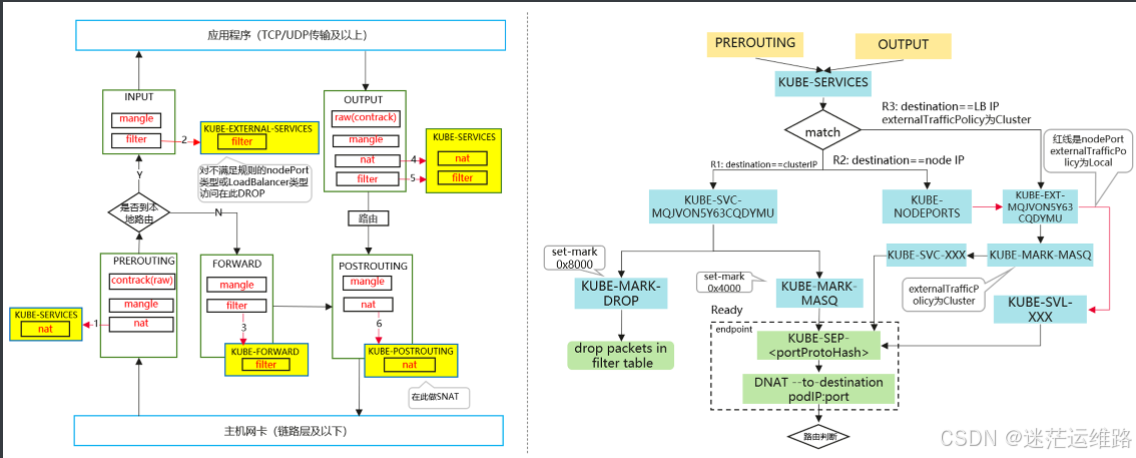
1、首先通过命令curl 127.0.0.1:10249/proxyMode 或者kubectl get pod -n kube-system kube-proxy-5d6bv -oyaml |grep mode 查看kube-proxy所用的规则
一、ClusterIp类型的svc的iptables实现方式
1、kubectl get svc,endpoint -n fast 在node节点上尝试curl一下得到的clusterIp
curl 10.233.201.203
2、iptables -nvL -t nat 查看nat表的PREROUTING链中的KUBE-SERVICE这个链
3、iptables -nv -t nat -L KUBE-SERVICE 查看这条链的规则,找到目的地址是svc地址的那条链
4、iptables -nv -t nat -L 目的地址是svc地址的那条链 可以看到所查找服务的scv具有1~n条规则链,通常第一条规则是Masquerade伪装,即将在某个网段的源地址ip转换为经过的路由节点或经过的网卡ip。其余规则是当访问svc ip时会根据轮询算法将iptables规则随机匹配到不同的target。
总结:
当发起一个clusterIp请求时,`PREROUTING`规则先起作用,然后通过iptables的random模式随机的匹配多条到pod的DNAT规则,从上文也可以看到,这是一个O(n)的算法,也就是工作负载有几个副本,就会创建几个到工作副本的dnat规则和回包时的`Masquerade`规则,当pod数量很多的时候,显然会对k8s集群的压力很大。
通过抓包看到上面的整个分析过程。执行命令 `tcpdump -i any -n host 10.222.154.5`。其中`10.222.154.5` 是其中一个pod的地址。
二、NodePort类型的svc的iptables实现方式
1、kubectl get svc,endpoint -n fast 在node节点上尝试curl一下得到的clusterIp curl 10.233.201.203
2、iptables -nvL -t nat 查看nat表的PREROUTING链中的KUBE-NODEPORTS这个链
3、iptables -nv -t nat -L KUBE-NODEPORTS 当目的端口是暴露的端口时,iptables规则会走向一个链KUBE-SVC-xxxxx
4、iptables -nv -t nat -L 序号3查出来的链 看看查出来的链条规则
5、iptables -nv -t nat -L 查出来的链条 KUBE-SEP-xxx
6、iptables -nv -t nat -L 序号5查出来的链条 可以看到iptables规则DNAT到podIp,没有经过ClusterIp
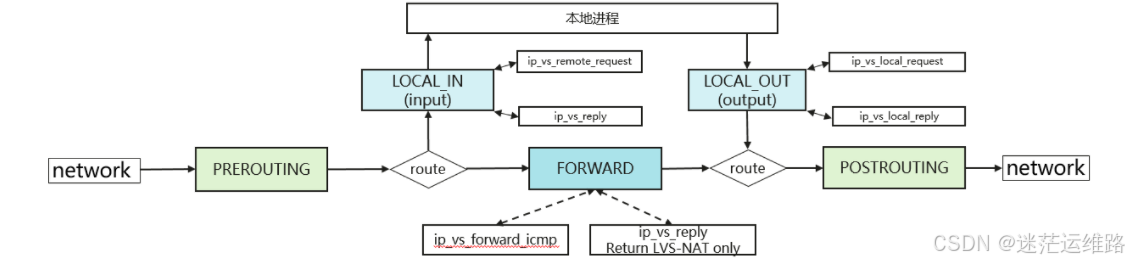
ipvs
ipvs大致原理说明:
ipvs (IP Virtual Server) 是基于 Netfilter 的,作为 linux 内核的一部分实现了传输层负载均衡,ipvs 集成在LVS(Linux Virtual Server)中,它在主机中运行,并在真实服务器集群前充当负载均衡器。ipvs 可以将对 TCP/UDP 服务的请求转发给后端的真实服务器。Netfilter为包过滤提供了5个Hook点,IPVS用到的Hook是LOCAL_IN、FORWARD和LOCAL_OUT
ipvs大致工作流程如下:
1、当用户向负载均衡调度器(Director Server)发起请求,调度器将请求发往至内核空间,经过PREROUTING链;
2、PREROUTING链首先会接收到用户请求,判断目标IP确定是本机IP,将数据包发往INPUT链;
3、ipvs工作于内核空间的INPUT链上,当用户请求到达INPUT时,IPVS会将用户请求和自己已定义好的集群服进行比对,如果用户请求的就是定义的集群服务,那么此时IPVS会强行修改数据包里的目标IP地址及端口,并将新的数据包发往FORWORD链;
4、FORWORD链将数据将数据包发给POSTROUTING链,POSTROUTING链接收数据包后发现目标IP地址刚好是自己的后端服务器,那么此时通过选路,将数据包最终发送给后端的服务器
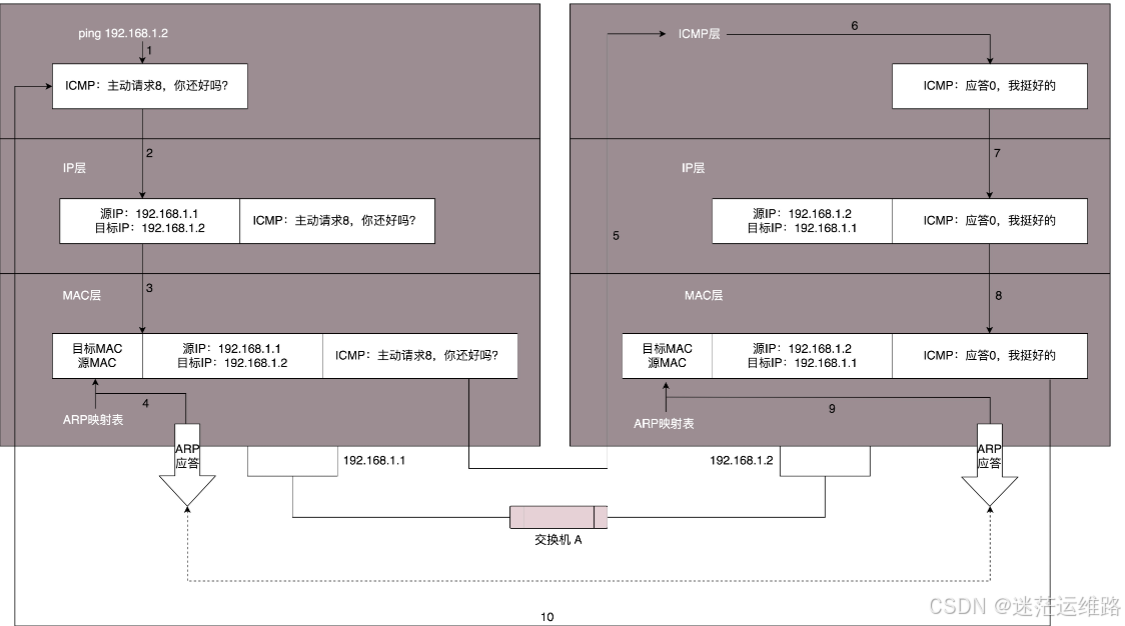
k8s的service是否能ping通?
结论: 在Kubernetes中,ClusterIP/NodePort类型的Service的IP地址是虚拟的,并不分配给任何实体即没有实际的mac地址,因此无法响应ICMP请求,也就是说,它们不能被ping通.这是因为Kubernetes的Service仅仅是一个IP地址和端口的组合,用于负载均衡和服务发现,而不是一个实际的网络接口。
不同类型的service情况不同,ClusterIP/NodePort类型不能ping通,Headless类型能ping通,Loadbalancer和ExternalName则要实现情况可能通也可能不通
原因分析:
1、首先需要了解一下icmp协议,如下如所示,icmp协议用于探测两台主机之间是否能够通信,而icmp是位于网络层的协议,网络层下还有数据链路层【mac地址在这一层进行封装】,主机在接收到一个icmp的【Echo request】请求时,必须回复一个 【Echo replay】才能确认两个主机之间能够通信,但是在回复 【Echo replay】之前,主机会确认请求中的ip是否是自己,以及Mac地址是否是自己的。【然而虚拟IP是没有mac地址的,所有这个数据被直接丢弃了】
ping不通是否跟iptables规则有关?
结论: 这个说法是错误的,与iptables规则没有关系。请看下面的示例分析
分析:
1、查看prerouting链的iptables规则
iptables -nvL -t nat |grep PREROUTING
2、查看k8s某个命名空间下svc的KUBE-SERVICES链
iptables -nv -t nat -L KUBE-SERVICES
3、查看该svc 对应KUBE-SERVICES链下的规则
iptables -nv -t nat -L KUBE-SVC-LQAP36MZ3JRXFSQX
如下图1
4、查看该KUBE-SVC-LQAP36MZ3JRXFSQX链下的规则
iptables -nv -t nat -L KUBE-SEP-U4FC5Z6HXBLC66K3
如下图2,,iptables并没有拒绝icmp协议的数据包,只针对该service的tcp协议做了流量转发,并没有对其他协议进行额外处理,因此与iptables规则无关.


为什么ipvs的的clusterIP类型的service能够ping通?
原因:
因为ipvs将所有的clusterIP都设置在了一个kube-ipvs0的网卡上不再是虚拟IP,它有了自己的mac地址,因此在进行ping操作时,在mac地址这一层进行了封装,所有才能通
如下所示
51: ipvs0: <BROADCAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether ce:8b:5d:28:59:28 brd ff:ff:ff:ff:ff:ff
inet 172.20.42.51/22 scope global ipvs0
valid_lft forever preferred_lft forever
inet6 fe80::cc8b:5dff:fe28:5928/64 scope link
valid_lft forever preferred_lft forever
ingress部分
https://blog.youkuaiyun.com/L2111533547/article/details/126248597
类似于7层负载均衡,解决在集群之外访问集群内部的service服务的问题,并且将来自不同域名的请求转发到不同的service上,也可以将同一请求根据不同URL接口转发到不同的service上。
ingress controller 是通过API server获取ingress资源的变化。同时也是流量的入口,相当于nginx和haproxy。
常见的ingress-controller有以下几种:
1、ingress controller 由nginx kubernetes官方维护
2、ingress kong 由著名的api gateway方案维护
3、traefik 一套开源的http反向代理与负载均衡器
4、F5硬件负载
ingress工作原理:
(1)ingress-controller通过和 kubernetes APIServer 交互,动态的去感知集群中ingress规则变化,
(2)然后读取它,按照自定义的规则,规则就是写明了哪个域名对应哪个service,生成一段nginx配置,
(3)再写到nginx-ingress-controller的pod里,这个ingress-controller的pod里运行着一个Nginx服务,控制器会把生成的 nginx配置写入 /etc/nginx.conf文件中,
(4)然后reload一下使配置生效。以此达到域名区分配置和动态更新的作用。
在使用普通的Service时,集群中每个节点的kube-proxy在监听到Service和Endpoints的变化时,会动态的修改相关的iptables的转发规则。 客户端在访问时通过iptables设置的规则进行路由转发达到访问服务的目的。
而Ingress则跳过了kube-proxy这一层,通过Ingress Controller中的代理配置进行路由转发达到访问目标服务的目的。
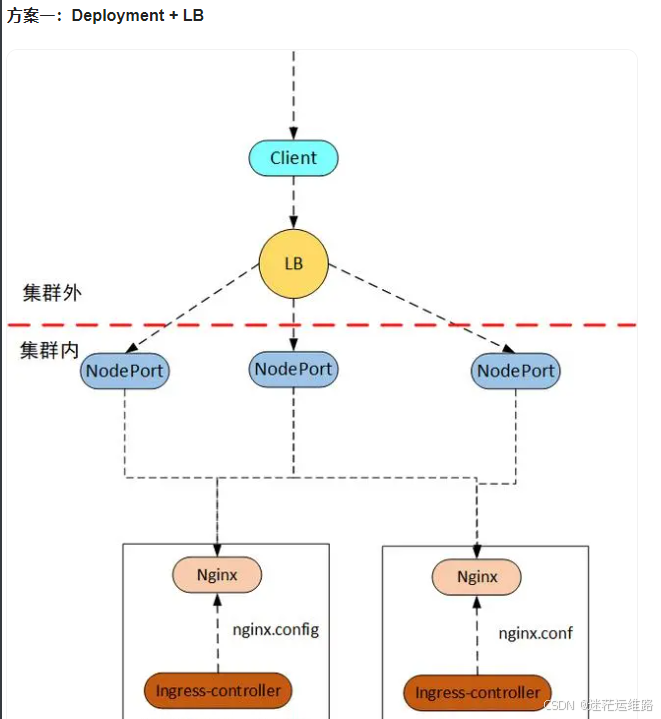
ingress 暴露服务的三种方式:
方式一: Deployment的ingress + LoadBalancer模式的ingress-nginx-controller的Service,如上图
如果要把ingress部署在公有云,那用这种方式比较合适。用Deployment部署ingress-controller,创建一个 type为 LoadBalancer 的 service 关联这组 pod。大部分公有云,都会为 LoadBalancer 的 service 自动创建一个负载均衡器,通常还绑定了公网地址。只要把域名解析指向该地址,就实现了集群服务的对外暴露
示例:
1、提前部署deployment类型的ingress-controller和LoadBalancer模式的ingress-nginx-controller的Service
2、首先,您需要创建一个 Deployment,并将应用程序部署到 Kubernetes 中。例如,您可以使用以下 YAML 文件来创建一个部署名为 my-app 的 nginx 应用程序:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
selector:
matchLabels:
app: my-app
replicas: 3
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx:1.21.1
ports:
- containerPort: 80
接着创建nodeport类型的svc
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
selector:
app: my-app
type: nodeport
ports:
- protocol: TCP
port: 80
targetPort: 80
接着创建一个ingress,使用域名来访问服务
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-app-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: my-app.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: my-app-service
port:
name: http
需要将这个host域名在域名注册商(阿里云、京东云)或者DNS服务托管商中找到域名解析配置界面,创建一个A记录,将这个域名映射到loadbalance这个负载均衡ip上,然后就可以使用域名来访问服务了
ingress 暴露服务的三种方式:
方式二: Daemonset的ingress+NodePort模式的nginx-ingress-controller的Service
0、提前部署deployment类型的ingress+NodePort模式的nginx-ingress-controller的Service
1、首先,您需要创建一个运行在 Kubernetes 中的 Deployment。例如,我们可以创建一个名为 `my-app-deployment` 的 Deployment,运行一个名为 `my-app` 的容器镜像,并指定所需的 CPU 和内存资源(这里只展示示例,请根据您自己的应用程序进行相应的修改):
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-deployment
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: my-app-image:v1
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
ports:
- containerPort: 80
这会创建一个包含 3 个副本的 Deployment,并将所有标签为 `app=my-app` 的 Pod 映射到这个 Deployment 中。每个 Pod 都会运行一个名为 `my-app` 的容器,并公开容器端口 80,以便外部流量可以访问该容器。请注意,此处使用的容器镜像名称仅供示例,您需要根据自己的应用程序镜像进行适当的修改。
2. 接下来,我们需要为这个 Deployment 创建一个 Service,使它能够从外部访问。我们可以使用 NodePort 模式来创建这个 Service,这样就可以在每个节点上暴露容器端口,以便外部流量可以通过节点的公共 IP 地址访问到它。在这个示例中,我们创建一个名为 `my-app-service` 的 NodePort Service,将其映射到 Deployment 中所有标签为 `app=my-app` 的 Pod 上,并将其公开为 TCP 端口 30080(同样是为了示例,请根据您自己的需求进行修改):
apiVersion: v1
kind: Service
metadata:
name: my-app-service
spec:
type: NodePort
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 80
nodePort: 30080
这会创建一个名为 `my-app-service` 的 Service,并将其类型设置为 `NodePort`。该 Service 将所有标签为 `app=my-app` 的 Pod 映射到一个内部的 ClusterIP,然后将外部流量绑定到 TCP 端口 30080 上。请注意,NodePort 的范围通常在 30000-32767 之间,因此您需要确保选择一个未被占用的端口,或者根据您自己的需要进行相应的修改。
3. 最后,我们可以使用 ingress 对 Service 进行暴露并配合域名进行访问。例如,我们创建一个名为 `my-app-ingress` 的 Ingress 资源,并将它指定为引导流量到我们的 Service 上,同时将域名设置为 `my-app.example.com`:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-app-ingress
spec:
rules:
- host: my-app.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: my-app-service
port:
name: http
通过这个 Ingress 规则,我们可以将来自 `my-app.example.com` 域名的 HTTP 请求路由到名为 `my-app-service` 的 NodePort Service 上,并将其绑定到容器端口 80。请注意,这里使用的 Service 端口名称为 `http`,这需要与前面定义的节点端口号一致。
现在,您已经成功地创建了一个使用 Deployment+NodePort 模式的 Service,并将其暴露在 Kubernetes 中。外部流量可以通过节点的公共 IP 地址和端口号(例如 `http://<node-ip>:30080`)访问您的应用程序。如果您配置了正确的 DNS 记录,也可以通过 `http://my-app.example.com` 域名进行访问。
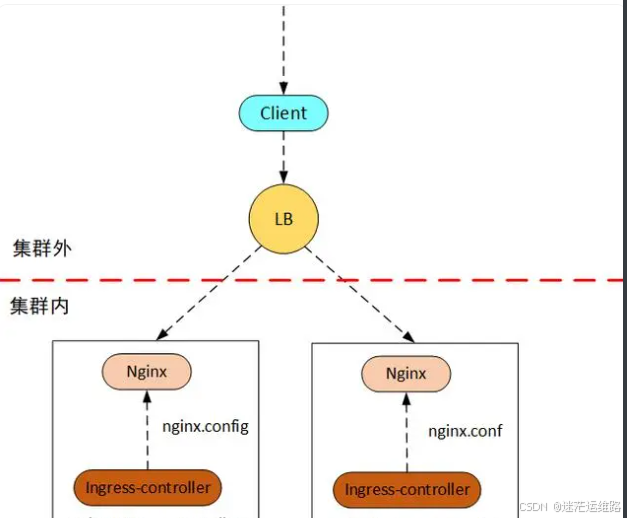
ingress 暴露服务的三种方式:
方式三: Daemonset的ingress+hostnetwork+loadbalance模式的svc的ingress-ngixn-controller,如上图
1、部署daemonset类型的ingress-nginx-controller,并且指定以下配置,专门使用2--3台 <node> 机器来部署这个daemonset类型的ingress-nginx-controller
hostNetwork: true #使用主机网络
nodeSelector:
ingress: "true" #选择节点运行,节点有标签ingress=true
2、准备一个nginx服务
apiVersion: v1
kind: Namespace
metadata:
name: my-nginx #创建名称空间
---
apiVersion: apps/v1 #与k8s集群版本有关,使用 kubectl api-versions 即可查看当前集群支持的版本
kind: Deployment #该配置的类型,我们使用的是 Deployment
metadata: #译名为元数据,即 Deployment 的一些基本属性和信息
name: nginx-deployment #Deployment 的名称
namespace: my-nginx
labels: #标签,可以灵活定位一个或多个资源,其中key和value均可自定义,可以定义多组,目前不需要理解
app: nginx #为该Deployment设置key为app,value为nginx的标签
spec: #这是关于该Deployment的描述,可以理解为你期待该Deployment在k8s中如何使用
replicas: 3 #使用该Deployment创建一个应用程序实例
selector: #标签选择器,与上面的标签共同作用,目前不需要理解
matchLabels: #选择包含标签app:nginx的资源
app: nginx
template: #这是选择或创建的Pod的模板
metadata: #Pod的元数据
labels: #Pod的标签,上面的selector即选择包含标签app:nginx的Pod
app: nginx
spec: #期望Pod实现的功能(即在pod中部署)
containers: #生成container,与docker中的container是同一种
- name: nginx #container的名称
image: nginx:1.7.9 #使用镜像nginx:1.7.9创建container,该container默认80端口可访问
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service #Service 的名称
namespace: my-nginx
labels: #Service 自己的标签
app: nginx #为该 Service 设置 key 为 app,value 为 nginx 的标签
spec: #这是关于该 Service 的定义,描述了 Service 如何选择 Pod,如何被访问
selector: #标签选择器
app: nginx #选择包含标签 app:nginx 的 Pod
ports:
- name: nginx-port #端口的名字
protocol: TCP #协议类型 TCP/UDP
port: 8081 #集群内的其他容器组可通过 80 端口访问 Service
targetPort: 80 #将请求转发到匹配 Pod 的 80 端口
type: ClusterIP #Serive的类型,ClusterIP/NodePort/LoaderBalancer
3、在使用ingress规则进行代理
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-ingress
namespace: my-nginx #ingress部署到需要转发的namespace
annotations:
