







 文章介绍了如何使用FineBI进行数据可视化,包括FineBI的下载与安装,配置数据库连接到MySQL的finedb,以及连接和配置ClickHouse数据库。接着,文章详细阐述了在FineBI中导入数据、编辑图表和创建仪表盘的操作步骤,最后总结了整个广告数仓项目的完成。
文章介绍了如何使用FineBI进行数据可视化,包括FineBI的下载与安装,配置数据库连接到MySQL的finedb,以及连接和配置ClickHouse数据库。接着,文章详细阐述了在FineBI中导入数据、编辑图表和创建仪表盘的操作步骤,最后总结了整个广告数仓项目的完成。
系列文章目录
广告数仓:采集通道创建
广告数仓:数仓搭建
广告数仓:数仓搭建(二)
广告数仓:全流程调度
广告数仓:可视化展示
文章目录
前言
今天来记录一下广告数仓的最后一部分。可视化展示
一、FineBI
FineBI是国内的一款开源的,大数据可视化工具,分为免费版和收费板,实验采用免费版。
因为上次我们完成了数据导出,所以我们不需要再开任何环境
1.FineBI下载
官网
因为这个软件是国内的,速度没问题,就直接官网下载就行,或者找个别人下载好的安装脚本。
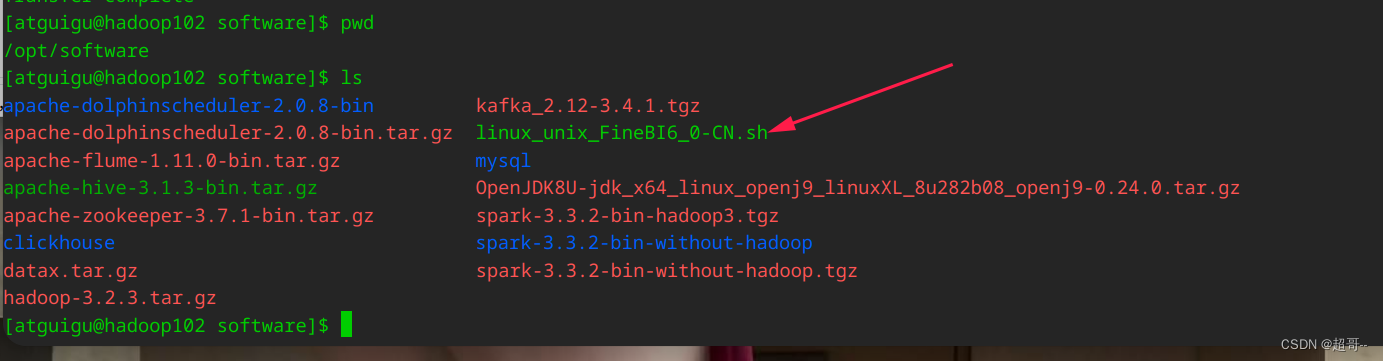
2.软件安装
bash linux_unix_FineBI6_0-CN.sh
