






- 文为「365天深度学习训练营」内部文章
- 参考本文所写文章,请在文章开头带上「🔗 声明」
1.设置GPU
from tensorflow import keras
from tensorflow.keras import layers,models
import os, PIL, pathlib
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
gpus2.导入数据
data_dir = "E:/T3/48-data"
data_dir = pathlib.Path(data_dir)image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:",image_count)图片总数为: 1800
roses = list(data_dir.glob('Jennifer Lawrence/*.jpg'))
PIL.Image.open(str(roses[0]))
batch_size = 32
img_height = 224
img_width = 224 """
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.1,
subset="training",
label_mode = "categorical",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1800 files belonging to 17 classes. Using 1620 files for training.
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.1,
subset="validation",
label_mode = "categorical",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)Found 1800 files belonging to 17 classes. Using 180 files for validation.
class_names = train_ds.class_names
print(class_names)['Angelina Jolie', 'Brad Pitt', 'Denzel Washington', 'Hugh Jackman', 'Jennifer Lawrence', 'Johnny Depp', 'Kate Winslet', 'Leonardo DiCaprio', 'Megan Fox', 'Natalie Portman', 'Nicole Kidman', 'Robert Downey Jr', 'Sandra Bullock', 'Scarlett Johansson', 'Tom Cruise', 'Tom Hanks', 'Will Smith']
plt.figure(figsize=(20, 10))
for images, labels in train_ds.take(1):
for i in range(20):
ax = plt.subplot(5, 10, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[np.argmax(labels[i])])
plt.axis("off")
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break(32, 224, 224, 3) (32, 17)
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)"""
关于卷积核的计算不懂的可以参考文章:https://blog.youkuaiyun.com/qq_38251616/article/details/114278995
layers.Dropout(0.4) 作用是防止过拟合,提高模型的泛化能力。
关于Dropout层的更多介绍可以参考文章:https://mtyjkh.blog.youkuaiyun.com/article/details/115826689
"""
model = models.Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)), # 卷积层1,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层1,2*2采样
layers.Conv2D(32, (3, 3), activation='relu'), # 卷积层2,卷积核3*3
layers.AveragePooling2D((2, 2)), # 池化层2,2*2采样
layers.Dropout(0.5),
layers.Conv2D(64, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.AveragePooling2D((2, 2)),
layers.Dropout(0.5),
layers.Conv2D(128, (3, 3), activation='relu'), # 卷积层3,卷积核3*3
layers.Dropout(0.5),
layers.Flatten(), # Flatten层,连接卷积层与全连接层
layers.Dense(128, activation='relu'), # 全连接层,特征进一步提取
layers.Dense(len(class_names)) # 输出层,输出预期结果
])
model.summary() # 打印网络结构WARNING:tensorflow:From D:\dl\envs\pytorch_gpu\lib\site-packages\keras\src\backend.py:873: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling (Rescaling) (None, 224, 224, 3) 0
conv2d (Conv2D) (None, 222, 222, 16) 448
average_pooling2d (Average (None, 111, 111, 16) 0
Pooling2D)
conv2d_1 (Conv2D) (None, 109, 109, 32) 4640
average_pooling2d_1 (Avera (None, 54, 54, 32) 0
gePooling2D)
dropout (Dropout) (None, 54, 54, 32) 0
conv2d_2 (Conv2D) (None, 52, 52, 64) 18496
average_pooling2d_2 (Avera (None, 26, 26, 64) 0
gePooling2D)
dropout_1 (Dropout) (None, 26, 26, 64) 0
conv2d_3 (Conv2D) (None, 24, 24, 128) 73856
dropout_2 (Dropout) (None, 24, 24, 128) 0
flatten (Flatten) (None, 73728) 0
dense (Dense) (None, 128) 9437312
dense_1 (Dense) (None, 17) 2193
=================================================================
Total params: 9536945 (36.38 MB)