kubernetes.io/ingress.class: "nginx" # 指定 Ingress 控制器的类名称,在部署ingress-nginx-controller的yaml中可见- --ingress-class=nginx
nginx.ingress.kubernetes.io/rewrite-target: / #这样可以在转发请求之前修改路径,如将下面的/testNginx, 改为/, 否则nginx-service收到的请求依旧会包含/testNginx
spec:
rules:
- host: www.liang.com #域名,只能是域名,支持通配符(*.foo.com)
http:
paths:
- path: /testNginx
pathType: Prefix #路径匹配类型,可见https://kubernetes.io/zh-cn/docs/concepts/services-networking/ingress/
backend:
service:
name: nginx-service #要转发到那个service
port:
number: 8081 #service的端口
---
三种方式对比:
方式一与方式二:
虽然简单,但是流量会经过一层 NodePort,会多一层转发。这种方式有一些缺点: 转发路径较长,流量到了 NodePort 还会再经过 Kubernetes 内部负载均衡,通过 Iptables 或 IPVS 转发到 Nginx,会增加一点网络耗时。经过 NodePort 必然发生 SNAT,如果流量过于集中容易导致源端口耗尽或者 conntrack 插入冲突导致丢包,引发部分流量异常。
每个节点的 NodePort 也充当一个负载均衡器,CLB 如果绑定大量节点的 NodePort,负载均衡的状态就分散在每个节点上,容易导致全局负载不均。CLB 会对 NodePort 进行健康探测,探测包最终会被转发到 Nginx Ingress 的 Pod,如果 CLB 绑定的节点多,Nginx Ingress 的 Pod 少,会导致探测包对 Nginx Ingress 造成较大的压力。
方式三: 因为采用了hostnetwork,因此会直接使用部署了nginx-ingress-controller的两台节点服务器取访问。该方式整个请求链路最简单
ingress规则中pathType三种类型对比:
ImplementationSpecific: 对于这种路径类型,匹配方法取决于 IngressClass。 具体实现可以将其作为单独的 pathType 处理或者作与 Prefix 或 Exact 类型相同的处理。
Exact: 精确匹配 URL 路径,且区分大小写。
Prefix: 基于以 / 分隔的URL路径前缀匹配。匹配区分大小写,并且对路径中各个元素逐个执行匹配操作。 路径元素指的是由 / 分隔符分隔的路径中的标签列表。 如果每个 p 都是请求路径 p 的元素前缀,则请求与路径 p 匹配。
Ingress annotations详解
annotations推荐:
https://www.w3ccoo.com/nginx/nginx_ingress_annotations.asp
案例引入:
某项目在转维期时,被客户漏扫发现了swagger Api未授权访问漏洞,通过http://sso.espic.com.cn/sso/v2/api-docs路径可以查看到相关的接口信息,因此急需要修复此漏洞。但是因为已经转维且没有对应的研发支持,因为只能从访问链路入手进行修复。前提是服务都部署在k8s集群中
修复过程:
1、登录环境,查看该域名配置的ingressName
2、ingress配置如下所示:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
nginx.ingress.kubernetes.io/proxy-body-size: 10M
name: userorg-ingress
namespace: ms
spec:
rules:
- host: sso.espic.com.cn
http:
paths:
- backend:
serviceName: sso-nginx-service
servicePort: 80
path: /
pathType: ImplementationSpecific
3、当时想到的第一种办法,在添加一个backend,配合ingress-annotions中的rewrite进行转发,如下所示将swagger的接口路径转发到一个不存在的路径上去。结果配置后,导致访问http://sso.espic.com.cn/也访问失败,为了不影响线上业务,紧急回滚对应的ingress yaml配置
metadata:
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /my-new-app
- backend:
serviceName: sso-nginx-service
servicePort: 80
path: /sso/v2/api-docs
pathType: ImplementationSpecific
4、为了解决步骤3出现的404问题,接着查找ingress-annotations的相关资料,功夫不负有心人,请看VCR https://www.w3ccoo.com/nginx/nginx_ingress_annotations.asp 在这里找到了以下示例,然后再次查资料了解到nginx.ingress.kubernetes.io/configuration-snippet主要作用于nginx的location中,那么就意味着location中能指定的这里也能指定。
annotations:
nginx.ingress.kubernetes.io/configuration-snippet: |
proxy_header Host $host
5、有了第四步的资料作为支撑,开始处理问题。修改现有的userorg-ingress文件,添加以下配置
annotations:
nginx.ingress.kubernetes.io/configuration-snippet: |
rewrite ^/sso/v2/api-docs(.*)$ /swagger-forbid$1 break; 匹配以^/sso/v2/api-docs开头,并且以任意字符结尾的路径,将其重定向到/swagger-forbid,并保留后边的部分
$1的理解: 表示匹配到第一个括号内的内容。其中(.*)表示匹配任意字符,当匹配到了/sso/v2/api-docs后,括号内的内容则会被$1所匹配
6、验证漏洞是否修复
Ingress采用https方式访问
https://blog.youkuaiyun.com/weixin_45423952/article/details/118462939
https://help.aliyun.com/document_detail/93804.html?spm=a2c4g.11174283.6.900.74544c07fm9Xx9
详情见上述文档
service部分
service的作用
1、服务发现
两种方式: 环境变量、DNS(svc名.命名空间.svc.cluster.local)
2、负载均衡
真正实现负载均衡和服务发现的是k8s中运行在每个node节点的kube-proxy组件
service分发后端的策略
1、RoundRobin: 默认为轮询,将请求转发到后端的各个pod上
2、SessionAffinity: 基于客户端IP地址进行会话保持的模式
可选值是ClientIP或None。默认值为None,表示以round-robin方式将请求转发到后端Pod,若值为ClientIP表示保持连接,请求始终会被调度到同一个Pod上
什么是service
类似于四层负载均衡,service会对提供同一个服务的多个pod进行聚合,并提供一个统一的入口地址管理pod。在service中真正起作用的是kube-proxy服务进程,当创建service资源的时候会通过api-server向etcd写入创建service的信息,当kube-proxy的监听机制发现service的变动时,会将最新的service信息转换成为对应的访问规则。
service常用类型
1、ClusterIp 在集群内部使用,默认使用clusterIp
2、NodePort 在所有安装了kube-proxy的节点上打开一个端口,此端口代理后端pod端口,通过该端口可以在集群外部进行访问
3、externalName 通过返回定义的Cname别名,解析svc的名字就可以进行访问(集群内部访问集群外部的服务或API)
4、LoadBalance 使用云供应商提供的负载均衡器
svc中的containerPort、port、nodePort、targetPort的区别与联系
containerPort:
Container容器暴露的端口。containerPort是在pod控制器中定义的、pod中的容器需要暴露的端口。
port:
service暴露在集群中的端口,仅限集群内部访问。port是暴露在cluster(集群网络)上的端口,提供了集群内部客户端访问service的入口,即clusterIP:port。mysql容器暴露了3306端口(参考DockerFile),集群内其他容器通过33306端口访问mysql服务,但是外部流量不能访问mysql服务,因为mysql服务没有配置NodePort。
nodePort:
集群节点Node暴露在外网中的端口。nodePort提供了集群外部客户端访问service的一种方式,即nodeIP:nodePort提供了外部网络访问k8s集群中service的入口。
targetPort:
Pod暴露的端口。targetPort是pod上的端口,从port/nodePort下来的数据,经过kube-proxy流入到后端pod的targetPort上,最后进入容器,因此targetPort与容器的containerPort必须一致。
service使用场景–使用k8s代理外部应用
1、在生产环境使用某个固定名称而非ip地址来进行访问外部某个中间件服务
2、service指向另一个Namespace中或其他集群中的服务
3、某个项目正在迁移,但是一部分服务仍在集群外部,此时就可以使用service来代理k8s集群外部的服务
方法:
1、创建svc资源,且删除掉svc中的selector配置;
2、创建endpod资源,配置文件中的name必须和svc的名称一样,这样才能让ep和svc关联在一起。并且指定文件中的外部ip地址。
例如: service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx-svc-external
name: nginx-svc-external
spec:
ports:
- name: http
port: 80 port提供了集群内部客户端访问service的入口
protocol: TCP
targetPort: 80 targetPort是pod上的端口,从port/nodePort上来的数据,经过kube-proxy流入到后端pod的targetPort上,最后进入容器
sessionAffinity: None 会话保持
type: ClusterIp
endpoint.yaml
apiVersion: v1
kind: Endpoints
metadata:
labels:
app: nginx-svc-external
name: nginx-svc-external(这里必须和svc保持一致)
subsets:
- addresses:
- ip: 39.156.69.79(外部服务地址)
ports:
- name: http
port: 80
protocol: TCP(这里也必须和svc中保持一致)
使用kubectl get svc 和kubectl get ep 查看ip地址
创建完成后,直接curl svc的ip地址,即可访问到外部服务
使用svc反代外部域名
svc.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx-svc-externalname
name: nginx-svc-externalname
spec:
type: ExternalName
externalName: www.baidu.com(外部域名)
无头svc,详情见以下博客:
https://blog.youkuaiyun.com/zjz5740/article/details/115652274
容器退出状态码总结
什么是容器退出码?
当容器终止时,容器引擎使用退出码来报告容器终止的原因。如果您是 Kubernetes 用户,容器故障是 pod 异常最常见的原因之一,了解容器退出码可以帮助您在排查时找到 pod 故障的根本原因。
为了更好地理解容器故障的原因,让我们先讨论容器的生命周期。以 Docker 为例在任何给定时间,Docker 容器都会处于以下几种状态之一:
Created: Docker 容器已创建但尚未启动(这是运行 docker create 后但实际运行容器之前的状态)
Up: Docker 容器当前正在运行。这意味着容器管理的操作系统进程正在运行。当您使用命令 docker start 或 docker run 时会发生这种情况,使用 docker start 或 docker run 可能会发生这种情况。
Paused: 容器进程正在运行,但 Docker 暂停了容器。通常,当您运行 docker pause 命令时会发生这种情况
Exited: Docker 容器已经被终止,通常是因为容器的进程被杀死了当一个容器达到 Exited 状态时,Docker 会在日志中报告一个退出码,告诉你容器发生了什么导致它退出。
常见的容器退出状态码
| 退出码 | 名称 | 含义 |
|---|---|---|
| 0 | 正常退出 | 开发者用来表明容器是正常退出 |
| 1 | 应用错误 | 容器因应用程序错误或镜像规范中的错误引用而停止 |
| 125 | 容器未能运行 | docker run 命令没有执行成功 |
| 126 | 命令调用错误 | 无法调用镜像中指定的命令 |
| 127 | 找不到文件或目录 | 找不到镜像中指定的文件或目录 |
| 128 | 退出时使用的参数无效 | 退出是用无效的退出码触发的(有效代码是 0-255 之间的整数) |
| 134 | 异常终止 (SIGABRT) | 容器使用 abort() 函数自行中止 |
| 137 | 立即终止 (SIGKILL) | 容器被操作系统通过 SIGKILL 信号终止 |
| 139 | 分段错误 (SIGSEGV) | 容器试图访问未分配给它的内存并被终止 |
| 143 | 优雅终止 (SIGTERM) | 容器收到即将终止的警告,然后终止 |
| 255 | 退出状态超出范围 | 容器退出,返回可接受范围之外的退出代码,表示错误原因未知 |
退出码 0: 正常退出
退出代码 0 由开发人员在任务完成后故意停止容器时触发。从技术上讲,退出代码 0 意味着前台进程未附加到特定容器。
如果容器以退出码 0 终止怎么办?
1、检查容器日志,确定哪个库导致容器退出;
2、查看现有库的代码,并确定它触发退出码 0 的原因,以及它是否正常运行。
退出码 1: 应用错误
退出代码 1 表示容器由于以下原因之一停止:
应用程序错误: 这可能是容器运行的代码中的简单编程错误,例如“除以零”,也可能是与运行时环境相关的高级错误,例如 Java、Python 等;
无效引用: 这意味着镜像规范引用了容器镜像中不存在的文件。
如果容器以退出码 1 终止怎么办?
1、检查容器日志以查看是否找不到映像规范中列出的文件之一。如果这是问题所在,请更正镜像以指向正确的路径和文件名。
2、如果您找不到不正确的文件引用,请检查容器日志以查找应用程序错误,并调试导致错误的库
退出码 125: 容器未能运行
退出码 125 表示该命令用于运行容器。例如 docker run 在 shell 中被调用但没有成功执行。以下是可能发生这种情况的常见原因:
1、命令中使用了未定义的 flag,例如 docker run --abcd;
2、镜像中用户的定义命令在本机权限不足;
3、容器引擎与宿主机操作系统或硬件不兼容。
如果容器以退出码 125 终止怎么办?
1、检查运行容器的命令语法是否正确;
2、检查运行容器的用户,或者镜像中执行命令的上下文,是否有足够的权限在宿主机上创建容器;
如果您的容器引擎提供了运行容器的 option,请尝试它们。例如,在 Docker 中,尝试 docker start 而不是 docker run;
测试您是否能够使用相同的用户名或上下文在主机上运行其他容器。如果不能,重新安装容器引擎,或者解决容器引擎和主机设置之间的底层兼容性问题。
退出码 126: 命令调用错误
退出码 126 表示无法调用容器镜像中使用的命令。这通常是用于运行容器的持续集成脚本中缺少依赖项或错误的原因。
如果容器以退出码 126 终止怎么办?
1、检查容器日志,查看无法调用哪个命令;
2、尝试在没有命令的情况下运行容器以确保隔离问题;
3、对命令进行故障排除以确保您使用正确的语法,并且所有依赖项都可用;
4、更正容器规范并重试运行容器
退出码 127: 找不到文件或目录
退出码 127 表示容器中指定的命令引用了不存在的文件或目录。
如果容器以退出码 127 终止怎么办?
与退出码 126 相同,识别失败的命令,并确保容器镜像中引用的文件名或文件路径真实有效。
退出码 128: 退出时使用的参数无效
退出码 128 表示容器内的代码触发了退出命令,但没有提供有效的退出码。 Linux exit 命令只允许 0-255 之间的整数,因此如果进程以退出码 3.5 退出,则日志将报告退出代码 128。
如果容器以退出码 128 终止怎么办?
1、检查容器日志以确定哪个库导致容器退出。
2、确定有问题的库在哪里使用了 exit 命令,并更正它以提供有效的退出代码
退出码 134: 异常终止 (SIGABRT)
退出码 134 表示容器自身异常终止,关闭进程并刷新打开的流。此操作是不可逆的,类似 SIGKILL
(请参阅下面的退出码 137)。进程可以通过执行以下操作之一来触发 SIGABRT:
1、调用 libc 库中的 abort() 函数;
2、调用 assert() 宏,用于调试。如果断言为假,则该过程中止。
如果容器以退出码 134 终止怎么办?
1、检查容器日志,查看哪个库触发了 SIGABRT 信号;
2、检查中止进程是否是预期内的(例如,因为库处于调试模式),如果不是,则对库进行故障排除,并修改以避免中止容器
退出码 137: 立即终止 (SIGKILL)
退出码 137 表示容器已收到来自主机操作系统的 SIGKILL 信号。该信号指示进程立即终止,没有宽限期。可能的原因是:
1、当通过容器引擎杀死容器时触发,例如使用 docker kill 命令时;
2、由 Linux 用户向进程发送 kill -9 命令触发;
3、在尝试终止容器并等待 30 秒的宽限期后由 Kubernetes 触发(默认情况下);
4、由主机自动触发,通常是由于内存不足。在这种情况下,docker inspect命令将指示 OOMKilled 错误。
如果容器以退出码 137 终止怎么办?
1、检查主机上的日志,查看在容器终止之前发生了什么,以及在接收到 SIGKILL 之前是否之前收到过 SIGTERM 信号(优雅终止);
2、如果之前有 SIGTERM 信号,请检查您的容器进程是否处理 SIGTERM 并能够正常终止;
3、如果没有 SIGTERM 并且容器报告了 OOMKilled 错误,则排查主机上的内存问题。
退出码 139: 分段错误 (SIGSEGV)
退出码 139 表示容器收到了来自操作系统的 SIGSEGV 信号。这表示分段错误 —— 内存违规,由容器试图访问它无权访问的内存位置引起。SIGSEGV 错误有三个常见原因:
1、编码错误:容器进程没有正确初始化,或者它试图通过指向先前释放的内存的指针来访问内存
2、二进制文件和库之间不兼容:容器进程运行的二进制文件与共享库不兼容,因此可能会尝试访问不适当的内存地址
3、硬件不兼容或配置错误:如果您在多个库中看到多个分段错误,则主机上的内存子系统可能存在问题或系统配置问题
如果容器以退出码 139 终止怎么办?
1、检查容器进程是否处理 SIGSEGV。在 Linux 和 Windows 上,您都可以处理容器对分段错误的响应。例如,容器可以收集和报告堆栈跟踪;
2、如果您需要对 SIGSEGV 进行进一步的故障排除,您可能需要将操作系统设置为即使在发生分段错误后也允许程序运行,以便进行调查和调试。然后,尝试故意造成分段错误并调试导致问题的库;
3、如果您无法复现问题,请检查主机上的内存子系统并排除内存配置故障
退出码 143: 优雅终止 (SIGTERM)
退出码 143 表示容器收到来自操作系统的 SIGTERM 信号,该信号要求容器正常终止,并且容器成功正常终止(否则您将看到退出码 137)。该退出码可能的原因是:
1、容器引擎停止容器时触发,例如使用 docker stop 或 docker-compose down 命令时;
2、由 Kubernetes 将 Pod 设置为 Terminating 状态触发,并给容器 30 秒的时间以正常关闭。
如果容器以退出码 143 终止怎么办?