大部分参数,无脑默认就行,就有个地方略微修改一下。
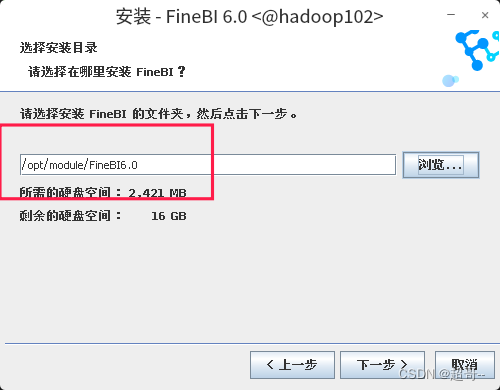
剩下的都不需要修改。
3.配置数据库
在mysql中创建源数据库。
CREATE DATABASE `finedb` DEFAULT CHARACTER SET utf8 COLLATE utf8_bin;
然后安装完成后访问web网站
http://hadoop102:37799/webroot/decision
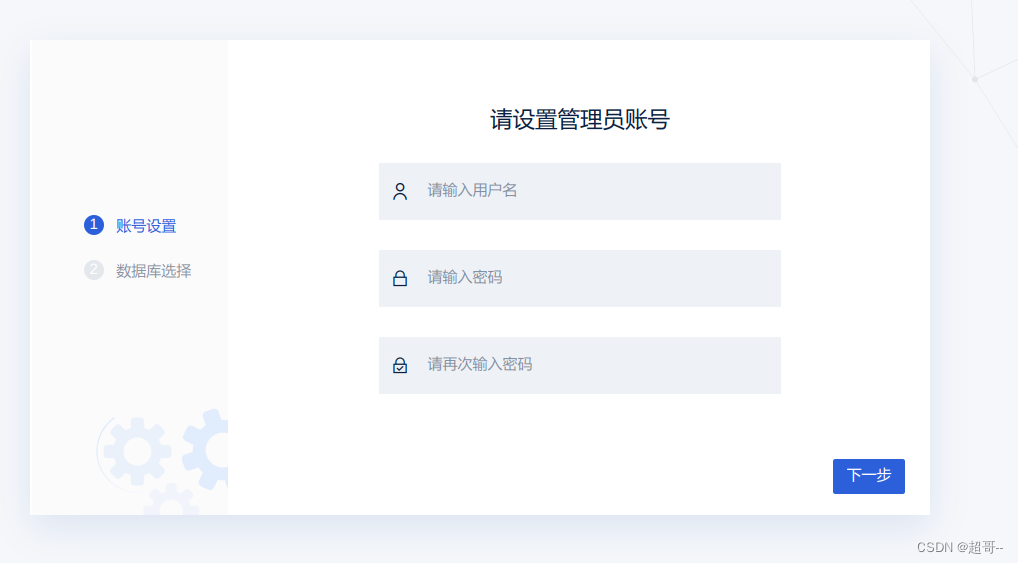
随便设置,但是要记住。