Trainable params: 9536945 (36.38 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=60, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.96, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer,
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping
epochs = 100
# 保存最佳模型参数
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True)
# 设置早停
earlystopper = EarlyStopping(monitor='val_accuracy',
min_delta=0.001,
patience=20,
verbose=1)
history = model.fit(train_ds,
validation_data=val_ds,
epochs=epochs,
callbacks=[checkpointer, earlystopper])Epoch 1/100 51/51 [==============================] - ETA: 0s - loss: 2.8020 - accuracy: 0.1068 Epoch 1: val_accuracy improved from -inf to 0.13889, saving model to best_model.h5 51/51 [==============================] - 6s 101ms/step - loss: 2.8020 - accuracy: 0.1068 - val_loss: 2.7654 - val_accuracy: 0.1389 Epoch 2/100 51/51 [==============================] - ETA: 0s - loss: 2.6995 - accuracy: 0.1426 Epoch 2: val_accuracy improved from 0.13889 to 0.17778, saving model to best_model.h5 51/51 [==============================] - 5s 93ms/step - loss: 2.6995 - accuracy: 0.1426 - val_loss: 2.6468 - val_accuracy: 0.1778 Epoch 3/100 51/51 [==============================] - ETA: 0s - loss: 2.5822 - accuracy: 0.1704 Epoch 3: val_accuracy improved from 0.17778 to 0.18889, saving model to best_model.h5 51/51 [==============================] - 5s 92ms/step - loss: 2.5822 - accuracy: 0.1704 - val_loss: 2.5724 - val_accuracy: 0.1889 Epoch 4/100 51/51 [==============================] - ETA: 0s - loss: 2.4968 - accuracy: 0.2080 Epoch 4: val_accuracy did not improve from 0.18889 51/51 [==============================] - 5s 93ms/step - loss: 2.4968 - accuracy: 0.2080 - val_loss: 2.5844 - val_accuracy: 0.1833 Epoch 5/100 51/51 [==============================] - ETA: 0s - loss: 2.4022 - accuracy: 0.2296 Epoch 5: val_accuracy did not improve from 0.18889 51/51 [==============================] - 5s 91ms/step - loss: 2.4022 - accuracy: 0.2296 - val_loss: 2.5602 - val_accuracy: 0.1833 Epoch 6/100 51/51 [==============================] - ETA: 0s - loss: 2.3639 - accuracy: 0.2222 Epoch 6: val_accuracy did not improve from 0.18889 51/51 [==============================] - 5s 92ms/step - loss: 2.3639 - accuracy: 0.2222 - val_loss: 2.4889 - val_accuracy: 0.1722 Epoch 7/100 51/51 [==============================] - ETA: 0s - loss: 2.2985 - accuracy: 0.2543 Epoch 7: val_accuracy improved from 0.18889 to 0.22778, saving model to best_model.h5 51/51 [==============================] - 5s 95ms/step - loss: 2.2985 - accuracy: 0.2543 - val_loss: 2.4399 - val_accuracy: 0.2278 Epoch 8/100 51/51 [==============================] - ETA: 0s - loss: 2.2159 - accuracy: 0.2858 Epoch 8: val_accuracy did not improve from 0.22778 51/51 [==============================] - 5s 92ms/step - loss: 2.2159 - accuracy: 0.2858 - val_loss: 2.5525 - val_accuracy: 0.1889 Epoch 9/100 51/51 [==============================] - ETA: 0s - loss: 2.1468 - accuracy: 0.3154 Epoch 9: val_accuracy did not improve from 0.22778 51/51 [==============================] - 5s 93ms/step - loss: 2.1468 - accuracy: 0.3154 - val_loss: 2.4422 - val_accuracy: 0.2222 Epoch 10/100 51/51 [==============================] - ETA: 0s - loss: 2.0766 - accuracy: 0.3278 Epoch 10: val_accuracy did not improve from 0.22778 51/51 [==============================] - 5s 104ms/step - loss: 2.0766 - accuracy: 0.3278 - val_loss: 2.3985 - val_accuracy: 0.2111 Epoch 11/100 51/51 [==============================] - ETA: 0s - loss: 1.9994 - accuracy: 0.3506 Epoch 11: val_accuracy did not improve from 0.22778 51/51 [==============================] - 5s 104ms/step - loss: 1.9994 - accuracy: 0.3506 - val_loss: 2.4852 - val_accuracy: 0.1833 Epoch 12/100 51/51 [==============================] - ETA: 0s - loss: 1.9674 - accuracy: 0.3710 Epoch 12: val_accuracy did not improve from 0.22778 51/51 [==============================] - 5s 104ms/step - loss: 1.9674 - accuracy: 0.3710 - val_loss: 2.4769 - val_accuracy: 0.2222 Epoch 13/100 51/51 [==============================] - ETA: 0s - loss: 1.8588 - accuracy: 0.3975 Epoch 13: val_accuracy did not improve from 0.22778 51/51 [==============================] - 5s 102ms/step - loss: 1.8588 - accuracy: 0.3975 - val_loss: 2.4093 - val_accuracy: 0.2222 Epoch 14/100 51/51 [==============================] - ETA: 0s - loss: 1.8185 - accuracy: 0.4117 Epoch 14: val_accuracy improved from 0.22778 to 0.24444, saving model to best_model.h5 51/51 [==============================] - 5s 101ms/step - loss: 1.8185 - accuracy: 0.4117 - val_loss: 2.3769 - val_accuracy: 0.2444 Epoch 15/100 51/51 [==============================] - ETA: 0s - loss: 1.7363 - accuracy: 0.4574 Epoch 15: val_accuracy did not improve from 0.24444 51/51 [==============================] - 5s 101ms/step - loss: 1.7363 - accuracy: 0.4574 - val_loss: 2.3971 - val_accuracy: 0.2333 Epoch 16/100 51/51 [==============================] - ETA: 0s - loss: 1.6782 - accuracy: 0.4654 Epoch 16: val_accuracy did not improve from 0.24444 51/51 [==============================] - 5s 102ms/step - loss: 1.6782 - accuracy: 0.4654 - val_loss: 2.4277 - val_accuracy: 0.2444 Epoch 17/100 51/51 [==============================] - ETA: 0s - loss: 1.5884 - accuracy: 0.4895 Epoch 17: val_accuracy improved from 0.24444 to 0.26111, saving model to best_model.h5 51/51 [==============================] - 5s 103ms/step - loss: 1.5884 - accuracy: 0.4895 - val_loss: 2.4789 - val_accuracy: 0.2611 Epoch 18/100 51/51 [==============================] - ETA: 0s - loss: 1.5270 - accuracy: 0.5123 Epoch 18: val_accuracy did not improve from 0.26111 51/51 [==============================] - 5s 99ms/step - loss: 1.5270 - accuracy: 0.5123 - val_loss: 2.3671 - val_accuracy: 0.2444 Epoch 19/100 51/51 [==============================] - ETA: 0s - loss: 1.4880 - accuracy: 0.5259 Epoch 19: val_accuracy did not improve from 0.26111 51/51 [==============================] - 5s 99ms/step - loss: 1.4880 - accuracy: 0.5259 - val_loss: 2.4830 - val_accuracy: 0.2389 Epoch 20/100 51/51 [==============================] - ETA: 0s - loss: 1.4282 - accuracy: 0.5389 Epoch 20: val_accuracy did not improve from 0.26111 51/51 [==============================] - 5s 99ms/step - loss: 1.4282 - accuracy: 0.5389 - val_loss: 2.4671 - val_accuracy: 0.2167 Epoch 21/100 51/51 [==============================] - ETA: 0s - loss: 1.3409 - accuracy: 0.5667 Epoch 21: val_accuracy did not improve from 0.26111 51/51 [==============================] - 5s 102ms/step - loss: 1.3409 - accuracy: 0.5667 - val_loss: 2.4547 - val_accuracy: 0.2222 Epoch 22/100 51/51 [==============================] - ETA: 0s - loss: 1.3315 - accuracy: 0.5710 Epoch 22: val_accuracy did not improve from 0.26111 51/51 [==============================] - 5s 100ms/step - loss: 1.3315 - accuracy: 0.5710 - val_loss: 2.5604 - val_accuracy: 0.2444 Epoch 23/100 51/51 [==============================] - ETA: 0s - loss: 1.2629 - accuracy: 0.5951 Epoch 23: val_accuracy did not improve from 0.26111 51/51 [==============================] - 5s 99ms/step - loss: 1.2629 - accuracy: 0.5951 - val_loss: 2.4737 - val_accuracy: 0.2278 Epoch 24/100 51/51 [==============================] - ETA: 0s - loss: 1.2116 - accuracy: 0.6148 Epoch 24: val_accuracy improved from 0.26111 to 0.27778, saving model to best_model.h5 51/51 [==============================] - 5s 100ms/step - loss: 1.2116 - accuracy: 0.6148 - val_loss: 2.4719 - val_accuracy: 0.2778 Epoch 25/100 51/51 [==============================] - ETA: 0s - loss: 1.1305 - accuracy: 0.6451 Epoch 25: val_accuracy did not improve from 0.27778 51/51 [==============================] - 5s 99ms/step - loss: 1.1305 - accuracy: 0.6451 - val_loss: 2.4864 - val_accuracy: 0.2611 Epoch 26/100 51/51 [==============================] - ETA: 0s - loss: 1.0830 - accuracy: 0.6586 Epoch 26: val_accuracy did not improve from 0.27778 51/51 [==============================] - 5s 101ms/step - loss: 1.0830 - accuracy: 0.6586 - val_loss: 2.4766 - val_accuracy: 0.2556 Epoch 27/100 51/51 [==============================] - ETA: 0s - loss: 1.0328 - accuracy: 0.6704 Epoch 27: val_accuracy did not improve from 0.27778 51/51 [==============================] - 5s 101ms/step - loss: 1.0328 - accuracy: 0.6704 - val_loss: 2.6766 - val_accuracy: 0.2722 Epoch 28/100 51/51 [==============================] - ETA: 0s - loss: 0.9848 - accuracy: 0.6827 Epoch 28: val_accuracy did not improve from 0.27778 51/51 [==============================] - 5s 100ms/step - loss: 0.9848 - accuracy: 0.6827 - val_loss: 2.5959 - val_accuracy: 0.2778 Epoch 29/100 51/51 [==============================] - ETA: 0s - loss: 0.9363 - accuracy: 0.7086 Epoch 29: val_accuracy did not improve from 0.27778 51/51 [==============================] - 5s 99ms/step - loss: 0.9363 - accuracy: 0.7086 - val_loss: 2.6760 - val_accuracy: 0.2444 Epoch 30/100 51/51 [==============================] - ETA: 0s - loss: 0.9077 - accuracy: 0.7173 Epoch 30: val_accuracy did not improve from 0.27778 51/51 [==============================] - 5s 99ms/step - loss: 0.9077 - accuracy: 0.7173 - val_loss: 2.5857 - val_accuracy: 0.2667 Epoch 31/100 51/51 [==============================] - ETA: 0s - loss: 0.8526 - accuracy: 0.7352 Epoch 31: val_accuracy improved from 0.27778 to 0.28333, saving model to best_model.h5 51/51 [==============================] - 5s 103ms/step - loss: 0.8526 - accuracy: 0.7352 - val_loss: 2.6705 - val_accuracy: 0.2833 Epoch 32/100 51/51 [==============================] - ETA: 0s - loss: 0.8245 - accuracy: 0.7463 Epoch 32: val_accuracy did not improve from 0.28333 51/51 [==============================] - 5s 101ms/step - loss: 0.8245 - accuracy: 0.7463 - val_loss: 2.7332 - val_accuracy: 0.2667 Epoch 33/100 51/51 [==============================] - ETA: 0s - loss: 0.7920 - accuracy: 0.7562 Epoch 33: val_accuracy did not improve from 0.28333 51/51 [==============================] - 5s 99ms/step - loss: 0.7920 - accuracy: 0.7562 - val_loss: 2.7227 - val_accuracy: 0.2778 Epoch 34/100 