1、检查主机日志,查看操作系统发送 SIGTERM 信号的上下文。如果您使用的是 Kubernetes,请检查 kubelet 日志,查看 pod 是否以及何时关闭。
一般来说,退出码 143 不需要故障排除。这意味着容器在主机指示后正确关闭。
退出码 255: 退出状态超出范围
当您看到退出码 255 时,意味着容器的 entrypoint 以该状态停止。这意味着容器停止了,但不知道是什么原因。
如果容器以退出码 255 终止怎么办?
1、如果容器在虚拟机中运行,首先尝试删除虚拟机上配置的 overlay 网络并重新创建它们。
2、如果这不能解决问题,请尝试删除并重新创建虚拟机,然后在其上重新运行容器。
3、如果上述操作失败,则 bash 进入容器并检查有关 entrypoint 进程及其失败原因的日志或其他线索。
退出状态码区间:
如果退出代码为 0:容器正常退出,无需排查
如果退出代码在 1-128 之间:容器因内部错误而终止,例如镜像规范中缺少或无效的命令
如果退出代码在 129-255 之间:容器因操作信号而停止,例如 SIGKILL 或 SIGINT
如果退出代码是 exit(-1)或 0-255 范围之外的另一个值,kubectl将其转换为 0-255 范围内的值
pod部分
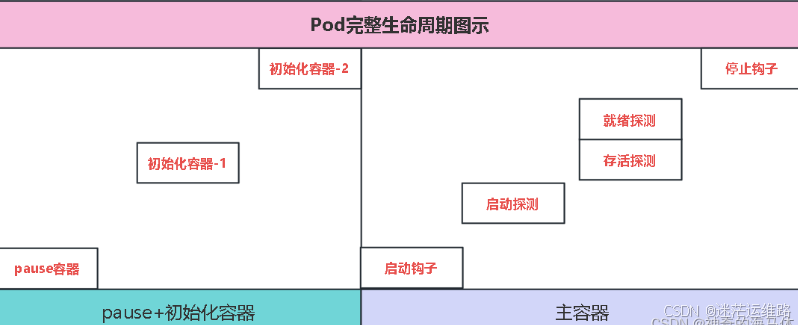
0、pause容器
1、什么是pause容器?
Pause 容器,又叫 Infra 容器,
2、pause容器的作用
在 pod 中担任 Linux 命名空间共享的基础:
网络命名空间隔离
进程隔离
资源隔离
IP地址维护
生命周期管理
启用 pid 命名空间,开启 init 进程。
1、pod生命周期的重要行为
初始化容器
运行生命周期钩子函数(poststart、poststop)
容器存活探测(三种方式: execaction、tcpsocketaction、httpgetaction)
探测结果三种: success、failure、unknown
kubelet可在活动容器上执行两种类型的检测:
存活性检测(livenessprobe)
就绪性检测(readinessprobe)
initContainer初始化容器配置示例
#场景: 容器中的pod接入skywalking链路追踪,前提是通过Dockerfile将skywalking-agent官网镜像进行二次封装
containers:
- env:
- name: SW_OPTS #保持不变
value: -javaagent:/export/server/skywalking/agent/skywalking-agent.jar
- name: SW_AGENT_NAME #保持不变
value: $app_name
- name: SW_AGENT_COLLECTOR_BACKEND_SERVICES #保持不变
value: 10.233.1.34:11800 #此处的ip是skywalking-oap-server的svcip地址
- name: SW_LOGGING_DIR #保持不变
value: /data/Logs/
- name: SW_METER_MAX_METER_SIZE #保持不变
value: "200"
- name: SW_JDBC_TRACE_SQL_PARAMETERS
value: "true"
- name: SKYWING_DEBUG
value: "true"
- name: SW_JMX_OPTS #保持不变,与dokcerfile中定义的保持一致
value: -javaagent:/export/server/skywalking/agent/jmx_prometheus_javaagent-0.16.1.jar=19000:/export/server/skywalking/agent/config.yaml
- name: MY_POD_IP #通过设置容器的环境变量字段拿到容器对应的ip地址,修改对应的start.sh中的ip变量
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: MY_POD_NAME # 获取pod名称,拿到pod名称可以修改对应的start.sh中的变量
valueFrom:
fieldRef:
fieldPath: metadata.name
volumeMounts:
- mountPath: /data/Logs
name: logs
- mountPath: /export/server/skywalking/
name: skywalking-agent
- mountPath: /usr/local/lib/python3.9/dist-packages/certifi/
name: certifi
- mountPath: /usr/local/lib/python3.9/dist-packages/requests/
name: requests
- mountPath: /usr/local/lib/python3.9/dist-packages/chardet/
name: chardet
- mountPath: /usr/local/lib/python3.9/dist-packages/idna/
name: idna
- mountPath: /usr/local/lib/python3.9/dist-packages/urllib3/
name: urllib3
- mountPath: /export/server/
name: promsh
readOnly: false
initContainers:
- args:
- -c
- cp -R /skywalking/agent /agent/ && cp -R /skywalking/agent/certifi /certifi/ && cp -R /skywalking/agent/requests /requests/ && cp -R /skywalking/agent/chardet /chardet/ && cp -R /skywalking/agent/idna /idna/ && cp -R /skywalking/agent/urllib3 /urllib3/
command:
- /bin/sh
image: ds.harbor.com/skywalking/skywalking-agent-jmx-consul:8.0.0
imagePullPolicy: IfNotPresent
name: agent-container
volumeMounts:
- mountPath: /agent
name: skywalking-agent
- mountPath: /certifi
name: certifi
- mountPath: /requests
name: requests
- mountPath: /chardet
name: chardet
- mountPath: /idna
name: idna
- mountPath: /urllib3
name: urllib3
volumes:
- name: promsh
configMap:
name: promsh
- hostPath:
path: /data/Logs
type: DirectoryOrCreate
name: logs
- emptyDir: {}
name: skywalking-agent
- emptyDir: {}
name: certifi
- emptyDir: {}
name: requests
- emptyDir: {}
name: chardet
- emptyDir: {}
name: idna
- emptyDir: {}
name: urllib3
hostPath的type类型规则种类有以下几种
| 空字符串(默认值),用于向后兼容性,这意味着在安装主机路径上不会执行任何检查 | |
|---|---|
| DirectoryOrCreate | 如果给定路径中不存在任何内容,则根据需要在那里创建一个空目录,权限设置为0755,与kubelet拥有相同的组和所有权 |
| Directory | 目录必须存在于指定路径上 |
| FileOrCreate | 如果给定路径中不存在任何内容,则根据需要在那里创建一个空文件,权限设置为0644,与kubelet拥有相同的组和所有权 |
| File | 文件必须存在于指定路径上 |
| sockt | 给定路径上必须存在一个unix链接 |
| CharDevice | 字符设备必须存在于给定路径中 |
| BlockDevice | 块设备必须存在于给定路径中 |
2、pod创建过程
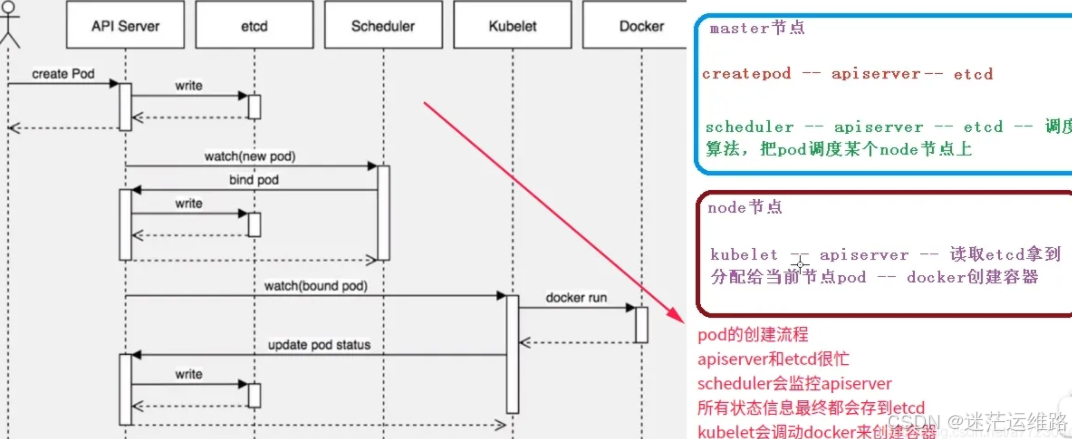
用户通过kubectl或其他api客户端提交pod spec给apiserver
apiserver将pod对象的相关信息存入etcd中,待写入操作执行完成,apiserver会返回确认信息给客户端
apiserver开始反应etcd的状态变化
controller-manager组件使用watch接口来跟踪检查apiserver上的相关变动
kube-scheduler通过其watch接口察觉到apiserver创建了新的pod对象但尚未绑定至任何工作节点
kube-scheduler为pod对象挑选一个工作节点并将结果信息更新至apiserver
调度结果信息由apiserver更新到etcd中,同时apiserver开始反映pod对象的调度结果
pod被调度到目标工作节点上的kubelet尝试在当前节点上调用CNI接口给pod创建网络,调用CRI接口去启动容器,调用CSI进行存储卷的挂载,并将容器状态结果返回给apiserver
apiserver将pod状态信息存入etcd中
在etcd确认写入操作成功完成后,apiserver将确认信息发给相关的kubelet来调动docker创建容器
3、pod终止过程
用户发出删除pod命令
api服务器中的pod对象会随着时间的推移而更新
将pod标记为terminating状态
kubelet在监控到pod对象转为terminating状态的同时启动pod关闭过程
端点控制器监控到pod对象的关闭行为时将其从所有匹配到此端点的service资源的端点(endpoint)列表中移除
如果pod定义了prestop钩子处理器,则其标记为terminating后会以同步的方式启动执行;若宽限期结束后,prestop仍未结束,则第二步会被重新执行并额外获取一个时长2s的小宽限期
pod对象中的容器进程收到TERM信号
宽限期结束后,若存在任何一个仍在运行的进程,那么pod对象即会收到sigkill信号
kubelet请求apiserver将此pod资源的宽限期设置为0从而完成删除操作。
4、pod的重启策略
always 总是重启
Onfailure 失败就重启
Never 永不重启
5、pod状态
①pending: apiserver创建了pod并存入到了etcd中,但尚未完成调度或镜像还处于下载中
②running: pod已被调度到节点中
③succeed: pod中所有容器都已成功终止并不会被重启
④failed: 所有容器都已停止,但至少有一个容器终止失败
⑤unknown: apiserver无法正常获取到pod对象的状态信息。
6、pod探针种类
startupProbe 用于判断容器内的应用程序是否已经启动。如果配置了该探针,就会先禁止其他的探测,成功后该探针将不在进行探测;
LivenessProbe 用于探测容器是否运行,如果探测失败,kubelet会根据配置的重启策略进行相应的处理。若没有配置该探针,默认就是success;
ReadinessProbe 用于探测容器内的程序是否健康,返回值如果为success,那么代表这个容器已完成启动,并且程序已经是可接受流量的状态
7、Pod探针的检测方式
ExecAction 在容器内执行一个命令,返回值为0,容器健康,反之不健康
exec:
command:
- /export/servers/skywing/k8s-hook
- status
TcpSocketAction 通过TCP连接检查容器内的端口是否是通的,如果是通的,就认为容器健康
tcpSocket:
port: 8910
HTTPGetAction 通过应用程序暴露的Api地址来检查程序是否是正常的,如果状态码为200-400之间,则为健康状态
httpGet:
path: /live/liveness
port: $containerPort
scheme: HTTP
8、探针存活/就绪检查参数配置示例
livenessProbe:
failureThreshold: 3 #当探测失败时,K8s将在放弃之前重试的次数。存活探测情况下的放弃就意味着重新启动容器。
httpGet:
path: /live/liveness
port: $containerPort
scheme: HTTP
initialDelaySeconds: 180 #指定 kubelet 在执行第一次探测前应该等待180秒,即第一次探测是在容器启动后的第181秒才开始执行。默认是 0 秒,最小值是 0。
periodSeconds: 10 #指定了 kubelet 应该每 10秒执行一次存活探测。默认是 10 秒。最小值是 1。
successThreshold: 1 #表示探针的成功的阈值,在达到该次数时,表示成功。默认值为 1,表示只要成功一次,就算成功了
timeoutSeconds: 5 #探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。(在 Kubernetes 1.20 版本之前,exec 探针会忽略 timeoutSeconds 探针会无限期地 持续运行,甚至可能超过所配置的限期,直到返回结果为止。)
readinessProbe:
failureThreshold: 3 #当探测失败时,K8s将在放弃之前重试的次数。就绪探测情况下的放弃 Pod 会被打上未就绪的标签。默认值是 3。最小值是 1。
httpGet:
path: /live/liveness
port: $containerPort
scheme: HTTP
initialDelaySeconds: 120
periodSeconds: 30
successThreshold: 1
timeoutSeconds: 5
9、pod的常见调度方式
自由调度: pod运行在哪个节点完全由scheduler经过一系列算法计算得出
定向调度: 采用nodeName、nodeSelector来实现pod定向调度
亲和性-反亲和性调度: NodeAffinityinity、PodAffinity、PodAntiAffinity
affinity:
nodeAffinity: #节点亲和性
requiredDuringSchedulingIgnoredDuringExecution: #硬亲和性规则
nodeSelectorTerms:
- matchFields:
- key: metadata.name
operator: In
values:
- k8s-node-vmef6y-yrq46fel86
-
污点、容忍调度: Taints、Toleration
https://blog.youkuaiyun.com/MssGuo/article/details/123961237
10、节点资源配置及pod驱逐
节点资源的配置分为两种:
1、资源预留 为系统进程和k8s进程预留资源
2、pod驱逐 节点资源达到一定使用量,开始驱逐pod
驱逐条件:
1、Node Capacity: 超过Node的所有硬件资源
2、kube-reserved: 超过给kube组件预留资源;
3、system-reserved: 超过给system进程预留的资源
4、eviction-threshold: 超过kubelet eviction的阈值设置
5、Allocatable: 真正调度pod时的参考值
11、Taints和Tolerations(污点和容忍)
Taints: 使Node拒绝特定的Pod运行
污点的类别:
NoSchedule: 禁止调度到该节点
PreferNoSchedule: 尽量不要调度pod至该节点
NoExecute: 如果没有设置容忍该污点,新的Pod肯定不会调度进来, 并且已经在运行的Pod没有容忍该污点也会被驱逐
设置污点:
kubectl taint node node名称 key=value:NoSchedule (key、value可以自定义)
删除污点:
kubectl taint node node名称 key=value:NoSchedule- (-代表删除污点)
kubectl taint node node名称 key-
kubectl taint node node名称 key:NoSchedule-
Toleration: 为pod的属性,表示Pod能容忍标注了Taint的Node
查看容忍的配置项:
kubectl explain pod.spec.tolerations
tolerations: 数组类型 可以设置多个容忍
- key: 污点key
operator: 操作符 有两种选项Exists、Equal 默认是Equal
value: 污点value 如果使用Equal需要设置,如果是Exists不需要设置
effect: 可以设置为NoSchedule、PreferNoSchedule、NoExecute 如果为空表示匹配该key下所有污点
tolerationSeconds: 如果污点类型为NoExecute,还可以设置一个时间,表示这一个时间段内Pod不会被驱逐,过了这个时间段会立刻驱逐,0或者负数会被立刻驱逐
示例:
tolerations:
- key: web
operator: Equal
value: "true"
effect: NoSchedule
tolerationSeconds: 200
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
12、容器生命周期钩子函数
钩子函数: 监听容器生命周期的特定事件,并在事件发生时执行已注册的回调函数
支持以下两种钩子函数:
1、postStart: 容器创建后立即执行,注意的是由于是异步执行,无法保证一定在ENTRYPOINT之前执行.如果失败,容器会被杀死,并根据容器重启策略是否进行重启
2、preStop: 容器终止前执行,常用于资源清理,执行完成之后容器将成功终止。如果失败,容器同样也会被杀死。在其完成之前,会阻塞删除容器的操作
钩子的回调函数执行以下三种方式定义动作:
1、exec: 在容器内执行命令,如果命令的退出状态码是0,表示执行成功,否则表示失败
2、httpGet: 向指定URL发起GET请求,如果返回的状态码在大于等于200小于400之间,则表示成功,反之失败
3、tcpSocket: 在容器内尝试访问指定的socket
钩子函数使用演示
场景: 在容器创建完成后,需要执行一个shell脚本,脚本内容是将该容器注册到consul中,但是该脚本无法通过Dockerfile封装进去,因此采用钩子函数结合volume挂载configmap的方法来实现。这个lifecycle和容器image对齐即可。
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -c
- "sh /export/server/start.sh"
lifecycle:
preStop:
exec:
command:
- sh
- bin/launch.sh
- stop
volumeMounts:
- mountPath: /export/server/ #脚本在容器内的挂载位置
name: promsh #与volume挂载名称要一致
readOnly: false #是否仅仅可读
volumes:
- name: promsh
configMap:
name: promsh
#将脚本start.sh以configmap形式创建 给start.sh对应的执行权限
chmod 777 /xx/xx/start.sh
cd /xx/xx/
kubectl create configmap promsh --from-file=start.sh -n 命名空间
configmap部分
一般用configmap管理一些配置文件或者一些环境变量信息,且configmap保存的数据大小不能超过1MB
configmap: 配置文件和pod是分开的,优点: 更利于配置文件的更改和管理
secret: 倾向于存储和共享敏感、加密的配置信息
configmap创建及使用方式
1、从目录中创建,将配置文件写到指定的目录中,采用key-value形式
使用命令 kubectl create cm xx名(configmap名) --from-file=目录名/配置文件名
使用命令 kubectl get cm xx名 -oyaml 查看资源文件
2、使用命令行,采用字段的方式添加
kubectl create configmap student-config --from-literal=tom="male" --from-literal=alice="female"
3、采用挂载方式,将configmap挂载到容器某个路径内,需要重启pod
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/foo"(容易覆盖掉容器内这个路径下的其他文件)
readOnly: true
volumes:
- name: foo
configMap:
name: myconfigmap
4、创建一个yaml文件,在该文件中可以采用添加配置文件路径的形式或者添加字段的形式,进行资源创建 kubectl apply -k .
例如:
configmap-test.yaml
cat << EOF >./configmap-test.yaml
configMapGenerator:
- name: game-config-5
files:
- game-special-key=存放配置文件的目录/配置文件名
EOF
kubectl apply -k .
configmap-literals.yaml
cat << EOF >./configmap-literals.yaml
configMapGenerator:
- name: special-config-5
literals:
- special.how=how
- special.type=charm
EOF
kubectl apply -k .