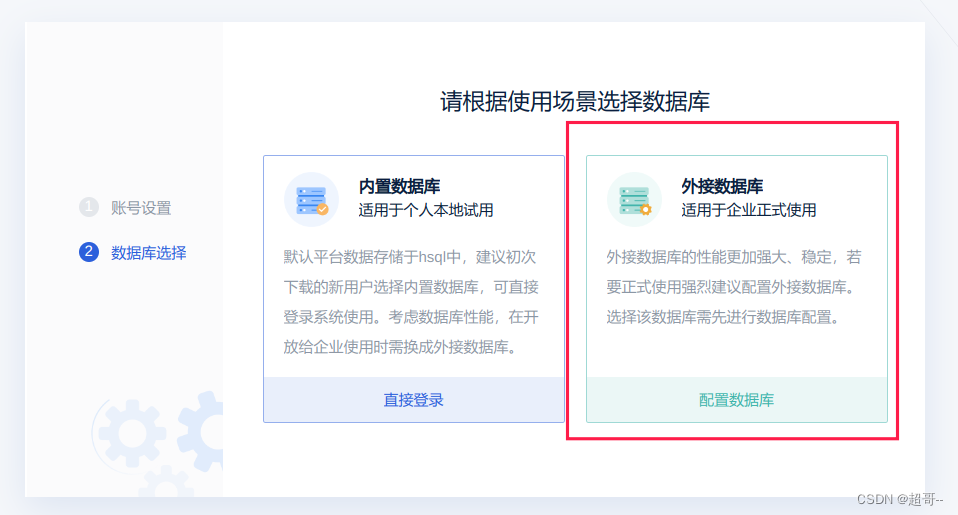
配置咱们刚刚创建的数据库。
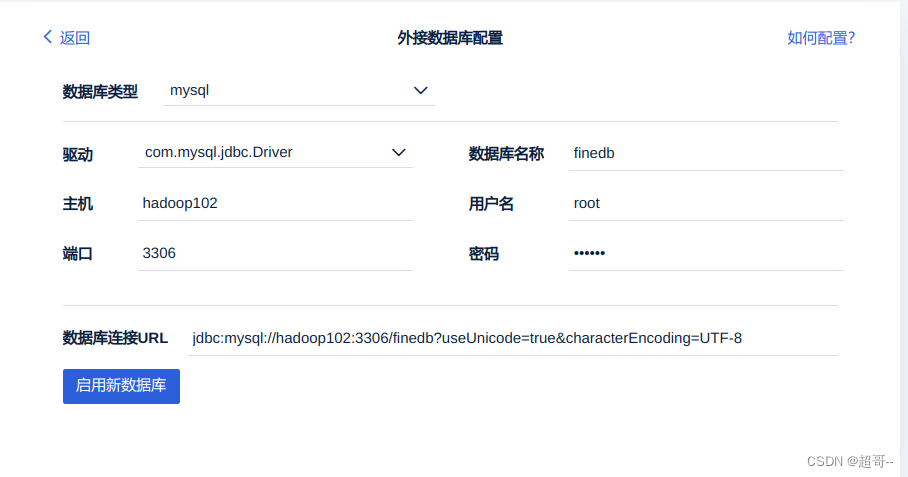
然后等待创建完成即可。
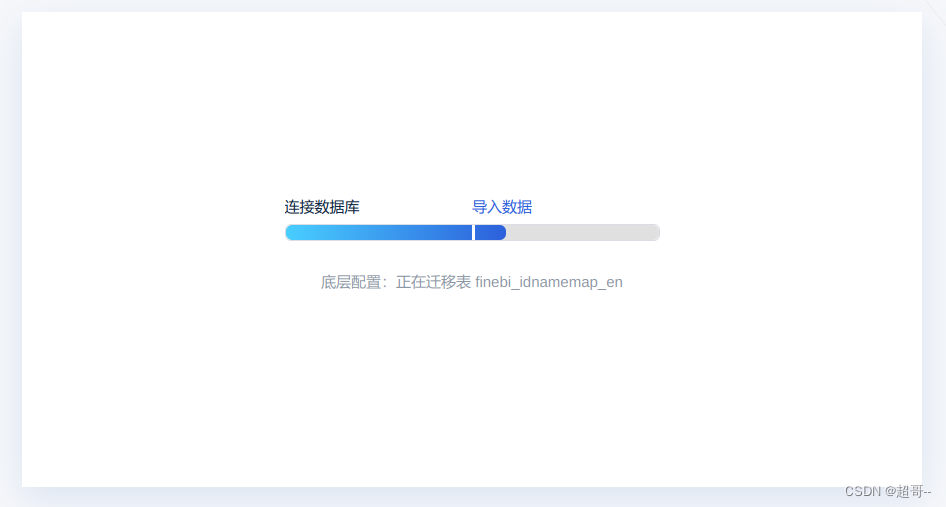
之后登录FineBI输入账号密码,出现以下界面,代表安装完成。

二、数据可视化
1.开启ClickHOuse
确认clickhouse数据库开启。
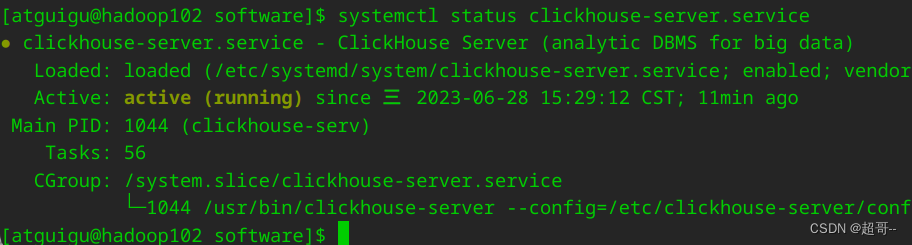
2.连接数据库
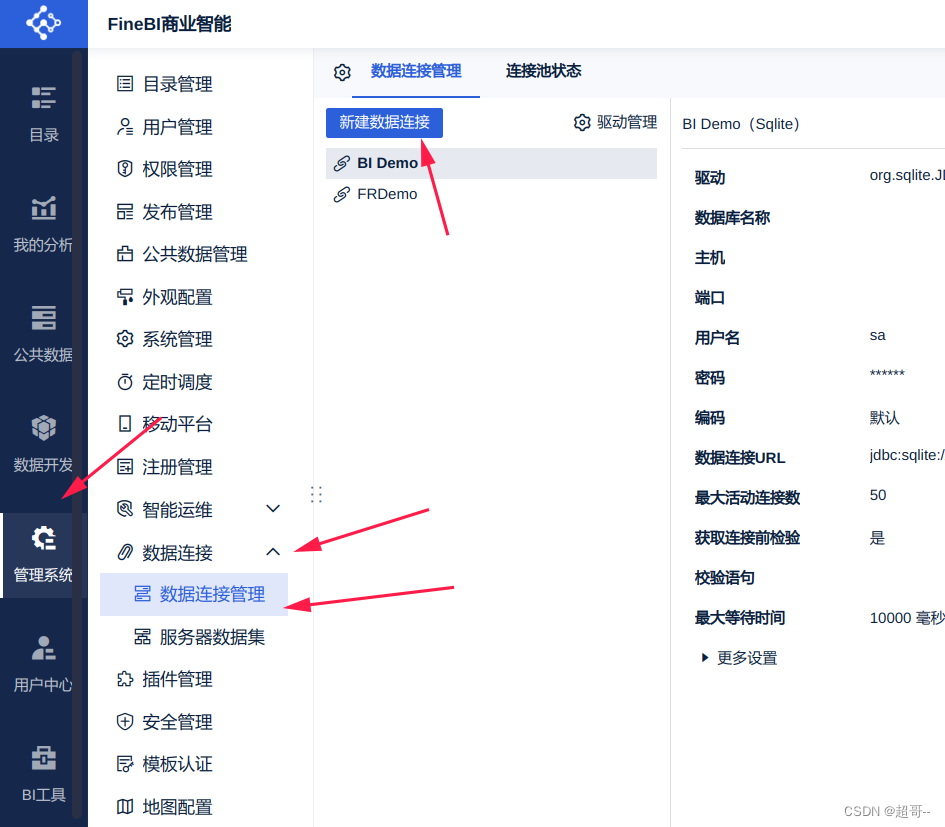