51/51 [==============================] - ETA: 0s - loss: 0.7372 - accuracy: 0.7716 Epoch 34: val_accuracy did not improve from 0.28333 51/51 [==============================] - 5s 99ms/step - loss: 0.7372 - accuracy: 0.7716 - val_loss: 2.7903 - val_accuracy: 0.2667 Epoch 35/100 51/51 [==============================] - ETA: 0s - loss: 0.7194 - accuracy: 0.7698 Epoch 35: val_accuracy did not improve from 0.28333 51/51 [==============================] - 5s 99ms/step - loss: 0.7194 - accuracy: 0.7698 - val_loss: 2.7432 - val_accuracy: 0.2833 Epoch 36/100 51/51 [==============================] - ETA: 0s - loss: 0.6930 - accuracy: 0.7772 Epoch 36: val_accuracy did not improve from 0.28333 51/51 [==============================] - 5s 101ms/step - loss: 0.6930 - accuracy: 0.7772 - val_loss: 2.8837 - val_accuracy: 0.2500 Epoch 37/100 51/51 [==============================] - ETA: 0s - loss: 0.6566 - accuracy: 0.7938 Epoch 37: val_accuracy did not improve from 0.28333 51/51 [==============================] - 5s 100ms/step - loss: 0.6566 - accuracy: 0.7938 - val_loss: 2.8333 - val_accuracy: 0.2833 Epoch 38/100 51/51 [==============================] - ETA: 0s - loss: 0.6490 - accuracy: 0.8012 Epoch 38: val_accuracy did not improve from 0.28333 51/51 [==============================] - 5s 99ms/step - loss: 0.6490 - accuracy: 0.8012 - val_loss: 2.8464 - val_accuracy: 0.2778 Epoch 39/100 51/51 [==============================] - ETA: 0s - loss: 0.6268 - accuracy: 0.8130 Epoch 39: val_accuracy did not improve from 0.28333 51/51 [==============================] - 5s 100ms/step - loss: 0.6268 - accuracy: 0.8130 - val_loss: 2.8161 - val_accuracy: 0.2833 Epoch 40/100 51/51 [==============================] - ETA: 0s - loss: 0.5827 - accuracy: 0.8111 Epoch 40: val_accuracy improved from 0.28333 to 0.29444, saving model to best_model.h5 51/51 [==============================] - 5s 102ms/step - loss: 0.5827 - accuracy: 0.8111 - val_loss: 2.8172 - val_accuracy: 0.2944 Epoch 41/100 51/51 [==============================] - ETA: 0s - loss: 0.5758 - accuracy: 0.8210 Epoch 41: val_accuracy improved from 0.29444 to 0.31667, saving model to best_model.h5 51/51 [==============================] - 5s 103ms/step - loss: 0.5758 - accuracy: 0.8210 - val_loss: 2.8566 - val_accuracy: 0.3167 Epoch 42/100 51/51 [==============================] - ETA: 0s - loss: 0.5230 - accuracy: 0.8469 Epoch 42: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 102ms/step - loss: 0.5230 - accuracy: 0.8469 - val_loss: 2.9240 - val_accuracy: 0.3000 Epoch 43/100 51/51 [==============================] - ETA: 0s - loss: 0.4961 - accuracy: 0.8494 Epoch 43: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 100ms/step - loss: 0.4961 - accuracy: 0.8494 - val_loss: 2.9399 - val_accuracy: 0.3000 Epoch 44/100 51/51 [==============================] - ETA: 0s - loss: 0.5207 - accuracy: 0.8420 Epoch 44: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 100ms/step - loss: 0.5207 - accuracy: 0.8420 - val_loss: 2.9821 - val_accuracy: 0.3056 Epoch 45/100 51/51 [==============================] - ETA: 0s - loss: 0.4713 - accuracy: 0.8537 Epoch 45: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 100ms/step - loss: 0.4713 - accuracy: 0.8537 - val_loss: 3.0480 - val_accuracy: 0.3000 Epoch 46/100 51/51 [==============================] - ETA: 0s - loss: 