5、使用环境变量方式(valueFrom)注入容器中,使用configmap 不需要重启pod
apiVersion: v1
kind: Pod
metadata:
name: pod-cm
spec:
containers:
- name: cm-pod
image: nginx
#定义环境变量 count
env:
- name: count
valueFrom: ##valueFrom是一种更加灵活的方式,它允许将 ConfigMap、Secret或Downward API中的单个键值对注入为环境变量或命令行参数
configMapKeyRef:
# cm中的键
key: count
# cm名称
name: cm-dome1
6、使用环境变量envFrom注入容器中,使用configmap 不需要重启pod
apiVersion: v1
kind: Pod
metadata:
name: pod-cm
spec:
containers:
- name: cm-pod
image: nginx
# 指定env来源
envFrom: #envFrom是一种批量注入的方式,它允许您将ConfigMap或Secret中所有键值对都注入为环境变量
- configMapRef:
# 多列表空格增加
name: cm-dome2
补充:哪些形式的配置是热更新
1、使用 env\envFrom 挂载的 configmap 不会热更新
因为ENV 是在容器启动的时候注入的,启动之后 kubernetes 就不会再改变环境变量的值,且同一个 namespace 中的 pod 的环境变量是不断累加的
2、使用volume 挂载的 configmap 中的数据需要一段时间(实测大概10秒--1分钟左右)才能热更新
3、如果使用ConfigMap的subPath挂载为Container的Volume,Kubernetes不会做自动热更新
示例: https://www.kubernetes.org.cn/3138.html
secret部分
secret 可选参数有三种:
generic: 通用类型,通常用于存储密码数据。
tls: 此类型仅用于存储私钥和证书。
kubectl create secret tls tls-secret --cert=path/to/tls.cert --key=path/to/tls.key
docker-registry: 若要保存 docker 仓库的认证信息的话,就必须使用此种类型来创建。
Secret 类型:
Service Account: 用于被 serviceaccount 引用。serviceaccout 创建时 Kubernetes 会默认创建对应的secret。Pod 如果使用了 serviceaccount,对应的 secret 会自动挂载到 Pod的/run/secrets/kubernetes.io/serviceaccount 目录中。
Opaque: base64 编码格式的 Secret,用来存储密码、秘钥等。可以通过 base64 --decode解码获得原始数据,因此安全性弱
kubernetes.io/dockerconfigjson: 用来存储私有 docker registry 的认证信息。
secret基于base64加密和解密
base64加密:
echo -n 'admin' | base64
base64解密:
echo YWRtaW4= | base64 -d
secret创建
secret一般用来保存敏感信息,例如密码(redis、mysql)、令牌或者key等
1、采用文件创建
echo 'admin' > username.txt
echo '123' > passwd.txt
kubectl create secret generic db-user-pass --from-file=./username.txt --from-file=./passwd.txt 创建secret(采用文件创建)
kubectl get secret db-user-pass -oyaml 查看资源文件
2、采用字段形式创建
kubectl create secret generic db-user-pass --from-literal=username=devuser --from-literal=password='ds$@!dja' (如果有特殊字符,使用单引号引起来,否则报错)
secret使用
3、采用volume挂载方式使用secret资源
secret-test.yaml
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts: (指定容器内挂载路径和文件的权限)
- name: foo
mountPath: "/etc/foo"
readOnly: true
volume:
- name: foo
secret:
secretName: mysecret (必须先生成一个名为mysecret的secret资源,将该资源挂载到容器内使用)
4、使用环境变量方式(valueFrom)注入容器中,使用configmap 不需要重启pod
apiVersion: v1
kind: Pod
metadata:
name: pod-secret
spec:
containers:
- name: secret-pod
image: nginx
#定义环境变量 count
env:
- name: count
valueFrom: ##valueFrom是一种更加灵活的方式,它允许将 ConfigMap、Secret或Downward API中的单个键值对注入为环境变量或命令行参数
secrRef:
# secret中的键
key: count
# secret名称
name: secret-dome1
5、使用环境变量envFrom注入容器中,使用configmap 不需要重启pod
apiVersion: v1
kind: Pod
metadata:
name: pod-secret
spec:
containers:
- name: secret-pod
image: nginx
# 指定env来源
envFrom: #envFrom是一种批量注入的方式,它允许您将ConfigMap或Secret中所有键值对都注入为环境变量
- secretRef:
# 多列表空格增加
name: sercret-dome2
secret使用场景
secret用途:
imagePullSecret: pod 拉取私有镜像仓库时使用的仓库用户名和密码,里面的账户信息会传递给kubelet,然后kubelet就可以拉取有密码的仓库里面的镜像。
方法一:
kubectl create secret docker-registry <secret_name> --docker-server=DOCKER地址 --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL
方法二:
kubectl create secret generic registry-secret --from-file=.dockerconfigjson=/root/.docker/config.json > \
--type=kubernetes.io/dockerconfigjson -n fast
secret-test.yaml
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
imagePullSecrets:
- name: <secret_name>
containers:
- name: mypod
image: redis
volumeMounts: (指定容器内挂载路径和文件的权限)
- name: foo
mountPath: "/etc/foo"
readOnly: true
volume:
- name: foo
secret:
secretName: mysecret (必须先生成一个名为mysecret的secret资源,将该资源挂载到容器内使用)
configmap&&secret使用subPath(防止覆盖目录,但是更新完configmap后,容器不会更新)
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo
mountPath: "/etc/nginx/nginx.conf"
subPath: etc/nginx/nginx.conf(如果不使用subpath,挂载文件后的容器路径中就只会存在一个nginx.conf文件,其他文件会被覆盖掉,subPath前面不加/)
readOnly: true
volumes:
- name: foo
configMap:
items:
- key: nginx.conf(配置文件名)
path: etc/nginx/nginx.conf
name: nginx-conf (创建的configmap资源名)
serviceAccount部分
1、serviceAccount是给pod里的进程与API Server通信完成身份认证,属于某个具体的Namespace。相比于user account的全局性权限,service account更适合一些轻量级的task,更聚焦于授权给某些特定Pod中的Process所使用。
2、在 Kubernetes 中,每个 ServiceAccount 都会被创建一个 Secret 对象,其中包含了该ServiceAccount 的访问令牌和 CA 证书。默认情况下,Pod 会自动挂载与该 Pod 同名的 ServiceAccount 所对应的 Secret 对象为 /var/run/secrets/kubernetes.io/serviceaccount 目录,并将其中包含的访问令牌和 CA 证书作为环境变量传递给容器。通过这种方式,容器就可以获取到与该 ServiceAccount 相关联的访问令牌,从而Kubernetes API Server 发送请求并获取其他资源。
3、优点:
使用 ServiceAccount 的主要优点是提高了集群的安全性和可管理性。它减少了人为操作,避免了直接泄露机密信息,并简化了集群管理.由于访问令牌的有效期有限,所以会自动地定期更新,从而增强了集群的安全性。
serviceaccount+secret+dashboard示例
1、创建一个secret用来登录dashboard,只能查看cityos命名空间下的资源
# 创建serviceaccount账户:lucky-admin
kubectl create serviceaccount lucky-admin -n cityos
# 把lucky用户做rolebingding绑定
kubectl create rolebinding lucky-admin-rolebinding -n lucky --clusterrole=cluster-admin --serviceaccount=cityos:lucky-admin
# 查看secret
kubectl describe secret xxx-token-xx -n cityos
注释:
在cityos名称空间下创建一个rolebinding,名字叫做lucky-admin-rolebinding
将cityos名称空间下的lucky-admin账号通过clusterrole绑定集群角色cluster-admin,这样lucky-admin账号就有了cluster-admin角色的权限。
lucky-admin账号的权限只能限制在cityos名称空间下,因为我们创建的是rolebinding
2、创建一个secret用来登录dashboard,可以查看所有命名空间资源
# 创建serviceaccount账户:lucky2-admin
kubectl create serviceaccount lucky2-admin -n cityos
# 把lucky用户做clusterrolebingding绑定
kubectl create clusterrolebinding lucky2-admin-rolebinding --clusterrole=cluster-admin --serviceaccount=cityos:lucky2-admin
# 查看secret
kubectl describe secret lucky2-admin-token-h2shd -n cityos
使用yaml文件创建一个角色,该角色只具有查看cityos命名空间下pod、log、deployment的能力
#创建serviceaccount
kubectl create sa -n cityos tyler
#创建角色role
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: cityos
name: tyler
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get", "watch", "list"]
- apiGroups: ["extensions", "apps"]
resources: ["deployments"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["cityos"]
verbs: ["create", "get", "delete","list"]
#创建角色绑定rolebinding
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: tyler
namespace: cityos
subjects:
- kind: ServiceAccount
name: tyler
roleRef:
kind: Role
name: tyler
apiGroup: rbac.authorization.k8s.io
CoreDNS部分
1、为什么需要coredns?
当k8s中的pod基于service域名解析后,在负载均衡分发到service后端的各个pod服务中,如果没有DNS解析,则无法查到各个服务对应的service服务
2、服务发现方式
基于环境变量的方式
基于内部域名方式
3、DNS策略 dnsPolicy
a)None 用于想要自定义 DNS 配置的场景,而且需要和 dnsConfig 配合一起使用
b)Default 让 kubelet 来决定使用何种 DNS 策略。而 kubelet 默认使用宿主机的 /etc/resolv.conf(使用宿主机的DNS策略)但 kubelet 可以配置使用什么文件来进行 DNS 策略,使用 kubelet 的参数:–resolv-conf=/etc/resolv.conf 来决定 DNS 解析文件地址
c)ClusterFirst 表示 POD 内的 DNS 使用集群中配置的 DNS 服务,使用 Kubernetes 中 kubedns 或 coredns 服务进行域名解析。如果解析不成功,才会使用宿主机的 DNS 进行解析
d)ClusterFirstWithHostNet POD 是用 HOST 模式启动的(HOST模式),用 HOST 模式表示 POD 中的所有容器,都使用宿主机的 /etc/resolv.conf 进行 DNS 查询,但如果使用了 HOST 模式,还继续使用 Kubernetes 的 DNS 服务,那就将 dnsPolicy 设置为 ClusterFirstWithHostNet
可以通过在 Pod 的 spec 中设置 dnsPolicy 字段来指定 DNS 策略。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: nginx
image: nginx
dnsPolicy: ClusterFirst
此外,还可以在 Pod 的 spec 中设置 dnsConfig 字段来指定 DNS 解析器的 IP 地址和搜索域名
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: nginx
image: nginx
dnsPolicy: ClusterFirst
dnsConfig:
nameservers:
- 10.0.0.2
- 10.0.0.3
searches:
- my.domain.com
- other.domain.com
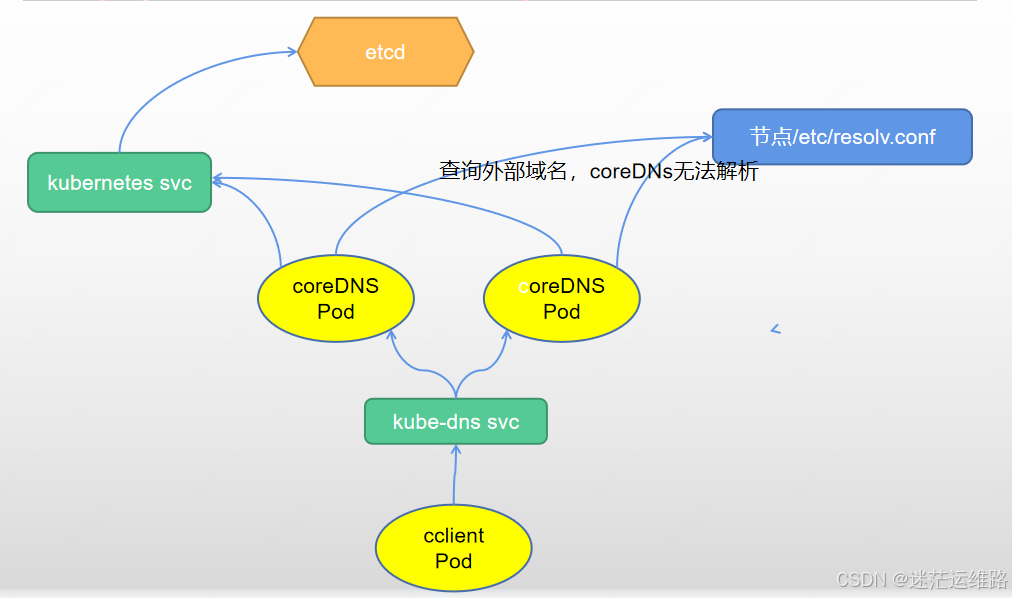
CoreDNS解析流程
1、pod根据/etc/resolv.conf将解析请求转发给coredns service
2、core service会将请求转发到后端的coreDNS pod
3、coredns pod会根据corefile的配置连接到k8s service监视service ip的变动,维护DNS解析记录
4、coredns查询到service name对应的ip后返回给给客户端
5、如果查询的是外部域名,coredns无法解析,就转发给指定的域名服务器,一般是节点上/etc/resolv.conf中的服务器解析
CoreDNS配置文件解析
.:53 {
errors #将错误日志发送至标准输出
health { #通过http://loaclhost:8080/health报告健康状态
lameduck 5s
}
ready #所有插件就绪后通过8181端口响应200 Ok报告就绪状态
kubernetes cluster.local in-addr.arpa ip6.arpa { #Kubernetes系统的本地区域及专用的解析配置
pods insecure
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153 #通过http://localhost:9153/metrics暴露指标数据
forward . /etc/resolv.conf { #非Kubernetes集群内部域名的转发逻辑 将所有非 Kubernetes 集群内部的域名查询请求都转发给 /etc/resolv.conf 中定义的 DNS 服务器
max_concurrent 1000
policy sequential #表示按顺序依次查询上游 DNS 服务器。
}
cache 30 #启用解析缓存,缓存时长30s
loop #检测是否存在解析循环,如果有终止其过程
reload #Corefile内容改变时自动重载配置信息
loadbalance #轮询DNS域名解析,如果一个域名存在多个记录就轮询解析
log #启动日志
}
CoreDNS三种解析方式(nslookup service-name.namespace.svc.cluster.local)
1、CoreDNS配置文件中通过自定义hosts进行特定域名解析
通过命令“kubectl edit configmap coredns -n kube-system”查看到相应的配置文件
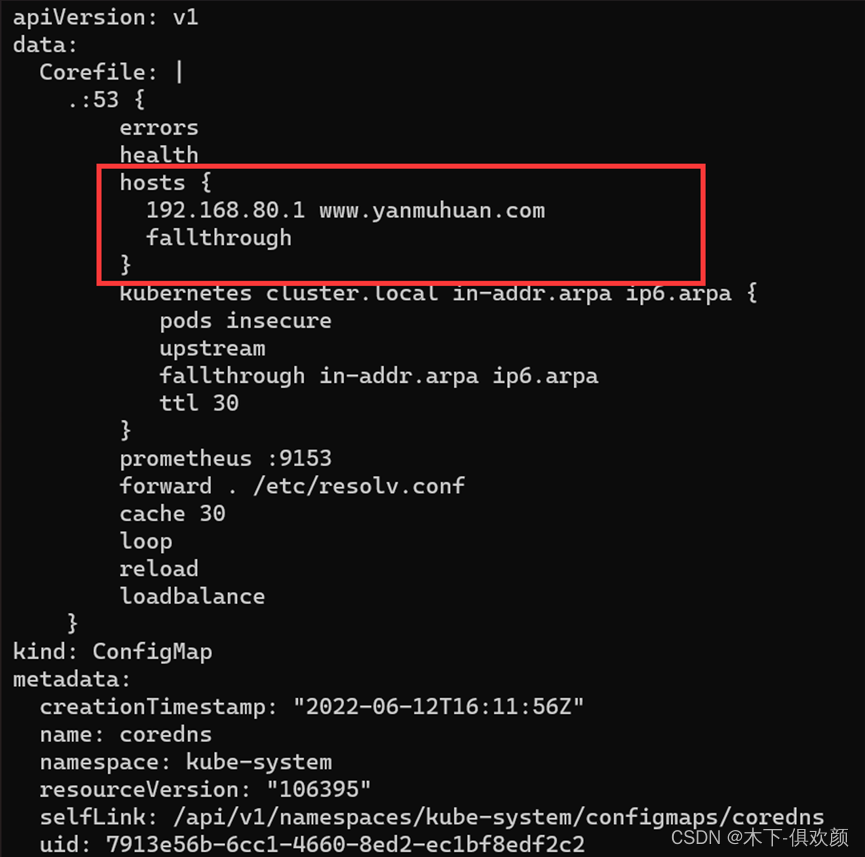
命令“kubectl exec -it nginx-web-bb69f5d84-zpqcp – /bin/bash”进入容器(容器名称根据实际情况进行输入),然后在容器内通过命令“apt install bind9*”安装nslookup命令,最后相关解析结果如下,由此可见,相关解析是成功的

2、CoreDNS配置文件中配置特定DNS服务器解析特定域名
此处的forward 指的是仅将特定域名 yum.com 的查询请求转发给指定的 DNS 服务器
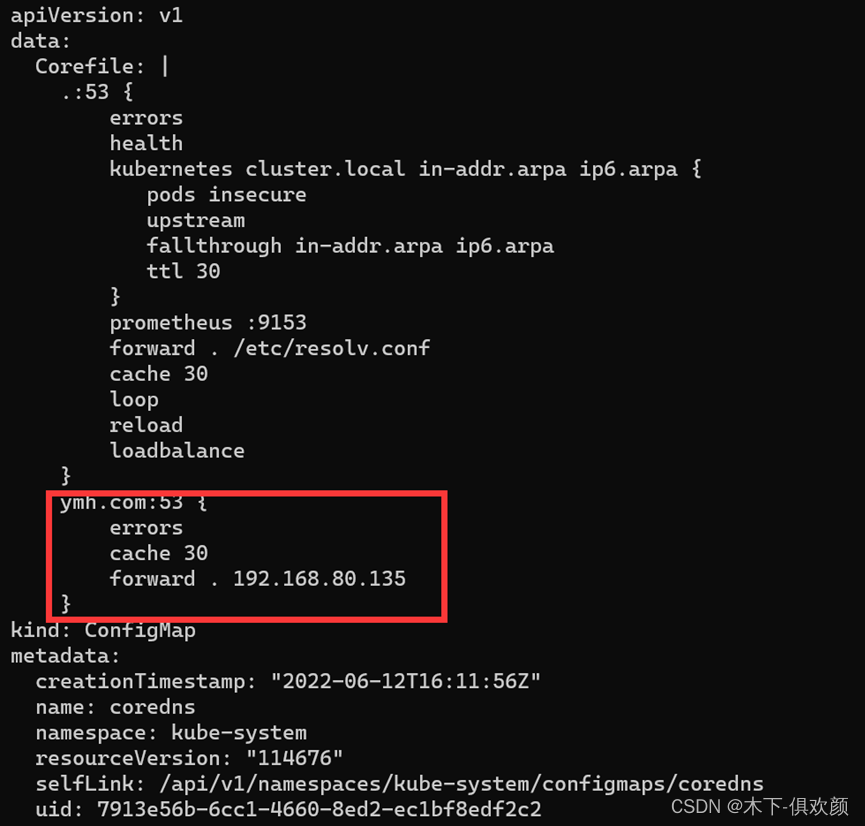
通过命令“kubectl exec -it nginx-web-bb69f5d84-zpqcp -- /bin/bash”进入容器(容器名称根据实际情况进行输入),然后在容器内通过命令“apt install bind9*”安装nslookup命令,最后相关解析结果如下,由此可见,相关解析是成功的
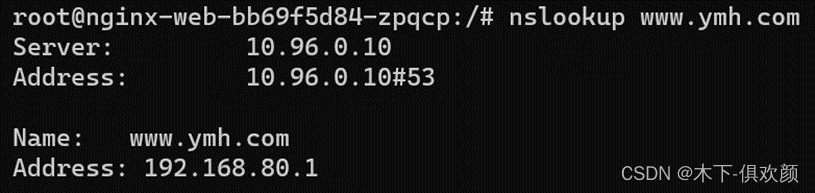
3、CoreDNS配置文件中配置特定DNS服务器解析所有域名

通过命令“kubectl exec -it nginx-web-bb69f5d84-zpqcp – /bin/bash”进入容器(容器名称根据实际情况进行输入),然后在容器内通过“apt install bind9*”和“apt install vim”分别安装nslookup和vim命令,最后输入“vim /etc/resolv.conf”删除“localdomain”搜索域

ndots:5:如果查询的域名包含的点 “.” 不到 5 个,那么先使用search域名,再用绝对域名,如果你查询的域名包含点数大于等于 5,那么先用绝对域名查找,再用search域查找。
最后进行域名解析验证,由此可见解析成功

域名在pod中的解析过程
1.1 pod 中容器内 resolve 文件
这个文件中,配置的 DNS Server,一般就是 K8S 中,kubedns 的 Service 的 ClusterIP,这个IP是虚拟IP,无法ping,但可以访问。
nameserver 10.96.0.10
search cityos.svc.cluster.local svc.cluster.local cluster.local jdicity.local
options ndots:2 single-request-reopen
1.2 kube-dns 服务
所以,所有域名的解析,其实都要经过 kubedns的虚拟IP 10.96.0.10 进行解析,不论是 Kubernetes 内部域名还是外部的域名。
[root@k8smaster01 ~]# kubectl get svc -n kube-system |grep dns
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 2y173d
1.3 访问其他服务的解析流程
1、Kubernetes 中,域名的全称,必须是 service-name.namespace.svc.cluster.local 这种模式,服务名,就是Kubernetes中 Service 的名称,所以,当我们执行下面的命令时:
curl b 时必须得有一个 Service 名称为 b,这是前提。
2、在容器内,会根据 /etc/resolve.conf 进行解析流程。选择 nameserver 10.96.0.10 进行解析,然后,用字符串 “b”,依次带入 /etc/resolve.conf 中的 search 域,进行DNS查找,分别是:
b.cityos.svc.cluster.local
-> b.svc.cluster.local
-> b.cluster.local ,直到找到为止
3、如果是同命名空间,则直接 curl svc名即可,
4、如果是跨命名空间,则写全称。 curl service-name.namespace.svc.cluster.local
在 Kubernetes 集群中使用自定义域名解析
如果您想在 Kubernetes 集群中使用自定义域名解析,请确保在 Kubernetes 中配置了合适的 DNS 服务器。在 Kubernetes 中,默认情况下会使用 CoreDNS 作为 DNS 服务器,因此您需要在 CoreDNS 中进行相应的配置。
以下是一些指导步骤,将自定义域名映射到 Kubernetes Service 中的 ClusterIP 地址:
1. 使用 `kubectl edit` 命令编辑 CoreDNS 的 ConfigMap。你可以用 `kubectl edit configmap coredns -n kube-system` 命令来编辑CoreDNS ConfigMap,将 `kube-system` 替换成 CoreDNS 所在的命名空间名称。
2. 在该 ConfigMap 中,找到 `Corefile` 部分,并添加一个新的 `block` 来定义您的自定义域名解析规则。例如,如果您的域名是 `example.com`,并且您想将它解析到`my-app-service` 的 ClusterIP 上,则可以添加如下的配置:
jdicity.local:53 {
errors
cache 30
forward . 10.96.0.20
}
这个示例中,我们使用 forward 插件将所有 `jdicity.local` 请求转发到 `my-app-service.cluster.local` 这个内部域名上。`my-app-service.cluster.local` 对应于 My-App Service 的 ClusterIP 地址,其中 `cluster.local` 是 Kubernetes 集群默认使用的 DNS 空间名称(也可替换为您的自定义值)。
3. 保存和退出 ConfigMap 编辑器,CoreDNS 将自动重新加载新的配置规则。等待一段时间(视修改的DNS记录传播时间而定),您就可以使用 `example.com` 这个域名轻松地访问您的 My-App 服务了。
请注意,在某些情况下,您还需要在 DNS 提供商的控制面板中添加一些额外的 DNS 记录,以便将您的域名指向 Kubernetes 集群所在的网络位置。具体来说,您可能需要为 `example.com` 添加一个 NS 记录,将其指向 Kubernetes 集群的公共 IP 地址或负载均衡器的 IP 地址。
rewrite重写域名
将外部域名重写到集群内
https://blog.51cto.com/linuxmaizi/2419892
https://monkeywie.cn/2020/06/28/k8s-coredns-cname/