FineBi已经提供了Clickhouse的连接

但是她没有提供jar驱动,需要咱们提前下载。
下载地址
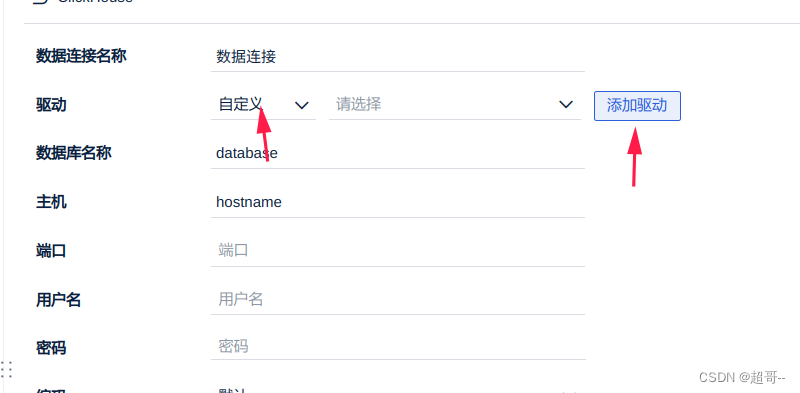
3.添加驱动
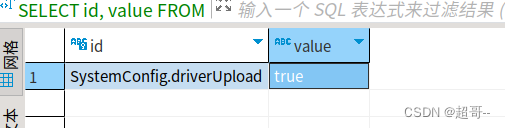
他有可能保存无法上传(我第一次没遇到),我们需要修改数据的一个值。
SELECT id, value
FROM finedb.fine_conf_entity WHERE id LIKE "SystemConfig.driverUpload";
把它修改成true
然后重启以下FineBI后可以上传了
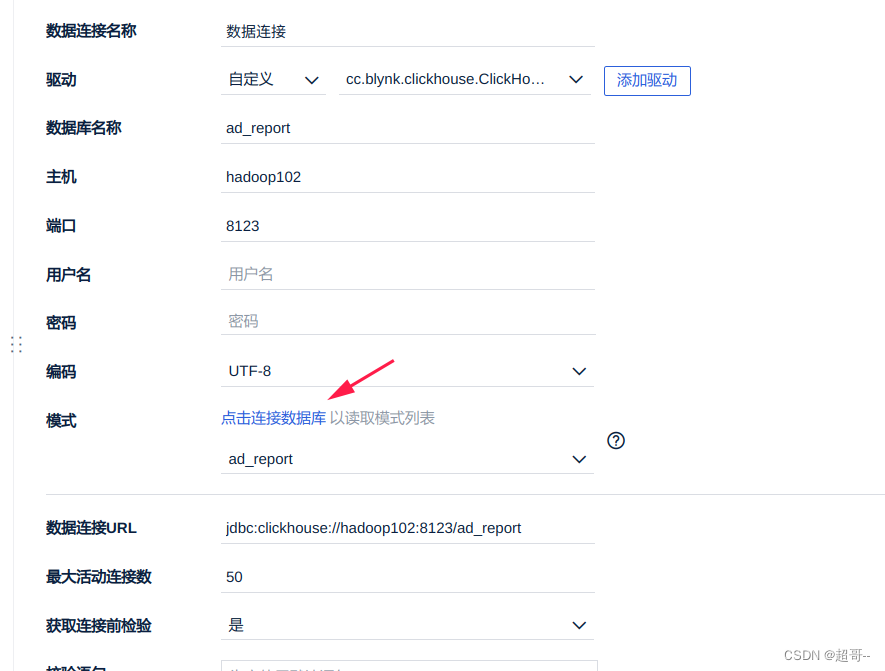
最后右上角保存
4.导入数据
新建文件夹
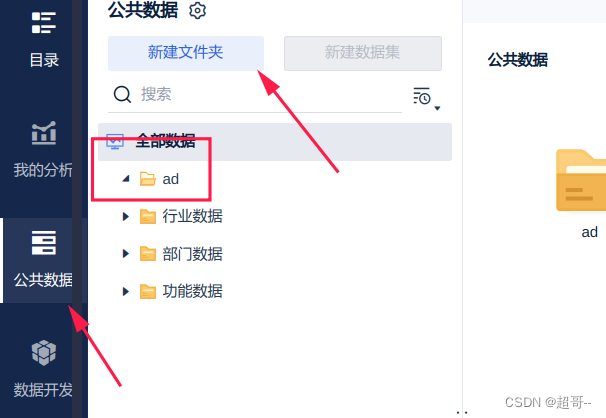
添加数据库表
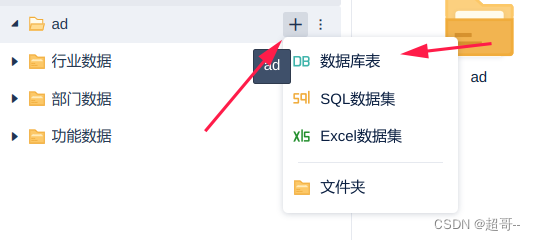
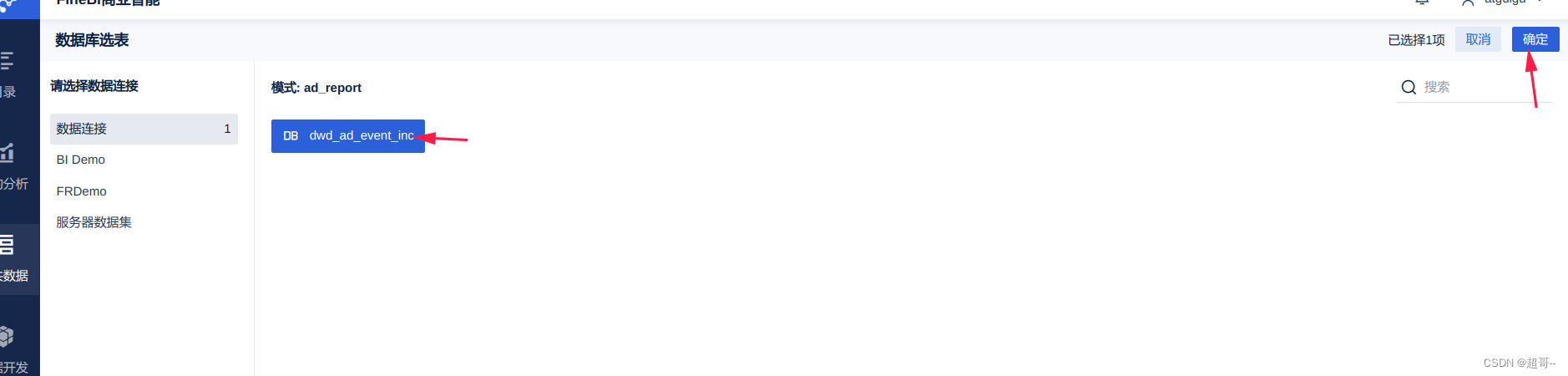
添加数据
更新数据
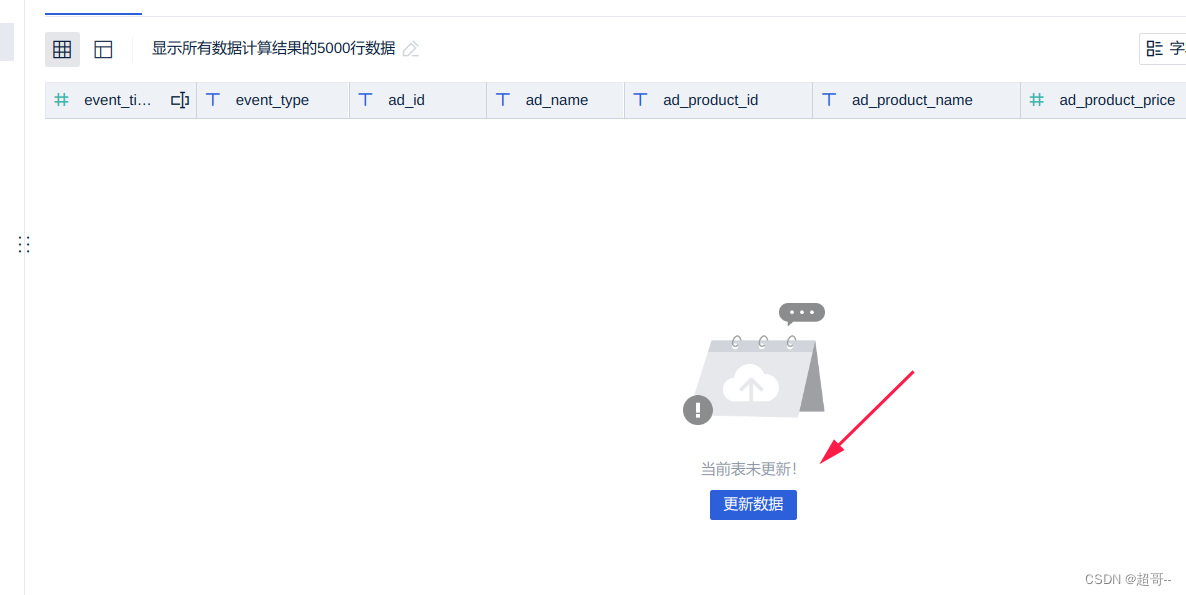
这里有可能出现中文乱码,如果出现了就把数据库连接从utf8换成默认。