rewrite name nacos1.jdcity.local nacos-headless.szsh-test.svc.cluster.local
rewrite name nacos2.jdcity.local nacos-headless.szsh-test.svc.cluster.local
rewrite name nacos3.jdcity.local nacos-headless.szsh-test.svc.cluster.local
k8s域名解析故障排查处理
在使用K8S的过程中,可能会遇到域名解析失败的现象,主要有以下几种问题:
在Pod中无法解析集群外部的域名
Pod与Pod之间服务调用,无法使用服务发现地址进行通信。
问题一: pod中无法解析集群外部地址
当遇到Pod无法解析集群外部其他服务的域名时,大致的排查思路如下:
1)首先排查Coredns组件是否正常运行,查看Coredns的运行日志,可以从日志中读取关键信息。
2)Coredns是以Pod的形式部署在K8S集群的,会挂载调度到的Node节点上/etc/resolv.conf这个文件,可以去排查一下这个文件中配置的DNS地址,可以将nameserver地址换成114.114.114.114,到这一步问题可能会解决。
3)如果还是无法解析域名,那么就将Coredns组件删除重建。
4) 还有一种可能就是集群没有对应的出口地址,与集群外部地址网段没打通
问题二:Pod与Pod之间服务调用,无法使用服务发现地址进行通信
现象:
1、同命名空间下,在A服务的pod内解析不了B服务对应的域名地址
2、不通命名空间下,在A服务的pod内也解析不了B服务对应的域名地址
3、pod ping不通对应的svc地址<这个原因是kube-proxy使用了iptables模式>
处理方法:
0、检查coredns的pod状态是否正常,同时打开coredns的log,为后面查看日志做准备
1、查看pod 对应的yaml文件中配置的DNSPolicy
2、如果是ClusterFirst此策略,查看pod内部resolv.conf文件中配置的nameserver和search域
3、pod内部的nameserver地址是coredns的svc地址,查看是否一致,如果一致,则执行解析命令查看是否能成功解析域名,如果不行,则接着执行下一步
4、将pod的resolve.conf中的nameserver地址替换为coredns对应的pod地址,这样让 Pod 直接连接 CoreDNS Pod 的 IP,而不通过 Service 进行转发,再进行 nslookup 命令测试,进而判断 Service kube-dns 是否能够正常转发请求到 CoreDNS Pod 的问题.如果能解析成功,则说明问题出在了coredns svc上,则此时就应该查看kube-proxy是否正常
RBAC部分(权限控制机制)
开启RBAC
执行 grep -C3 'authorization-mode' /etc/kubernetes/manifests/kube-apiserver.yaml
查看是否添加了RBAC
k8s授权模式
ABAC 基于属性的访问控制
RBAC 基于访问的访问控制 (在kube-apiserver.yaml中通过指定authorization-mode来指定授权模式)
Webhook 通过调用外部REST服务对用户进行授权
Node 是一种专用模式,用于对kubelet发出的请求进行访问控制。
AlwaysDeny 一直拒绝
AlwaysAllow 一直访问
k8s–RBAC授权步骤
1、定义角色 在定义角色时会指定此角色对于资源访问控制的规制
2、绑定角色 在主体与角色进行绑定,对用户进行访问授权
用户分类
普通用户
普通用户是假定被外部或独立服务管理的。管理员分配私钥。平时常用的kubectl命令都是普通用户执行的。
如果是用户需求权限,则将Role与User(或Group)绑定(这需要创建User/Group),是给用户使用的。
ServiceAccount服务账户
ServiceAccount(服务帐户)是由Kubernetes API管理的用户。它们绑定到特定的命名空间,并由API服务器自动创建或通过API调用手动创建。服务帐户与存储为Secrets的一组证书相关联,这些凭据被挂载到pod中,以便集群进程与Kubernetes API通信。(登录dashboard时我们使用的就是ServiceAccount)
如果是程序需求权限,将Role与ServiceAccount指定(这需要创建ServiceAccount并且在deployment中指定ServiceAccount),是给程序使用的。
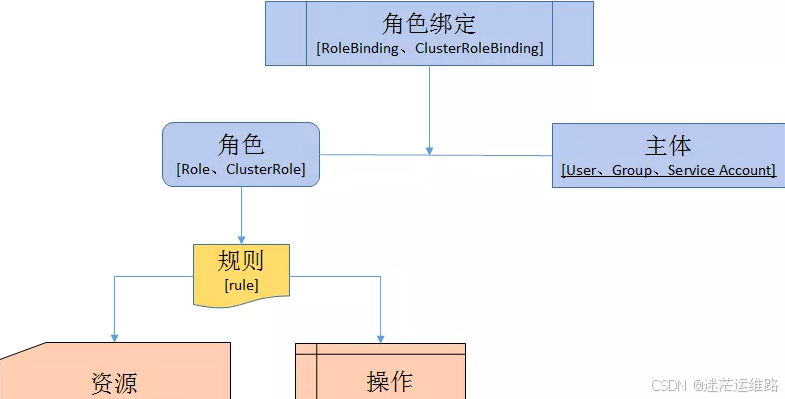
角色与角色绑定
角色与角色绑定
角色
role 一组代表相关权限的规则。 这些权限是纯粹累加的(不存在拒绝某操作的规则)针对特定的命名空间
ClusterRole 包含一组代表相关权限的规则。 这些权限是纯粹累加的(不存在拒绝某操作的规则)。
角色绑定
RoleBinding 将角色绑定到主体(即subject)
ClusterRoleBinding 将集群角色绑定到主体
主体
User 用户
Group 组
ServiceAccount 服务账户
参数详解
1、Role、ClsuterRole的Verbs可配置参数
"get", "list", "watch", "create", "update", "patch", "delete", "exec"
2、Role、ClsuterRole Resource可配置参数
"services", "endpoints", "pods","secrets","configmaps","crontabs","deployments","jobs","nodes","rolebindings","clusterroles","daemonsets","replicasets","statefulsets","horizontalpodautoscalers","replicationcontrollers","cronjobs"
3、Role、ClsuterRole APIGroup可配置参数
"","apps", "autoscaling", "batch"
Role示例
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-role
rules:
- apiGroups: [""] # "" 标明 core API 组
resources: ["pods"]
verbs: ["get", "watch", "list"]
ClusterRole示例
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
# "namespace" 被忽略,因为 ClusterRoles 不受名字空间限制
name: secret-reader
rules:
- apiGroups: [""]
# 在 HTTP 层面,用来访问 Secret 资源的名称为 "secrets"
resources: ["secrets"]
verbs: ["get", "watch", "list"]
RoleBinding示例 role角色绑定到ServiceAccount
$ cat >RoleBinding-001.yaml<<EOF
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rb
namespace: default
subjects:
- kind: ServiceAccount
name: zhangsan
namespace: default
roleRef:
kind: Role
name: pod-role
apiGroup: rbac.authorization.k8s.io
EOF
$ kubectl apply -f RoleBinding-001.yaml
$ kubectl get RoleBinding
$ kubectl describe RoleBinding rb
ClusterRoleBinding示例 clusterRole绑定到serviceAccount
$ cat >ClusterRoleBinding-001.yaml<<EOF
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: crb
subjects:
- kind: ServiceAccount
name: mark
namespace: default
roleRef:
kind: ClusterRole
name: secret-reader
apiGroup: rbac.authorization.k8s.io
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: mark
namespace: default
EOF
$ kubectl apply -f ClusterRoleBinding-001.yaml
$ kubectl get ClusterRoleBinding crb
$ kubectl describe ClusterRoleBinding crb
主体User示例
限制不同的用户操作 k8s 集群
1、创建k8s用户
普通用户并不是通过k8s来创建和维护,是通过创建证书和切换上下文环境的方式来创建和切换用户。
2、创建证书
# 创建私钥
$ openssl genrsa -out devuser.key 2048
# 用此私钥创建一个csr(证书签名请求)文件
$ openssl req -new -key devuser.key -subj "/CN=devuser" -out devuser.csr
# 拿着私钥和请求文件生成证书
$ openssl x509 -req -in devuser.csr -CA /etc/kubernetes/pki/ca.crt -CAkey /etc/kubernetes/pki/ca.key -CAcreateserial -out devuser.crt -days 365
3、生成账号
$ kubectl config set-credentials devuser --client-certificate=./devuser.crt --client-key=./devuser.key --embed-certs=true
4、设置上下文参数
# # 设置上下文, 默认会保存在 $HOME/.kube/config
$ kubectl config set-context devuser@kubernetes --cluster=kubernetes --user=devuser --namespace=dev
# 查看
$ kubectl config get-contexts
5、设置默认上下文
$ kubectl config use-context devuser@kubernetes
# 查看
$ kubectl config get-contexts
$ kubectl get nodes (会发现此时没有权限,需要切回原来的用户对此用户授权)
6、切回原来用户对新用户授权
$ kubectl config use-context kubernetes-admin@kubernetes
$ kubectl get nodes
授权
$ cat >devuser-role-bind<<EOF
kind: Role # 角色
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: dev
name: devuser-role
rules:
- apiGroups: [""] # ""代表核心api组
resources: ["pods"]
verbs: ["get", "list", "watch", "create", "update", "patch", "delete"]
---
kind: RoleBinding # 角色绑定
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: devuser-rolebinding
namespace: dev
subjects:
- kind: User
name: devuser # 目标用户
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: devuser-role # 角色信息
apiGroup: rbac.authorization.k8s.io
EOF
7、执行并验证
$ kubectl apply -f devuser-role-bind
$ kubectl config use-context devuser@kubernetes
$ kubectl get pods # 不带命名空间,这里默认dev,也只能查看dev上面限制的命名空间的pods资源,从而也验证了role是针对命名空间的权限限制
#查看其它命名空间的资源
$ kubectl get pods -n default
$ kubectl get pods -n kube-system
$ kubectl get nodes
8、结果
可以看到,用devuser,已经可以管理dev命名空间下的pod资源了,也只能管理dev命名空间下的pod资源,无法管理dev以外的资源类型,验证ok。
通过kubectl命令行工具进行角色绑定
kubecet create rolebinding
###在test命名空间中,将admin角色授权给bob
[root@k8s-master role]# kubectl create rolebinding bob-admin-binding --clusterrole=admin --user=bob --namespace=test
rolebinding.rbac.authorization.k8s.io/bob-admin-binding created
###在test命名空间中,将admin集群角色授予acme:myapp服务账号
[root@k8s-master role]# kubectl create rolebinding myapp-view-binding --clusterrole=view --serviceaccount=acme:myapp --namespace=test
rolebinding.rbac.authorization.k8s.io/myapp-view-binding created
kubectl create clusterrolebinding
1.在整个集群中,授予”cluster-admin“集群角色给”root“用户:
[root@k8s-master role]# kubectl create clusterrolebinding root-cluster-admin-binding --clusterrole=cluster-admin --user=root
clusterrolebinding.rbac.authorization.k8s.io/root-cluster-admin-binding created
2、在整个集群中,授予”system:node”集群角色给“kubelet”用户:
[root@k8s-master role]# kubectl create clusterrolebinding kubelet-node-binding --clusterrole=system:node --user=kubelet
clusterrolebinding.rbac.authorization.k8s.io/kubelet-node-binding created
3、在整个集群中,授予”view”集群角色给”acme:myapp”服务帐户
[root@k8s-master role]# kubectl create clusterrolebinding myapp-view-binding --clusterrole=view --serviceaccount=acme:myapp
clusterrolebinding.rbac.authorization.k8s.io/myapp-view-binding created
控制器部分
deployment(无状态服务)
用于部署无状态的服务,一般用于管理维护企业内部无状态的微服务,比如:springboot,可以管理多个pod实现无缝迁移、自动扩缩容、自动灾难恢复、一键回滚等功能。
deplyment控制器是从资源中创建pod,可以设定pod副本,当删除一个pod时,会立即重新拉起一个新的pod。
无状态服务不会在本地存储持久化数据,多个服务实例对于同一个用户请求的响应结果是完全一致的,且多实例之间没有依赖关系。
deployment基本操作命令
kubectl set image deploy nginx nginx=新的镜像版本 --record 更新pod镜像版本,并记录
kubectl rollout status deploy (nginx)xxx 查看镜像更新过程和状态
kubectl rollout history deploy nginx 查看之前发布的全部版本
kubectl rollout undo deploy nginx 回滚到上一个版本
kubectl rollout history deploy nginx --revision=number(序号) 查看指定版本的信息
kubectl rollout undo deploy nginx --to-revision=number(序号) 回滚到指定版本
kubectl scale --replicas=2 deploy nginx 扩缩容操作(不会产生新的replicas)
kubectl rollout pause deploy nginx 暂停 多次进行版本或者资源cpu限制等修改
kubectl rollout remuse deploy nginx 恢复多次修改后的更新操作
更新策略
rollingUpdate(默认): 滚动更新,先删除一部分旧pod资源创建新的pod资源,特点是保持业务连续不中断。可以指定maxSurge和maxUnavailable
maxSurage: 指定超过期望值的最大pod数,默认为25%,可以设置为数字或者百分比
maxUnavailable: 指定在更新时最大不可用的pod数量,默认为25%,可以设置为数字或百分比
Recreate: 重建更新,先删除全部旧pod,在更新新的pod
deployment无感知滚动更新线上服务
即在更新deployment时,不影响现有服务,使用户侧达到无感知,不影响线上服务的运行,即根据RollingUpdate设计,K8S应该在保持旧pod工作的同时启动新pod,并且只有在新pod准备好接受流量时,才应该删除旧pod。
操作方法: 修改deployment对应的yaml文件,在一个spec下添加以下配置,需结合探针一起使用
strategy:
rollingUpdate:
maxSurge: 1 #滚动升级时先启动的pod数量
maxUnavailable: 0 #滚动升级时允许的最大unavailable的pod数量,可以确保至少有一个 Pod 在更新过程中可以继续提供服务
type: RollingUpdate
statefulset (有状态服务,创建时依赖一个service资源)
有状态服务:需要在本地存储持久化数据,如果停止或者删除集群中的某个pod,会将数据也删除。
statefulset主要用于管理有状态应用程序的工作负载API对象。比如部署ES集群、redis集群、mongodb集群等
statefulset创建的pod一般使用Headless service(无头服务,即clusterIP为None),且pod有固定的标识符,有顺序,例如web-0、web-1…
statefulset更新策略(从后往前更新,例如web4----web0)
statefulset支持扩缩容,只有当前一个pod成功启动后,后续的pod才会继续更新,否则一直等待,删除时从后往前删除
rollingUpdate 滚动更新
OnDelete 默认升级策略,在创建好新的StatefulSetSet配置之后,新的Pod不会被自动创建,用户需要手动删除旧版本的Pod,才出发新建操作。
partition:分区滚动更新。当pod的序号大于设定的序号时,会更新大于设定序号的这几个pod,也就是灰度发布
sts删除
级联删除和非级联删除
级联删除: 删除sts同时删掉pod
非级联删除: 删除sts时不删除pod
非级联删除方式: kubectl delete sts web --cascade=false
当采用非级联删除sts后,pod就会成为孤儿pod,再次删除pod后,不会再自动创建。
Daemonset(守护进程集,缩写为ds)
当有新的node节点加入时,会立即在新node节点上启动一个和其他node节点一样pod,并且只产生一个pod,当该节点被删除时,pod也会被删除。(应用场景:运行filebeat、node_exporter、ceph集群存储、节点网络插件flannel等),支持回滚更新操作
job
apiVersion: batch/v1
kind: Job
metadata:
name: example-job
spec:
template:
metadata:
name: example-job-pod
spec:
containers:
- name: example-job-container
image: busybox
command: ["echo", "Hello from Kubernetes!"]
restartPolicy: OnFailure
backoffLimit: 4 #如果Pod在执行期间因某种原因失败,则最多可以重试该任务4次。
cronjob
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: my-cronjob
spec:
schedule: "*/5 * * * *" # 定时任务执行频率,每5分钟执行一次
jobTemplate:
spec:
template:
spec:
containers:
- name: my-container
image: my-image:latest # 执行该定时任务时要运行的镜像
command: ["my-command"]
args: ["arg1", "arg2"] # 执行对应容器的指令和参数
此 CronJob 将会至少创建一次 Job,每次创建新 Job 时都会创建一个 pod,Pod 的主容器是 my-container 并运行 my-command arg1 arg2 命令。该 CronJob 每 5 分钟运行一次。你可以根据自己的需求进行修改和调整。
类似于linux中的定时任务crontab,用来周期性的执行循环任务。
HPA
horizontal pod autoscaler:pod的水平自动伸缩器
通过观察pod的cpu、内存使用率自动扩展或缩容pod的数量,不适用于无法进行扩缩容的对象,例如:daemonset。需要提前部署metrics-server,通过kubectl top pod -n ns 来查看pod 的内存和cpu,依靠yaml文件中的requests参数。
hpa常用操作命令
kubectl autoscale deploy nginx --cpu-percent=20 --min=2 --max=5 当cpu使用率超过20%,自动扩展pod数量为5个,当cpu使用率在指定范围内时,pod数量为2个。
Lable&&selector(标签于选择器部分)
常用打标签操作命令
kubecl get pod --show-labels 查看所有pod的标签
kubectl label pod pod名 app=标签名 给pod打标签
kubectl label pod pod名 app- 删除pod标签
kubectl label pod pod名 app=标签名 --overwrite 修改pod标签
kubectl get pod -l version!=v1,app=nginx 查看pod标签中version不为v1,且app=nginx的标签的pod
selector必须和label的标签保持一样
资源配额
1、资源配额,通过resourceQuota对象来定义,对每个命名空间的资源消耗总量提供限制.它可以限制命名空间中某种类型的对象的总数目上限,也可以限制命名空间中的pod总数以及使用的计算资源的总上限。
资源配额工作方式:
1、集群管理员可以为每个命名空间创建一个或多个ResourceQuota对象
2、当用户在命名空间下创建资源时,k8s的配额系统会跟踪集群的资源使用情况,以确保使用的资源量不超过资源配额中定义的硬性资源限额
3、如果资源创建或者更新请求违反了配额约束,请求将会报错(HTTP 403 Forbidden)
4、如果命名空间下资源配额被启用,则用户在pod中必须为这些资源设定请求值和约束值,否则配额系统将拒绝pod的创建。
提示:
可使用LimitRange转入控制器来为没有设置资源限制的pod设置默认值
apiVersion: v1
kind: LimitRange
metadata:
name: laravel-limit-range
namespace: laravel
spec:
limits:
- default:
memory: 100Mi
cpu: 100m
defaultRequest:
memory: 100Mi
cpu: 100m
type: Container
资源预留配置
1、为什么需要资源预留配置?
Kubernetes 的节点可以按照节点的资源容量进行调度,默认情况下 Pod 能够使用节点全部可用容量。这样就会造成一个问题,因为节点自己通常运行了不少驱动 OS 和 Kubernetes 的系统守护进程。除非为这些系统守护进程留出资源,否则它们将与 Pod 争夺资源并导致节点资源短缺问题,出现OOM问题,node节点状态变为NotReady等状况。
2、Kubernetes 节点上的 Allocatable 被定义为 Pod 可用机器资源量,调度器不会超额申请 Allocatable,目前支持 CPU, memory 和 ephemeral-storage 这几个参数。
可以通过 kubectl describe node 命令查看节点可分配资源的数据
$ kubectl describe node ydzs-node4
......
Capacity: //总资源
cpu: 4
ephemeral-storage: 17921Mi
hugepages-2Mi: 0
memory: 8008820Ki
pods: 110
Allocatable: //可分配资源
cpu: 4
ephemeral-storage: 16912377419
hugepages-2Mi: 0
memory: 7906420Ki
pods: 110
......
注意:
当未在/var/lib/kubelet/config.yaml中配置系统预留资源与kube预留资源时,通过describle查出来的总资源约等于可分配资源
下图是可分配资源与资源预留之间的关系图
Node Capacity 是节点的所有硬件资源
kube-reserved 是给 kube 组件预留的资源(kube组件)
system-reserved 是给系统进程预留的资源
eviction-threshold 是 kubelet 驱逐的阈值设定(驱逐操作只支持内存和 ephemeral-storage 两种不可压缩资源 当节点上的可用内存降至保留值以下时,开始驱逐pod)
allocatable 才是真正调度器调度 Pod 时的参考值(保证节点上所有 Pods 的 request 资源不超过Allocatable)
节点可分配资源的计算方式为:
Node Allocatable Resource = Node Capacity - Kube-reserved - system-reserved - eviction-threshold
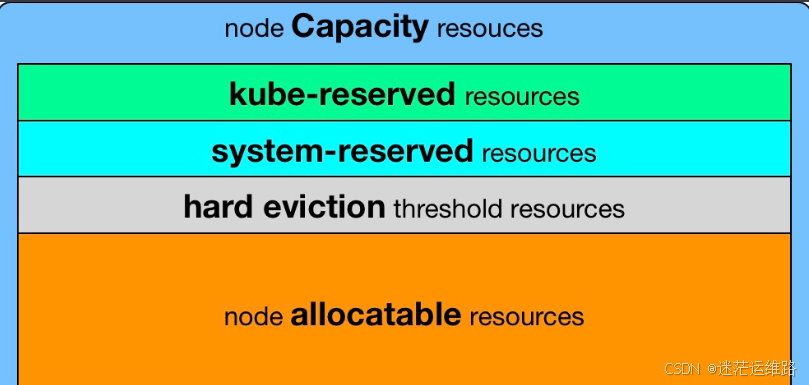
配置资源预留
https://ost.51cto.com/posts/12469
https://blog.youkuaiyun.com/zuoyang1990/article/details/129800736
kube预留配置
kube-reserved 是为了给诸如 kubelet、容器运行时、node problem detector 等 kubernetes 系统守护进程争取资源预留。要配置 Kube 预留,需要把 kubelet 的 --kube-reserved-cgroup 标志的值设置为 kube 守护进程的父控制组。
配置方法:
直接修改 /var/lib/kubelet/config.yaml 文件来动态配置 kubelet,添加如下所示的资源预留配置
apiVersion: kubelet.config.k8s.io/v1beta1
......
enforceNodeAllocatable:
- pods
- kube-reserved # 开启 kube 资源预留
kubeReserved:
cpu: 500m
memory: 1Gi
ephemeral-storage: 1Gi
kubeReservedCgroup: /kubelet.slice # 指定 kube 资源预留的 cgroup
####创建相关Cgroup目录和文件
$ mkdir -p /sys/fs/cgroup/cpu,cpuacct/kubelet.slice
$ mkdir -p /sys/fs/cgroup/memory/kubelet.slice
$ mkdir -p /sys/fs/cgroup/systemd/kubelet.slice
$ mkdir -p /sys/fs/cgroup/pids/kubelet.slice
$ mkdir -p /sys/fs/cgroup/cpu,cpuacct/kubelet.slice
$ mkdir -p /sys/fs/cgroup/cpuset/kubelet.slice
$ mkdir -p /sys/fs/cgroup/hugetlb/kubelet.slice
$ systemctl restart kubelet
配置完成后重启kubelet使其生效。在重启前必须确保创建了相关的Cgroup文件和目录,否则重启会失败
再次查看节点信息如下:
$ kubectl describe node ydzs-node4
......
Addresses:
InternalIP: 10.151.30.59
Hostname: ydzs-node4
Capacity:
cpu: 4
ephemeral-storage: 17921Mi
hugepages-2Mi: 0
memory: 8008820Ki
pods: 110
Allocatable:
cpu: 3500m
ephemeral-storage: 15838635595
hugepages-2Mi: 0
memory: 6857844Ki #此处的值就在不等于Capacity中的值,因为有kube预留了
pods: 110
......
系统预留值
system-reserved 用于为诸如 sshd、udev 等系统守护进程争取资源预留,system-reserved 也应该为 kernel 预留 内存,因为目前 kernel 使用的内存并不记在 Kubernetes 的 pod 上。但是在执行 system-reserved 预留操作时请加倍小心,因为它可能导致节点上的关键系统服务 CPU 资源短缺或因为内存不足而被终止,所以如果不是自己非常清楚如何配置,可以不用配置系统预留值
直接修改 /var/lib/kubelet/config.yaml 文件来动态配置 kubelet,添加如下所示的资源预留配置
systemReserved:
cpu: 600m
memory: 1Gi
ephemeral-storage: 10Gi
同样还需要创建cgroup相关的文件和目录
驱逐阈值(可不设置)
节点级别的内存压力将导致系统内存不足,这将影响到整个节点及其上运行的所有 Pod,节点可以暂时离线直到内存已经回收为止,我们可以通过配置 kubelet 驱逐阈值来防止系统内存不足。驱逐操作只支持内存和 ephemeral-storage 两种不可压缩资源。当出现内存不足时,调度器不会调度新的 Best-Effort QoS Pods 到此节点,当出现磁盘压力时,调度器不会调度任何新 Pods 到此节点。
直接修改 /var/lib/kubelet/config.yaml 文件来动态配置 kubelet,添加如下所示的资源预留配置
# /var/lib/kubelet/config.yaml
......
evictionHard: # 配置硬驱逐阈值
memory.available: "300Mi" //节点内存预留值
nodefs.available: "10%"
enforceNodeAllocatable:
- pods
- kube-reserved
kubeReserved:
cpu: 500m
memory: 1Gi # #####建议保留系统内存的 10% 到 20% 作为系统保留内存
ephemeral-storage: 1Gi
kubeReservedCgroup: /kubelet.slice
......
Qos服务质量
即yaml文件中配置的limits、request
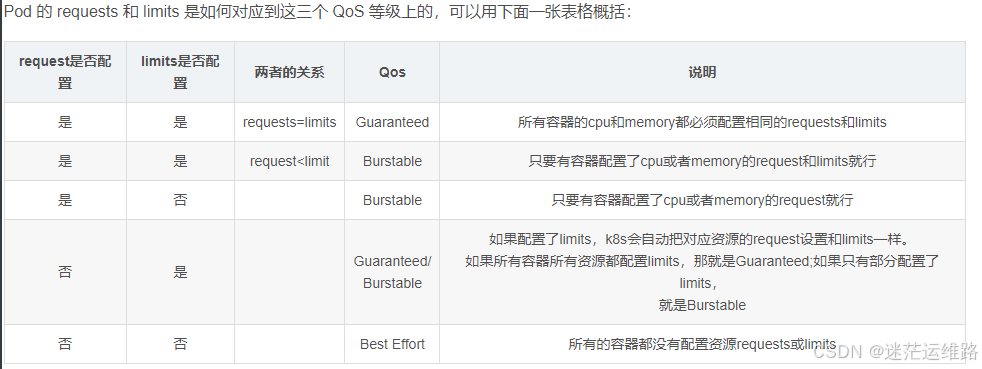
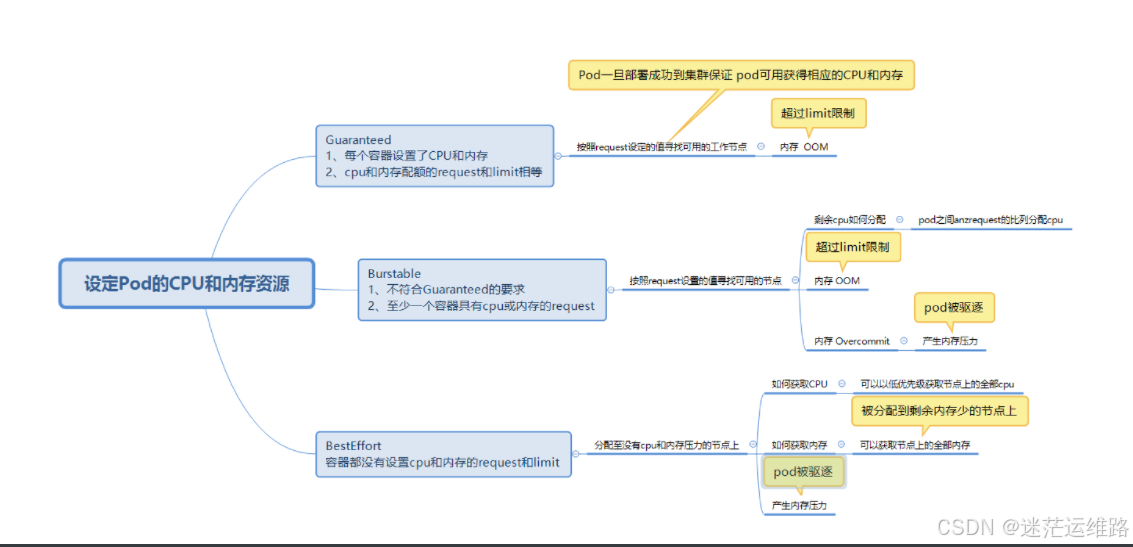
1、Qos三种情况
Guaranteed 可靠 当设置的资源(cpu\memory)限制相等时,为该状态
Burstable 基本可靠 设置了一个资源限制或设置的限制均不相等
BestEffort 不可靠 未设置资源限制未该状态
说明:
request和limits相同,可以参考资源动态调整中的VPA设置合理值。
如果只配置了limits,没有配置request,k8s会把request值和limits值一样。
如果只配置了request,没有配置limits,该pod共享node上可用的资源,实际上很反对这样设置。
volumes部分
作用:
1、容器中的磁盘文件是短暂的,当容器崩溃时,kubelet会重启容器,但是最初的文件会丢失
2、当pod运行多个容器时,各个容器之间可能需要共享一些文件,即当需要持久化数据或共享数据的容器需要volumes
volumes种类:
nfs、ceph、gfs...
类型一: emptyDir
和volume不同的是,如果删除pod,emptyDir卷中的数据也将被删除。
emptyDir卷用于pod中不同的容器container共享数据,可以被挂载到相同或者不同的路径上
示例:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: foo #引用volumes名字
mountPath: "/etc/redis/redis.conf" #挂载的路径
- name: mypod
image: nginx
volumeMounts:
- name: foo #引用volumes名字
mountPath: "/etc/nginx/nginx.conf" #挂载的路径
volumes:
- name: foo #定义名字
emptyDir: {} #创建emptyDIr类型
medium: Memory #指定内存
sizeLimit: xx #指定占用的大小
使用命令: kubectl exec -it xxxpod名 -c 镜像名 --bash(当一个pod中有多个容器时,使用-c命令指定容器)
类型二: HostPath
作用:
将主机节点上的文件或者目录挂载到pod中,用于pod自定义日志输出或访问Docker内部的容器等
示例
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: timezone #引用volumes名字
mountPath: /etc/timezone #挂载的路径
volumes:
- name: timezone #定义名字
hostPath: #创建hostPath类型
path: /etc/timezone
type: File #(类型: file\directory\socket套接字\chardevice字符设备\blockDevice块设备)
类型三: NFS
1、各节点安装nfs
2、各节点配置/etc/exports
共享目录路径 网段/ip (rw,sync,no_subtree_check,no_root_squash)
exportfs -r
systemctl reload nfs-server
3、创建共享目录 mkdir /data/log
4、挂载 mount -o nfs ip地址:/data/log nfs
示例:
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
name: nfs-volume #引用volumes名字
- mountPath: /etc/redis/redis.log #挂载的路径
volumes:
- name: nfs-volume #定义名字
nfs:
server: nfs服务端ip地址
path: /data/log
注意: nfs并不能满足生产环境中的高可用架构
PV&&PVC部分
模型图
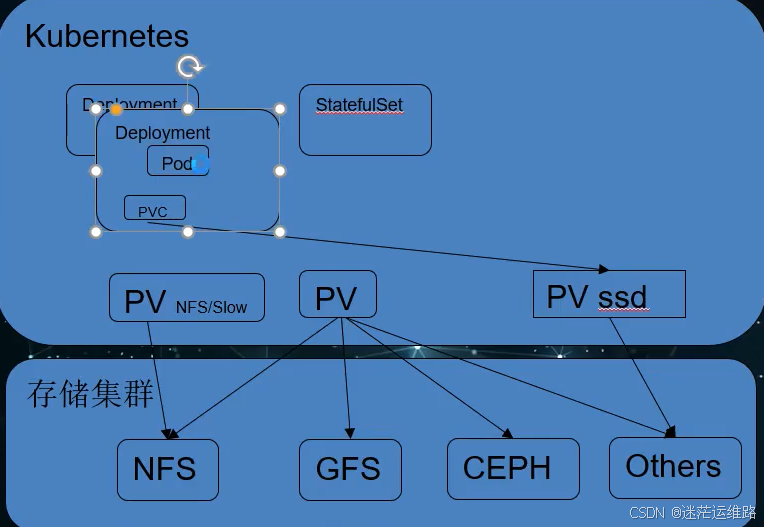
persistentVolume: NFS\CEPH\GFS
pv: 由k8s配置的存储,pv同样是集群的一类资源.pv是对底层网络共享存储的抽象,将共享存储定义为一种"资源"
PVC: 绑定创建的pv,只有storageclassName一样,就可以绑定在一起。是用户对存储资源的一个"申请"
持久化静态的创建PVC、PV
pv挂载nfs
示例创建pv
apiVersion: v1
kind: persistenevolume
metadata:
name: pv001
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle #(回收策略,默认是Recycle)
storageclassName: pv-slow
nfs:
path: /tmp/
server: nfs服务端的主机ip
创建pvc,可以指定命名空间
apiVersion: v1
kind: persistenevolumeclaim
metadata:
name: claim
spec:
volumeMode: Filesystem
accessModes:
- ReadWriteMany
resources:
requests:
storage: 2Gi(pvc的storage必须要小于pv中设定的storage)
storageclassName: pv-slow
创建pod
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: pvc-test
mountPath: /etc/pvc-test
volumes:
- name: pvc-test
persistentVolumeClaim:
claimName: claim
总结: 先创建一个nfs类型的pv,在创建和pv storageclassname一样的pvc
注释详解
当删除一个pod或者deployment资源时,可以选择是否删除pvc。
persistentVolumeReclaimPolicy: 回收策略
recycle 回收,默认是它
retain 保留
delete 删除(当删除pvc后,连接的pv也会被删掉,动态存储需要支持这种回收策略)
capacity: pv的容量
volumeMode: 挂载类型,默认是filesystem,还有一种block
accessModes: pv的访问模式
ReadWriteOnce RWO 可以被单节点以读写的形式挂载
ReadWriteMany RWX 可以被多节点以读写的形式挂载
ReadOnlyMany ROX 可以被多节点以只读的形式挂载
storageclassName: pv的类名。当pv和pvc的类名相同时,才能被绑定
pv状态
1、available 空闲的pv,没有被任何pvc绑定
2、bound 已被pvc绑定
3、Released pvc被删除,但资源未被重新使用
4、Failed 自动回收失败
注意事项
1、创建pvc之后,一直绑定不上pv(pending状态)
pvc的申请空间大于pv的大小
pvc的storageclassname和pv的不一致
pvc的accessModes与pv的不一致
2、创建挂载了pvc的pod之后,一直处于pengding状态
pvc没有创建成功
pvc和pod没在一个namespace中
持久化StorageClass根据PVC动态的创建PV
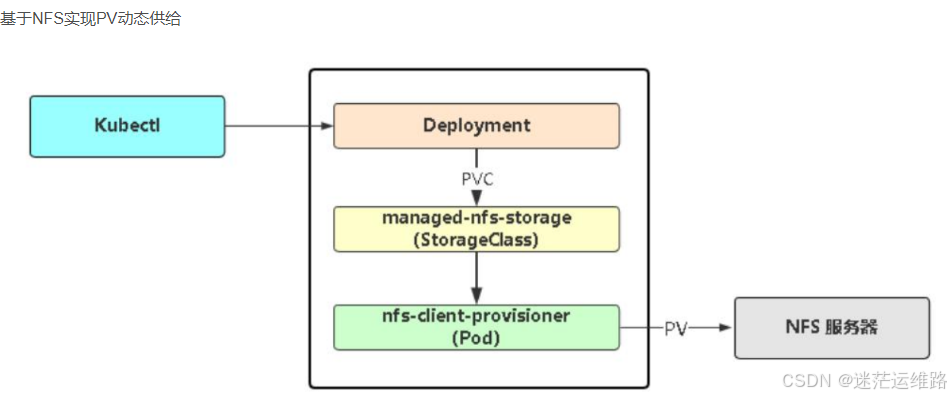
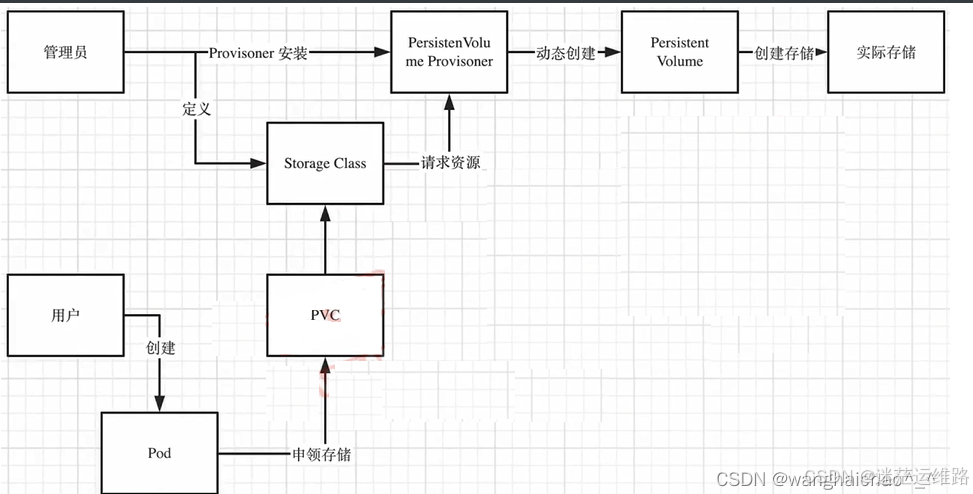
以京东云为例演示动态持久化操作
1、创建storageclass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: jdcloud-sdd
parameters:
fstype: ext4
type: ssd.gp1
provisioner: zbs.csi.jdcloud.com
allowVolumeExpansion: true #表示该存储类允许卷的扩展
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer #表示在Pod首次使用该存储类时才绑定卷.这种绑定模式的好处是可以更加灵活地利用集群中的资源。例如,在多个 Pod 同时请求同一个 StorageClass 的卷时,Kubernetes 可以选择将卷绑定到首先被调度的 Pod 所在的节点上,而不是提前将卷绑定到某个节点并占用资源。