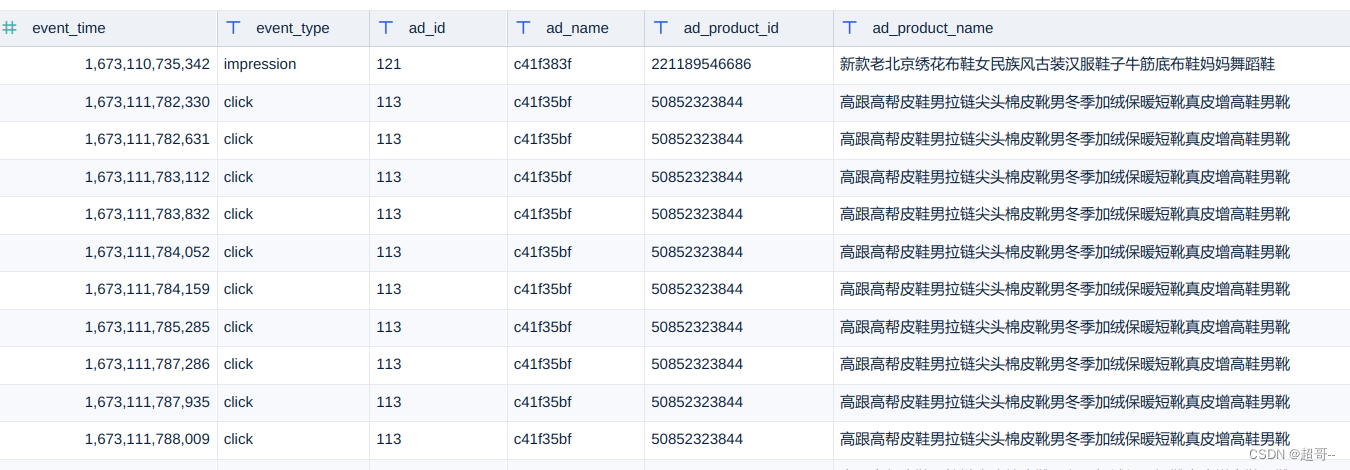
5.编辑图表
添加数据

添加组件
创建钻取目录
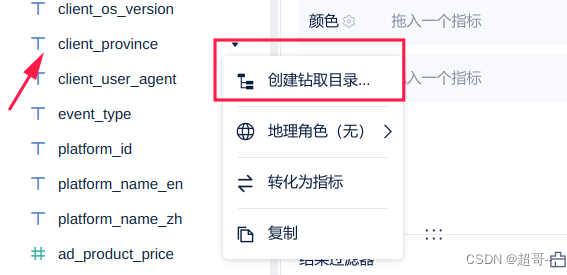
为了方便重命名一下
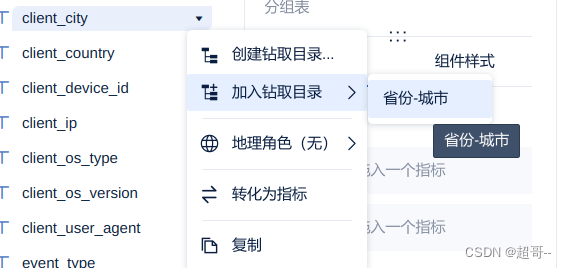
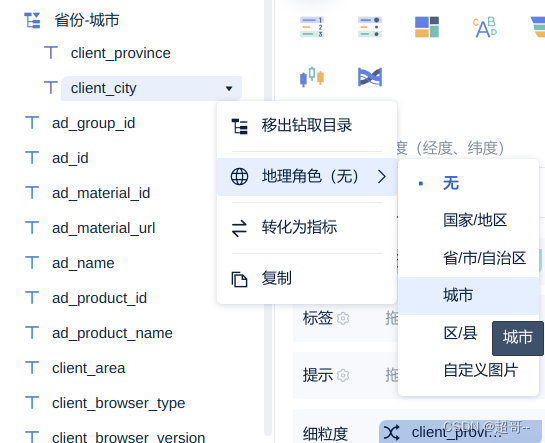
将city加入钻取目录
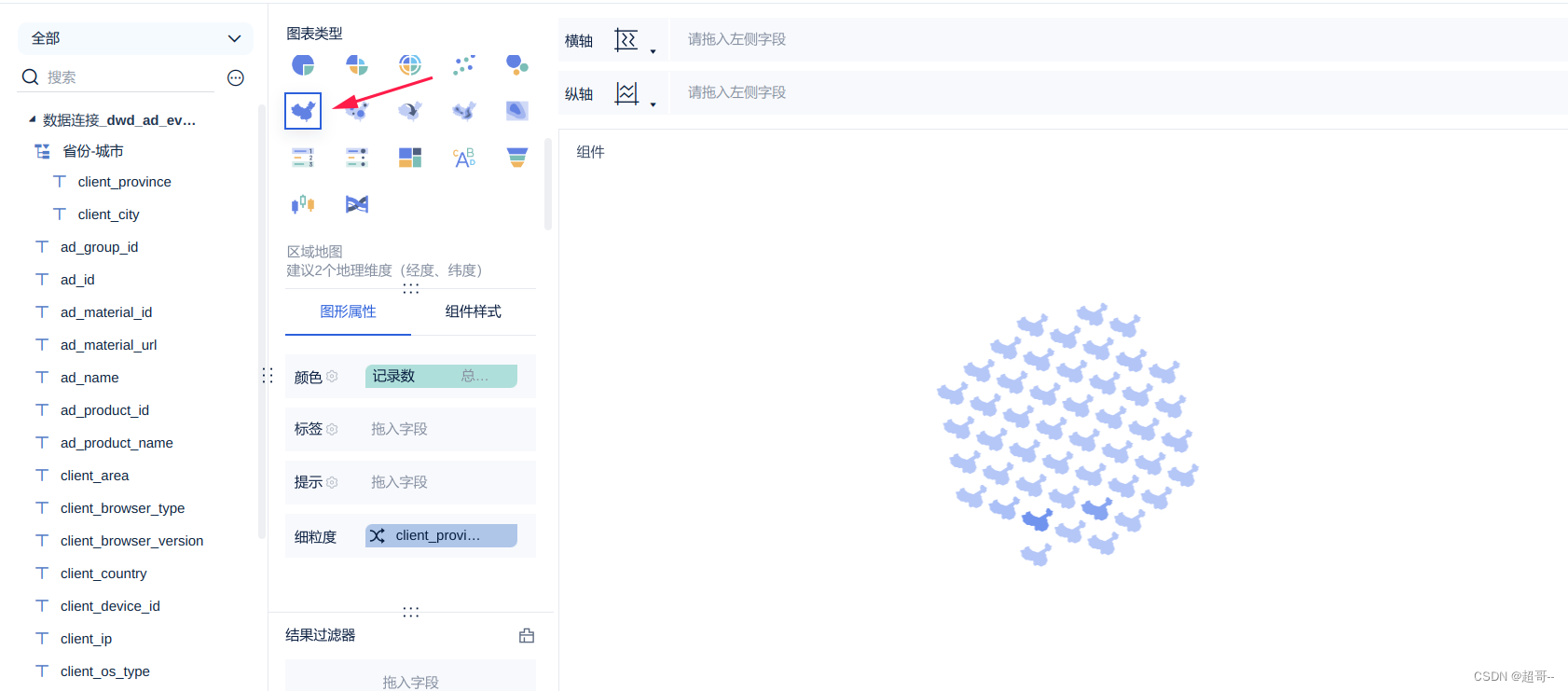
选择图表类型
设置映射类型
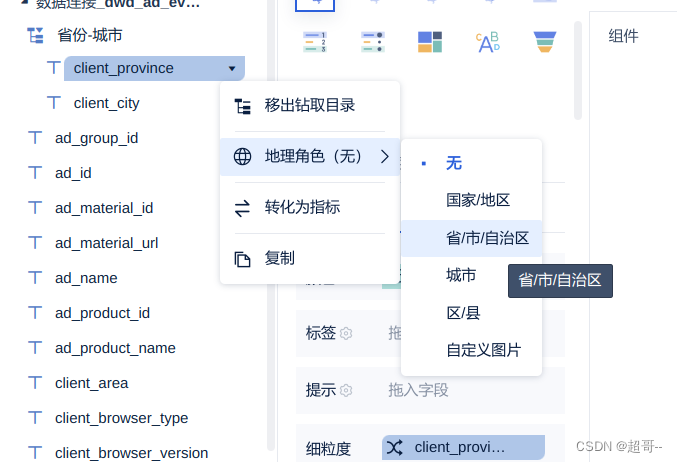

另一个也一样