2、storageclass通过provisioner动态的创建pv:
apiVersion: v1
kind: PersistentVolume
metadata:
annotations:
pv.kubernetes.io/provisioned-by: zbs.csi.jdcloud.com
name: pvc-1aa62da3-53fe-41c2-982a-072dc9979a7f
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
claimRef:
apiVersion: v1
kind: PersistentVolumeClaim
name: data-prometheus-0
namespace: lens-metrics
resourceVersion: "22075956"
uid: 1aa62da3-53fe-41c2-982a-072dc9979a7f
csi:
driver: zbs.csi.jdcloud.com
fsType: ext4
volumeAttributes:
fstype: ext4
storage.kubernetes.io/csiProvisionerIdentity: 1617179192728-8081-zbs.csi.jdcloud.com
volumeHandle: vol-05tp0hz6an
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: topology.zbs.csi.jdcloud.com/zone
operator: In
values:
- cn-north-1a
persistentVolumeReclaimPolicy: Delete
storageClassName: default
volumeMode: Filesystem
3、创建pvc示例:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
annotations:
pv.kubernetes.io/bind-completed: "yes"
pv.kubernetes.io/bound-by-controller: "yes"
volume.beta.kubernetes.io/storage-provisioner: zbs.csi.jdcloud.com
volume.kubernetes.io/selected-node: k8s-node-vmb7ym-91dg7wje34
labels:
name: prometheus
name: data-prometheus-0
namespace: lens-metrics
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20G
storageClassName: default
volumeMode: Filesystem
volumeName: pvc-1aa62da3-53fe-41c2-982a-072dc9979a7f
K8S集群网络部分
了解overlay、underlay容器网络
underlay容器网络
代表承载容器的虚拟机或者物理机网络环境能够识别、转发容器ip。开源网络插件方案如Flannel的host-gw模式、calico的bgp模式,容器网络可以不通过隧dao封装,依托于网络插件组件功能(增加路由表)和网络要求(kubernetes管理的节点在同一子网,不跨三层)
overlay容器网络
代表承载容器的虚拟机或者物理机网络环境本身不能够识别、转发容器ip,需要通过每个虚拟机或者物理机上的封包、解包进程处理再转发给容器。开源网络插件方案如Flannel的vxlan模式、calico的ipip模式,容器网络通过节点隧道封装后基于承载网络转发,只要求kubernetes管理的节点三层网络可达。
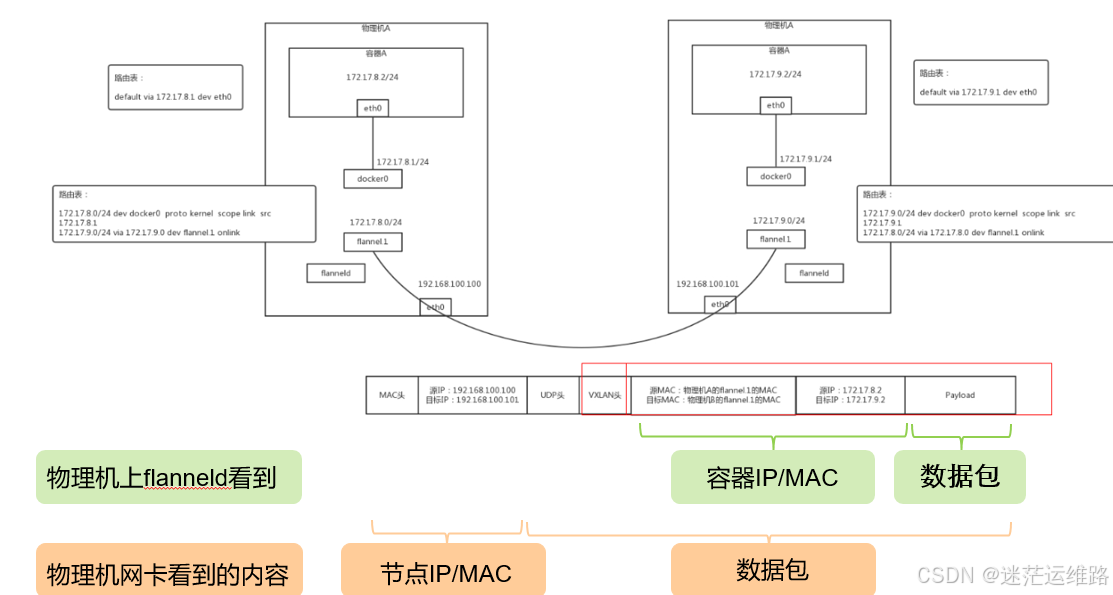
一、网络通信
(1)容器间通信:
同一个pod内的多个容器间的通信,通过lo即可实现;
(2)pod之间的通信:
同一节点的pod之间通过cni网桥转发数据包。
不同节点的pod之间的通信需要网络插件支持。
(3)pod和service通信:
通过iptables或ipvs实现通信,ipvs取代不了iptables,因为ipvs只能做负载均衡,而做不了nat转换。
(4)pod和外网通信:
iptables的MASQUERADE。
(5)Service与集群外部客户端的通信:
(ingress、nodeport、loadbalancer)
二、网络虚拟设备对
1、什么是网络虚拟设备对?veth pair
veth是虚拟以太网卡的缩写。veth设备总是成对的,因此称为veth pair。一端发送数据,另一端接收数据,常被用于跨网络空间之间的通信。但如果仅有veth pair设备,容器是无法访问外部网络的,因为从容器发出的数据包实际上进入了veth pair设备对的协议栈,如果容器需要访问网络还需要使用网桥等技术将veth pair设备接收的数据包通过某种方式转发出去.
下图是veth pair的基本工作原理图
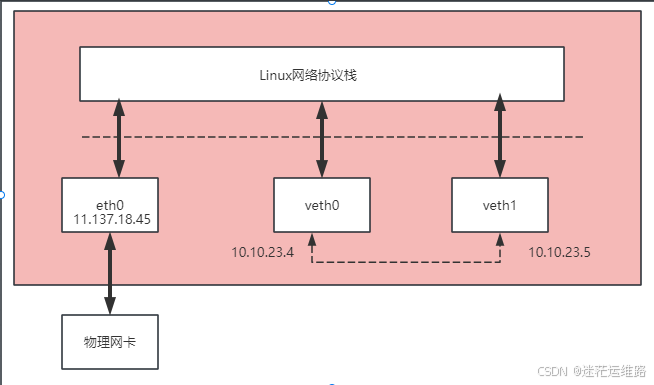
2、容器组网模型veth pair+bridge的模式
a)、如何查看容器的网卡与主机的哪个veth设备对是成对的关系?
方法一
在容器查看该文件中的值 cat /sys/class/net/eth0/iflink
在主机查看 /sys/class/net下面的所有的子目录ifindex的值和容器里查出来的值进行对比,一样的话就是一个设备对
方法二
在容器执行 ip link show eth0,如下所示
116: eth0@if118: xxxx
从这个可以看出116是eth0接口的index,117是和它成对的veth的index
在主机上执行 ip link show | grep 117即可查看设备对
bridge桥的介绍
顾名思义是linux系统中的网桥,但是桥的行为更像是一台虚拟的网络交换机,不能跨主机连接网络设备。与其他的网络设备相比,普通的网络设备只有两端,总一端进的数据会从另一端出去。但桥则由多个端口,数据可以从任何端口进来,出去的时候取决于目的MAC地址。
三、vxlan
1、vxlan协议原理:
vxlan隧道网络方法相比改造传统的二三层网络,对原有网络架构影响小,可直接在原有的网络基础上架设一层新的网络。它创建在原来的IP网络(网络层)三层上,只要是IP能互相通信就能使用vxlan。
2、vxlan介绍以及实现过程:
1、vxlan全称是虚拟可扩展的局域网,它是一种overlay覆盖网络技术,通过三层的网络来搭建虚拟的二层网络.
2、它创建在原来的IP网络(三层)上,只要是三层可达(能够通过IP互相通信)的网络就能部署vxlan。在每个端点上都有一个Vtep负责vxlan协议报文的封包和解包,也就是在虚拟报文上封装vtep通信的报文头部。
VTEP: vxlan网络的边缘设备,用来进行vxlan报文的处理(封包和解包).vtep可以是网络设备(比如交换机)。它的作用就是对二层数据帧进行封装和解封装,且这个工作的执行流程,全部是在内核里完成的。
VNI: VnI是VETP设备识别某个数据帧是不是应该归自己处理的重要标识。这个值在1~2^24之间
vxlan通信流程:
每台设备上已经有了VTEP设备和相应的路由规则,源容器发出请求后,数据包包含了源容器ip和目的容器ip,这个原始数据包首先会通过虚拟网卡对出现在docker0网桥上,然后根据路由规则到达VTEP设备,且要发往的网关地址为目的VTEP设备的ip,然后VTEP会从ARP表里获取到对应的MAC地址,并进行二层封包,得到一个二层数据帧,我们把它称为“内部数据帧”。
接下来,Linux 内核会在“内部数据帧”前面,加上一个特殊的 VXLAN 头,用来表示这实际上是一个 VXLAN 要使用的数据帧,而这个 VXLAN 头里有一个重要的标志叫作 VNI,它是 VTEP 设备识别某个数据帧是不是应该归自己处理的重要标识,而在 Flannel 中,VNI 的默认值是 1
然后,Linux 内核会从FDB数据库里读取到对应的目的宿主机ip,把“内部数据帧”和目的宿主机ip封装进一个 UDP 包里,我们把它称为“外部数据帧”,这个“外部数据帧”里包含了源节点ip和目的节点ip,然后Linux内核会在这个“外部数据帧”前面加上目的宿主机的MAC地址,这样,封包工作就宣告完成了。
接下来,源宿主机上的 flannel.1 设备就可以把这个数据帧从源宿主机的 eth0 网卡发出去,数据帧会经过宿主机网络来到目的宿主机的 eth0 网卡。这时候,目的宿主机的内核网络栈会发现这个数据帧里有 VXLAN Header,并且 VNI=1。所以 Linux 内核会对它进行拆包,拿到里面的内部数据帧,然后根据 VNI 的值,把它交给 flannel.1 设备。而 flannel.1 设备则会进一步拆包,取出“原始 IP 包”,然后根据路由规则,将它交给docker0网桥,经过虚拟网卡对就进入到了目的容器里。
5、vxlan小结:
工作在二层的overlay网络;
只有一次用户态到内核态之间的数据拷贝;
UDP 封装和解封装的过程,是由flannel.1设备在内核态完成。
四、k8s网络基础
1、IP地址分配
节点Ip地址范围、podIP地址、服务Ip地址
2、pod出站流量
pod-->pod
pod-->svc
pod-->集群外
(在pod到集群外的流量会通过SNAT来处理,将数据包的源从pod内部的IP:PORT转换为宿主机的IP:PORT,当集群外流量至pod内部时,与其相反)
CNI介绍及集群网络选型
容器网络接口(container network Interface),实现k8s集群的pod资源能够跨宿主机进行网络通信及管理
CNI网络插件
Flannel、Calico、kube-route、canal等
CNI Plugin负责给容器配置网络,包括两个基本接口:
配置网络接口
清理网络接口
IPAM Plugin负责给容器分配IP地址,主要实现包括host-local和dhcp
容器网络创建流程
1、kubelet先创建pause容器生成对应的network namespace
2、调用driver,因为配置的是CNI,所以会调用CNI相关代码,识别CNI的配置目录为/etc/cni/net.d
3、CNI driver根据配置调用具体的CNI插件,二进制调用,可执行文件目录为/xx/cni/bin
4、CNI插件给pause容器配置正确的网络,pod中其他容器都是用pause的网络
flannel-vxlan网络模型剖析
1、什么是覆盖网络?
需要在已有的宿主机网络上,再通过软件构建一个覆盖在已有宿主机网络之上的、可以把所有容器连通在一起的虚拟网络,这种技术就称为覆盖网络。
2、flannel实现overlay(覆盖网络)网络模式通常有这几种:
1、udp
udp封包使用了flannel自定义的一种包头协议,数据是在linux的用户态进行封包和解包的,因此当数据进入主机后,需要经历两次内核态到用户态的转换。
2、vxlan
vxlan封包采用的是内置在linux内核里的标准协议,虽然封包结构比udp复杂,但所有操作是在内核完成的,实际传输效率高于udp模式。
3、host-gw(在两台机器中互相添加一条路由规则)
3、查看集群中使用的flannel网络是什么类型命令(默认是vxlan类型):
kubectl -n kube-system exec flannelpod名 cat /xx/kube-flannel/net-conf.json
{
"Network":"10.244.0.0、16",
"Backend":{
"Type": "vxlan"
}
}
Flannel部分
flannel设计目的
是为集群中的所有节点重新规划IP地址的使用规则,从而使得集群中的不同节点主机创建的容器都具有全集群"唯一"且"可路由的IP地址",并让属于不同节点上的容器能够直接通过内网IP通信。
flanneld启动时主要做了以下几个动作:
1、从etcd中获取network(大网)的配置信息
2、划分子网subnet,并在etcd中进行注册
3、将子网信息记录到flannel维护的/run/flannel/subnet.env文件中
4、将subnet.env转写为docker的环境变量文件/run/flannel/docker
https://www.cnblogs.com/zhangpeiyao/p/13929604.html
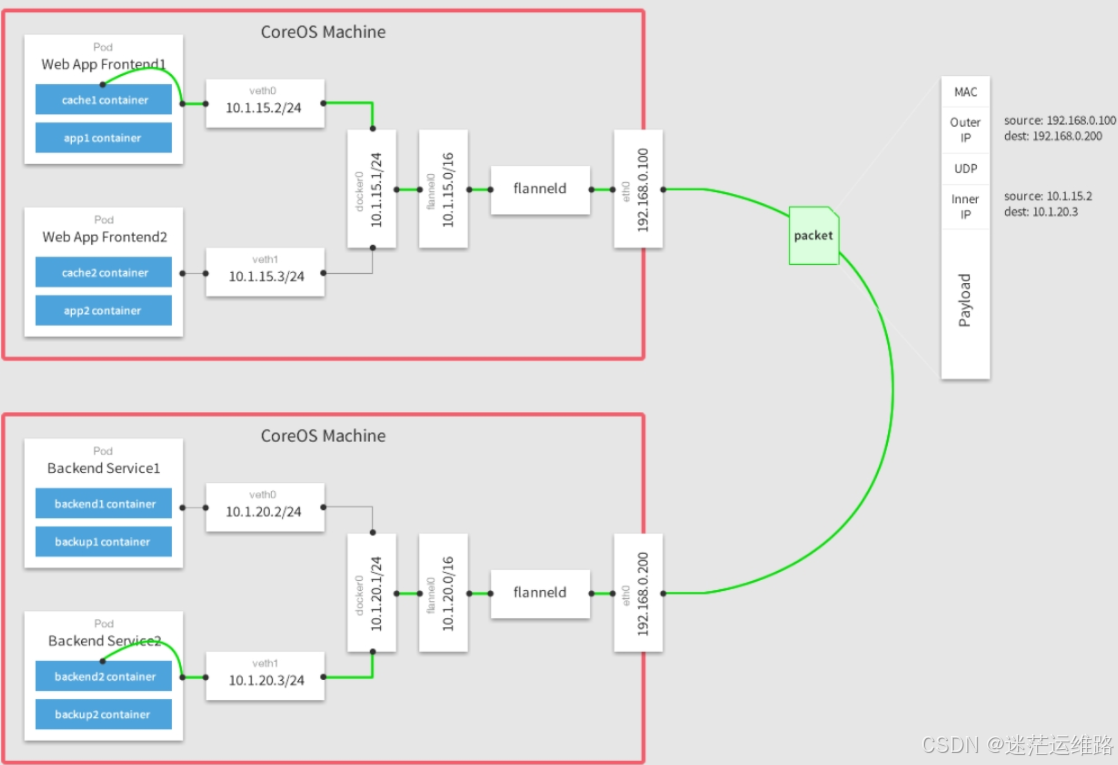
1、Cni0: 网桥设备,每创建一个pod都会创建一对 veth pair。其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡)。Pod中从网卡eth0发出的流量都会发送到Cni0网桥设备的端口(网卡)上。
2、Flannel.1: overlay网络的设备,用来进行 vxlan 报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端。
3、Flanneld: flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac,ip等网络数据信息。
flannel的作用
1、协助k8s,给每一个Node上的Docker容器分配互相不冲突的IP地址。
2、建立一个覆盖网络(overlay network),通过这个覆盖网络,将数据包原封不动的传递到目标容器。覆盖网络是建立在另一个网络之上并由其基础设施支持的虚拟网络。覆盖网络通过将一个分组封装在另一个分组内来将网络服务与底层基础设施分离,在将封装的数据包转发到端点后,将其解封装。
3、创建一个新的虚拟网卡Flannel0接收docker网桥的数据,通过维护路由表,对接受到的数据进行封包和转发。
4、etcd保证了所有node上flanneld所看到的配置是一致的。同时每个node上的flanned监听etcd上的数据变化,实时感知集群中node的变化。
host-gw模型图(host-gw根本原理就是在两台机器中互相添加一条路由规则),前提是两台宿主机的ip必须在同一个网络层级中,有一个共同的网关。
host-gw
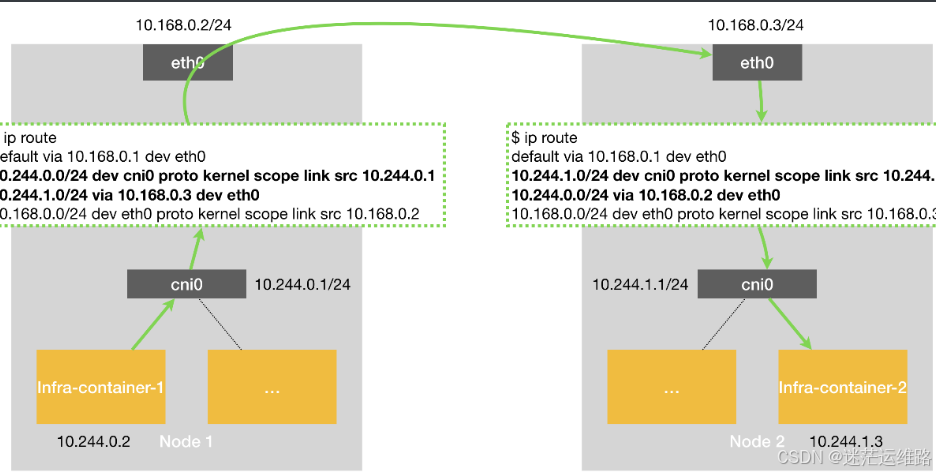
1、host-gw的工作原理是将每个Flannel子网的"下一跳"设置成该子网对应的宿主机的IP地址。这台主机会充当这条容器通信路径里的"网关"
host-gw数据流向:
1、flanneld会在宿主机上创建相应的路由规则,设置到某一目的网段的的数据包,应该经过本机的 eth0 设备发出去,且下一跳地址是目的主机ip。
2、所以,当 IP 包从网络层进入链路层封装成帧的时候,eth0 设备就会使用下一跳地址对应的 MAC 地址,作为该数据帧的目的 MAC 地址,这样,这个数据帧就会从 源宿主机通过宿主机的二层网络顺利到达目的宿主机上。目的宿主机拿到数据包后,根据路由表进入cni0网桥,进而进入到目的容器中。
在这种模式下,容器通信的过程就免除了额外的封包和解包带来的性能损耗。根据实际的测试,host-gw 的性能损失大约在 10% 左右,而其他所有基于 VXLAN“隧道”机制的网络方案,性能损失都在 20%~30% 左右
route add -net 172.7.21.0/24 gw 10.4.7.21 dev eth0
route add -net 172.7.22.0/24 gw 10.4.7.22 dev eth0
vxlan
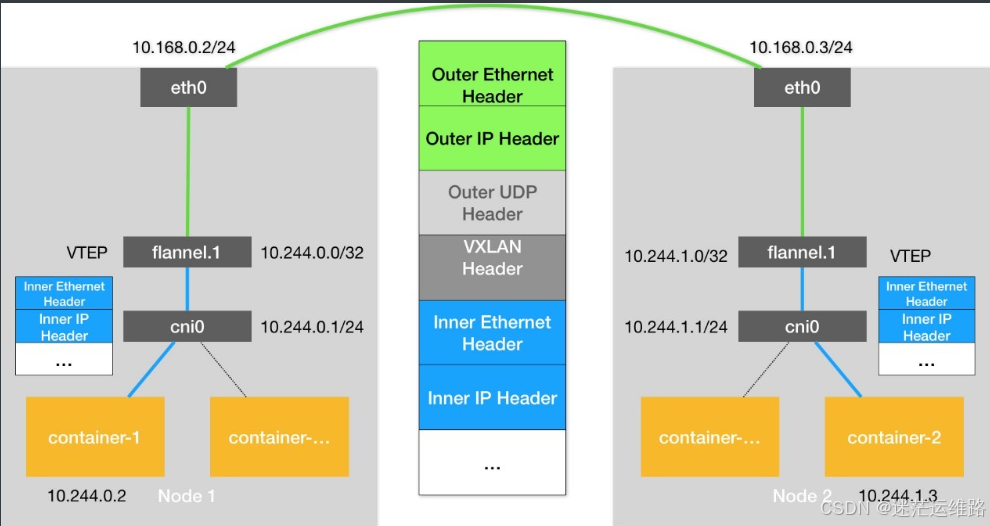
https://www.cnblogs.com/zhangpeiyao/p/13929604.html
https://juejin.cn/post/6844904099218096142
vxlan模式下网络数据流向: (面试说法)
1. pod1向pod2发送ping,查找pod1路由表,运用veth-pair技术把数据包发送到cni0(10.244.1.1)
2. cni0查找node1路由,把数据包转发到flannel.1
3. flannel.1虚拟网卡设备对,收到报文后将按照vtep的配置进行封包,首先通过etcd得知pod2属于Node2,并得到node2ip地址,然后通过节点A中的转发表得到节点B对应的vtep的MAC地址,且这个MAC地址不是通过组播学习的,而是通过Api server处watch Node发现的,根据flannel1.1设备创建时的设置参数(VNI、local、IP、PORT)进行封包。
4. 通过node1与node2直接的网络连接,vxlan包到达node2的eth1接口
5. 通过UDP端口8472传输VXLAN数据包给vtep设备flannel.1进行解包
6. 解封装后的IP包匹配node2中的路由表,内核将IP包转发给cni0
7. cni0网桥再把数据包转发给pod2
注意事项:
在vxlan模式下,数据是由内核转发的,flannel不转发数据,仅动态设置ARP和FDB表项
流程分析:(详细分析)
一、发送流程阶段:
1. 首先Pod1 ping Pod2 查找pod1路由表,把数据包发送到cni0(10.244.22.1) (容器内进行ping)
Ping包的dst ip 为 10.244.27.55
根据路由匹配到第二条路由表项,去往10.244.0.0/12的包都转发给10.244.22.1 (进入node08)
2. cni0查找node1路由,把数据包转发到flannel.1。
10.244.22.1为node8的cni0的ip地址
cni0到docker0再到flannel.1 (通过node12节点的route -n 或者 ip r 可以查看到)pod eth0-->cni0-->flannel.1
Destination Gateway Genmask Flags Metric Ref Use Iface
10.244.22.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
10.244.22.0 10.244.22.0 255.255.255.0 UG 0 0 0 flannel.1
10.244.22.0/24 dev cni0 proto kernel scope link src 10.244.22.1
根据最长匹配原则,匹配到图上的一条路由表项。去往10.244.22.0/24 网段的包,发送10.244.22.0网关,网关设备是flannel.1
3. flannel.1为vxlan设备,当数据包来到flannel.1时,需要将数据包封装起来
此时的dst ip为10.244.27.55 src ip为10.244.22.42
数据包继续封装需要知道10.244.22.42 ip地址对应的mac地址
flannel.1不会发送arp请求去获得10.244.27.55的mac地址,
而是由Linux kernel将一个“L3 Miss”事件请求发送给用户空间的flanned程序。
Flanned程序收到内核的请求事件之后,
从etcd查找能够匹配该目的地址的子网的flannel.1设备的mac地址,
即发往的pod所在host中flannel.1设备的mac地址。
Flannel在为Node节点分配ip网段时记录了所有的网段和mac等信息
4. flanned将查询到的信息放入master node host的arp cache表中
ip n |grep cni0的网关地址(10.244.22.0)
10.244.22.0 dev flannel.1 lladdr ba:1e:ef:73:ba:4f PERMANENT
二、接收数据
1.目的node节点flannel1接收到数据包之后kernal将识别出这是一个vxlan包,
将包拆开之后转给节点上的flannel.1设备。这样数据包就从发送节点到达目的节点
2、目的地址为10.244.27.55,flannel.1查找自己的路由表,根据路由表完成转发。
route -n
Destination Gateway Genmask Flags Metric Ref Use Iface
10.244.27.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
根据最长匹配原则,flannel.1将去往10.244.27.0/24的流量转发到cni0上去。
3、cni0到pod
cni0是一个虚拟网桥设备。当cni0拿到数据包之后,通过veth pair,将数据包发送给pod。
在172.28.25.62node上通过arp -n |grep 10.244.27.55解析出目的pod的mac地址
4.在进入到目的pod的容器中,查看ifconfig,发现此处的mac地址等于arp解析的mac地址
5.在获知目的pod mac地址后,cni0会通过veth pair将数据包发到pod eth0网卡veth pair接口,
至此不同node 节点的通信圆满结束
Calico
https://www.cnblogs.com/goldsunshine/p/10701242.html
1、calico是一个纯3层的数据中心网络方案(局域网网络方案),能够提供可控的VM、容器、裸机之间的IP通信。容器在主机内外都通过路由规则连通(主机内不会创建网络设备对)
2、Kubernetes网络之Calico为何流行?
Calico在每个计算节点都利用Linux Kernel实现了一个高效的虚拟路由器vRouter来负责数据转发。每个 vRouter 都通过BGP协议把在本节点上运行的容器的路由信息向整个Calico网络广播,并自动设置到达其他节点的路由转发规则。Calico保证所有容器之间的数据流量都是通过IP路由的方式完成互联互通的。Calico节点组网时可以直接利用数据中心的网络结构(L2或者L3),不需要额外的NAT、隧道或者Overlay Network,没有额外的封包解包,能够节约CPU运算,提高网络效率。
Calico架构图
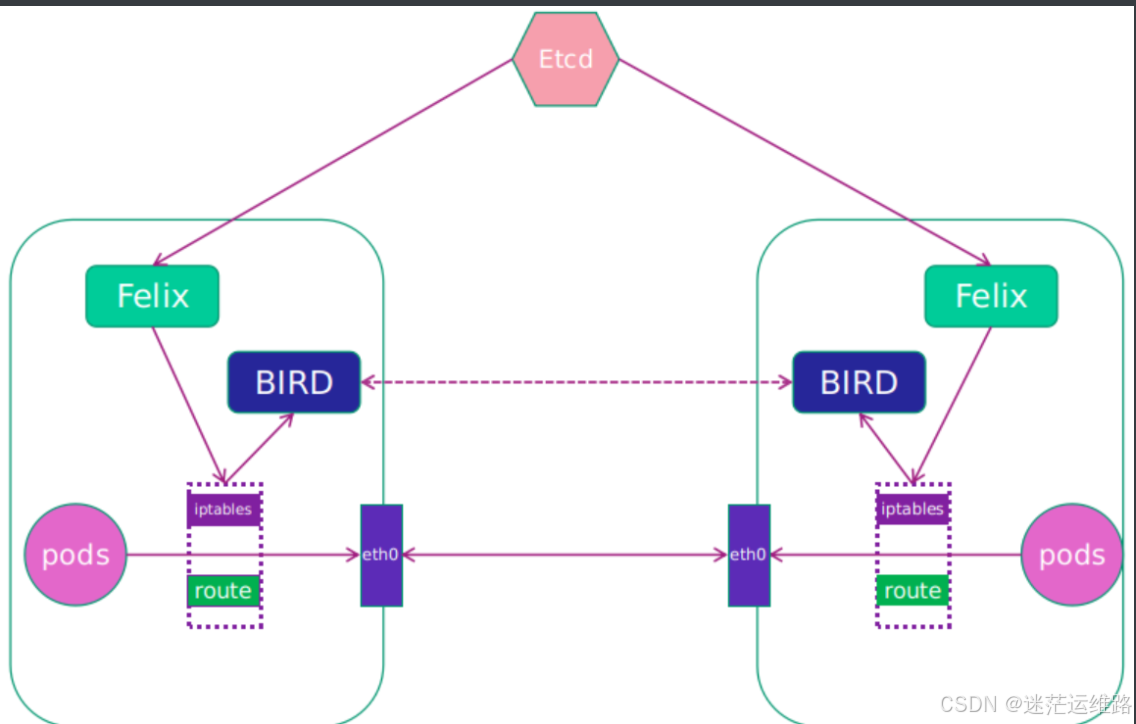
Calico网络模型主要工作组件:
1、Felix: 运行在每一台主机上的agent进程,主要负责监听网络接口管理和监听、路由、ARP管理、ACL管理和同步、状态上报等.监听ETCD中心存储,从而获取事件。
2、BGP Client(BIRD): Calico 为每一台主机部署一个 BGP Client,使用BIRD实现,BIRD是一个单独的持续发展的项目,实现了众多动态路由协议比如 BGP、OSPF、RIP 等。在 Calico 的角色是监听主机上由Felix注入的路由信息,然后通过BGP协议广播告诉剩余主机节点,从而实现网络互通
架构特点:
由于Calico是一种纯三层的实现,因此可以避免与二层方案相关的数据包封装的操作,中间没有任何的NAT,没有任何的overlay,所以它的转发效率可能是所有方案中最高的,因为它的包直接走原生TCP/IP的协议栈,它的隔离也因为这个栈而变得好做。因为TCP/IP的协议栈提供了一整套的防火墙的规则,所以它可以通过IPTABLES的规则达到比较复杂的隔离逻辑.
Calico网络模式
1、IPIP
字面理解就是把一个IP数据包套在另一个IP包里,即把IP层封装到IP层的一个隧道。它的作用相当于一个基于IP层的网桥。一般来说,普通的网桥是基于mac层的,根本不需 IP,而这个 ipip 则是通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。
2、BGP
基于路由转发,每个节点通过BGP协议同步路由表,写到宿主机。
边界网关协议(Border Gateway Protocol, BGP)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议。BGP,通俗的讲就是讲接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP,BGP 机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统
IPIP网络图
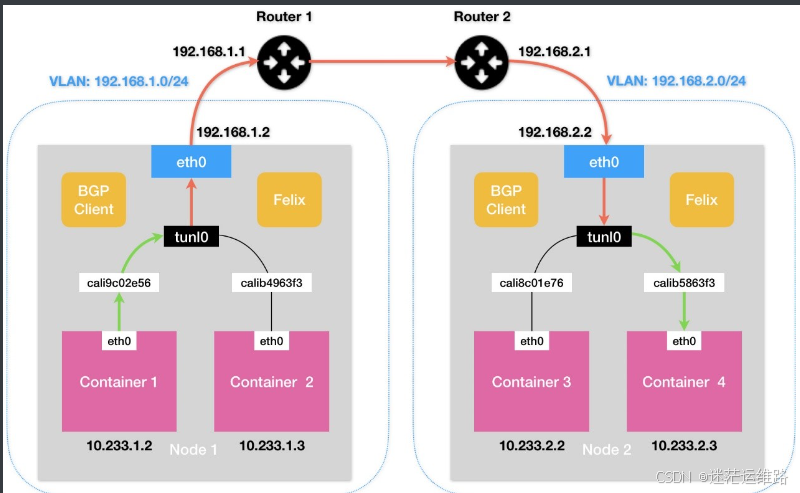
网络流向分析ipip
https://www.cnblogs.com/goldsunshine/p/10701242.html
背景:
1、一个msater节点,ip 172.171.5.95,一个node节点 ip 172.171.5.96
2、创建一个daemonset的应用,pod1落在master节点上 ip地址为192.168.236.3,pod2落在node节点上 ip地址为192.168.190.203
3、pod1 ping pod2
开始分析:
1、查看pod1上的路由信息
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.0 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
# 根据路由信息,ping 192.168.190.203,会匹配到第一条。第一条路由的意思是:去往任何网段的数据包都发往网管169.254.1.1,然后从eth0网卡发送出去。
路由表中Flags标志的含义:
U up表示当前为启动状态
H host表示该路由为一个主机,多为达到数据包的路由
G Gateway 表示该路由是一个网关,如果没有说明目的地是直连的
D Dynamicaly 表示该路由是重定向报文修改
M 表示该路由已被重定向报文修改
2、查看master节点路由信息
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.171.0.1 0.0.0.0 UG 0 0 0 eth0
192.168.190.192 172.171.5.96 255.255.255.192 UG 0 0 0 tunl0
#当ping包来到master节点上,会匹配到路由tunl0。该路由的意思是:去往192.169.190.192/26的网段的数据包都发往网关172.171.5.96。因为pod1在5.95,pod2在5.96。所以数据包就通过设备tunl0发往到node节点上
3、查看node节点上路由信息
当node节点网卡收到数据包之后,发现发往的目的ip为192.168.190.203,于是匹配到红线的路由。该路由的意思是:192.168.190.203是本机直连设备,去往设备的数据包发往caliadce112d250。
那么该设备是什么呢?如果到这里你能猜出来是什么,那说明你的网络功底是不错的。这个设备就是veth pair的一端。在创建pod2时calico会给pod2创建一个veth pair设备。一端是pod2的网卡,另一端就是我们看到的caliadce112d250。下面我们验证一下。在pod2中安装ethtool工具,然后使用ethtool -S eth0,查看veth pair另一端的设备号。
pod2 网卡另一端的设备好号是18,在node上查看编号为18的网络设备,可以发现该网络设备就是caliadce112d250
所以,node上的路由,发送caliadce112d250的数据其实就是发送到pod2的网卡中。ping包的旅行到这里就到了目的地。
4、顾名思义,IPIP网络就是将IP网络封装在IP网络里。IPIP网络的特点是所有pod的数据流量都从隧道tunl0发送,并且在tunl0这增加了一层传输层的封包。
网络流向分析BGP
https://www.cnblogs.com/goldsunshine/p/10701242.html
1、修改配置
在安装calico网络时,默认安装是IPIP网络。calico.yaml文件中,将CALICO_IPV4POOL_IPIP的值修改成 "off",就能够替换成BGP网络。
2、与IPIP对比
最大的不同之处就是没有了隧道设备 tunl0。 前面介绍过IPIP网络pod之间的流量发送tunl0,然后tunl0发送对端设备。BGP网络中,pod之间的流量直接从网卡发送目的地,减少了tunl0这个环节。
3、网络流向分析
a、pod1 ping pod2
b、根据pod1中的路由信息,ping包通过eth0网卡发送到master节点上。master节点上路由信息。根据匹配到的 192.168.190.192 路由,该路由的意思是:去往网段192.168.190.192/26 的数据包,发送网段172.171.5.96。而5.96就是node节点。所以,该数据包直接发送了5.96节点。
c、node节点上的路由信息。根据匹配到的192.168.190.192的路由,数据将发送给 cali6fcd7d1702e设备,该设备和上面分析的是一样,为pod2的veth pair 的一端。数据就直接发送给pod2的网卡。
d、当pod2对ping包做出回应之后,数据到达node节点上,匹配到192.168.236.0的路由,该路由说的是:去往网段192.168.236.0/26 的数据,发送给网关 172.171.5.95。数据包就直接通过网卡ens160,发送到master节点上。
IPIP与BGP网络对比
IPIP网络:
流量:tunlo设备封装数据,形成隧道,承载流量。
适用网络类型:适用于互相访问的pod不在同一个网段中,跨网段访问的场景。外层封装的ip能够解决跨网段的路由问题。
效率:流量需要tunl0设备封装,效率略低
BGP网络:
流量:使用路由信息导向流量
适用网络类型:适用于互相访问的pod在同一个网段,适用于大型网络。
效率:原生hostGW,效率高
Flannel与Calico的优缺点
Flannel
优点:
flannel基于UDP协议实现Overlay(覆盖)网络,实现了容器之间的跨主机通信,且支持多种后端网络(vxlan|host-gw|udp),进行网络隔离与通信。
缺点:
使用NAT技术,可能会出现性能瓶颈而导致网络延迟较高
不提供安全保障,适用于k8s小集群规模
Calico
优点:
高性能: calico使用BGP协议实现物理网络和网络虚拟化之间的互联,具备高性能、高可靠性、低延迟的特点
安全可靠: calico可以提供完善的网络安全功能,包括ACL、加密、认证等多种安全性能保障
可扩展: 具备高度扩展性,很好的适应大规模应用场景
calico采用基于BGP协议的物理网络架构,通过路由器实现了容器之间的通信,将容器和物理网络无缝集成。calico的核心组件包括Felix、etcd、BGP Client和BGP Route Reflector。其中Felix负责路由配置和ACL规则的处理,etcd负责存储和管理配置信息,BGP Client和BGP Route Reflector负责将虚拟网络与物理网络进行互联
缺点:
calico需要依赖etcd等组件进行配置和管理,过程较为复杂
使用一条路由命令让非k8s集群的机器直接访问到集群内的pod
要让非 Kubernetes 集群的机器可以直接访问到 Kubernetes 集群内的 Pod,可以通过创建一条 iptables nat 规则来实现。具体操作如下:
1、获取目标 Pod 的 IP 地址:使用 kubectl get pod <pod-name> -n <namespace> -o wide 命令获取目标 Pod 的 IP 地址。
2、在 Kubernetes Master 节点上创建一个 iptables 规则:使用以下命令创建 iptables 规则,将外部请求的目标地址和端口修改为目标 Pod 的 IP 地址和对应的端口号。
iptables -t nat -A PREROUTING -p tcp -d <external-ip-address> --dport <external-port> -j DNAT --to-destination <pod-ip-address>:<pod-port>
其中:
<external-ip-address> 是非 Kubernetes 集群机器的 IP 地址。
<external-port> 是非 Kubernetes 集群机器的请求端口。
<pod-ip-address> 是目标 Pod 的 IP 地址。
<pod-port> 是目标 Pod 的端口号。
保存规则:使用 iptables-save > /etc/iptables/rules.v4 命令将规则保存到 /etc/iptables/rules.v4 文件中,以便下次启动时自动加载。

















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