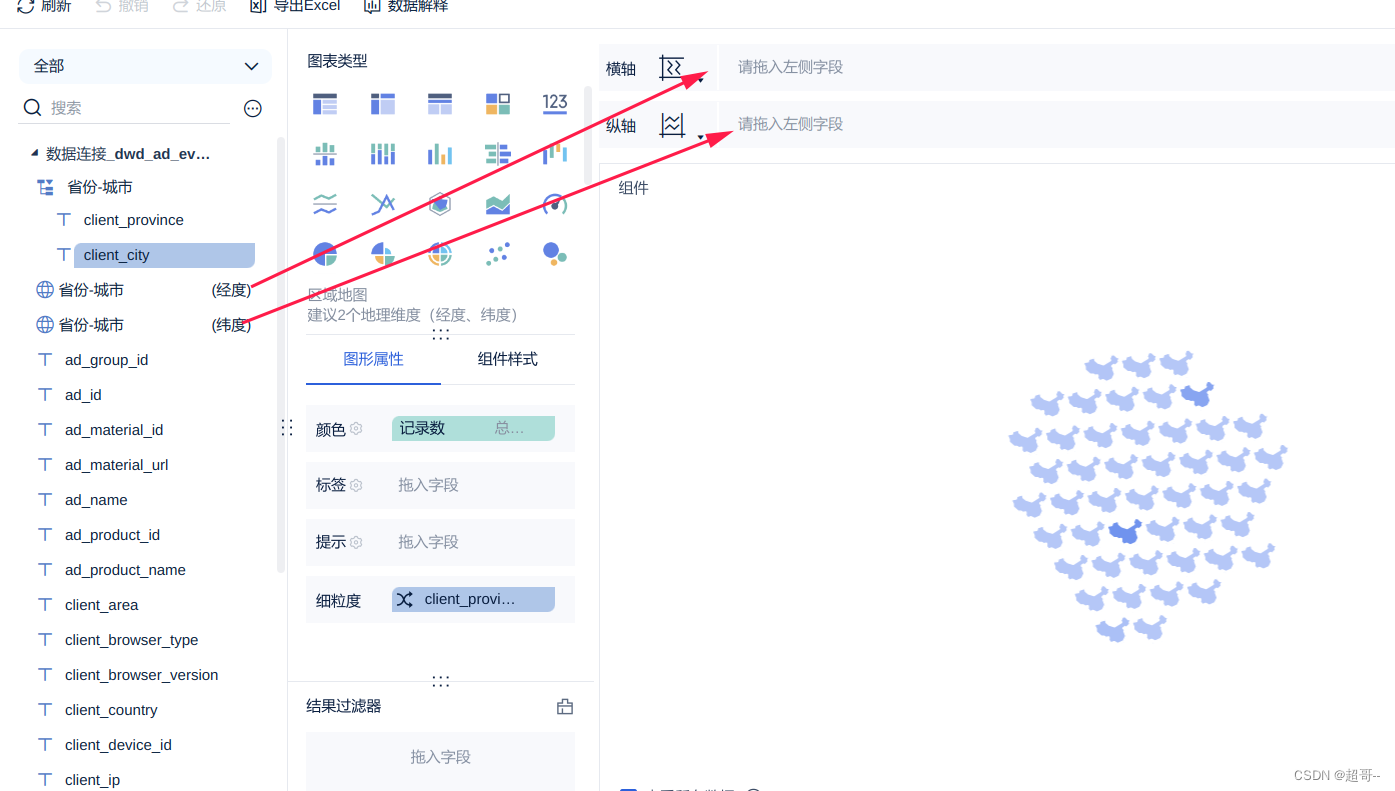

最后重命名一下组件。
考虑到内存问题(博主这里网站已经很卡了)。
就只演示这一个例子。
6.仪表盘操作
添加仪表盘
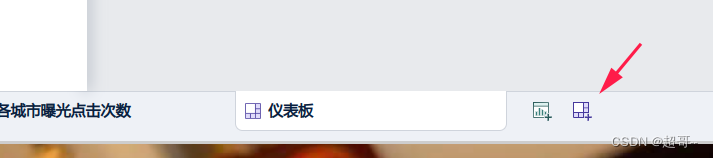
直接拖拽即可。

可以调整大小和一些其他参数

之后退出主题,打开公共链接
然后复制链接到浏览器打开即可。

总结
到此广告数仓的项目就正式完结了。


















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