0.4518 - accuracy: 0.8630 Epoch 46: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 101ms/step - loss: 0.4518 - accuracy: 0.8630 - val_loss: 3.0340 - val_accuracy: 0.3056 Epoch 47/100 51/51 [==============================] - ETA: 0s - loss: 0.4353 - accuracy: 0.8759 Epoch 47: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 101ms/step - loss: 0.4353 - accuracy: 0.8759 - val_loss: 3.0947 - val_accuracy: 0.2889 Epoch 48/100 51/51 [==============================] - ETA: 0s - loss: 0.4439 - accuracy: 0.8512 Epoch 48: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 100ms/step - loss: 0.4439 - accuracy: 0.8512 - val_loss: 3.0633 - val_accuracy: 0.2944 Epoch 49/100 51/51 [==============================] - ETA: 0s - loss: 0.4208 - accuracy: 0.8722 Epoch 49: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 100ms/step - loss: 0.4208 - accuracy: 0.8722 - val_loss: 3.0615 - val_accuracy: 0.3000 Epoch 50/100 51/51 [==============================] - ETA: 0s - loss: 0.4005 - accuracy: 0.8864 Epoch 50: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 100ms/step - loss: 0.4005 - accuracy: 0.8864 - val_loss: 3.1585 - val_accuracy: 0.3000 Epoch 51/100 51/51 [==============================] - ETA: 0s - loss: 0.3905 - accuracy: 0.8802 Epoch 51: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 102ms/step - loss: 0.3905 - accuracy: 0.8802 - val_loss: 3.1790 - val_accuracy: 0.2722 Epoch 52/100 51/51 [==============================] - ETA: 0s - loss: 0.3927 - accuracy: 0.8809 Epoch 52: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 100ms/step - loss: 0.3927 - accuracy: 0.8809 - val_loss: 3.1203 - val_accuracy: 0.2944 Epoch 53/100 51/51 [==============================] - ETA: 0s - loss: 0.4025 - accuracy: 0.8722 Epoch 53: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 99ms/step - loss: 0.4025 - accuracy: 0.8722 - val_loss: 3.1396 - val_accuracy: 0.3111 Epoch 54/100 51/51 [==============================] - ETA: 0s - loss: 0.3757 - accuracy: 0.8852 Epoch 54: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 99ms/step - loss: 0.3757 - accuracy: 0.8852 - val_loss: 3.1843 - val_accuracy: 0.3000 Epoch 55/100 51/51 [==============================] - ETA: 0s - loss: 0.3513 - accuracy: 0.8944 Epoch 55: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 101ms/step - loss: 0.3513 - accuracy: 0.8944 - val_loss: 3.1917 - val_accuracy: 0.3111 Epoch 56/100 51/51 [==============================] - ETA: 0s - loss: 0.3424 - accuracy: 0.8907 Epoch 56: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 102ms/step - loss: 0.3424 - accuracy: 0.8907 - val_loss: 3.2322 - val_accuracy: 0.2889 Epoch 57/100 51/51 [==============================] - ETA: 0s - loss: 0.3271 - accuracy: 0.9019 Epoch 57: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 100ms/step - loss: 0.3271 - accuracy: 0.9019 - val_loss: 3.1764 - val_accuracy: 0.3000 Epoch 58/100 51/51 [==============================] - ETA: 0s - loss: 0.3199 - accuracy: 0.8963 Epoch 58: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 101ms/step - loss: 0.3199 - accuracy: 0.8963 - val_loss: 3.2644 - val_accuracy: 0.3111 Epoch 59/100 51/51 [==============================] - ETA: 0s - loss: 0.2990 - accuracy: 0.9117 Epoch 59: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 99ms/step - loss: 0.2990 - accuracy: 0.9117 - val_loss: 3.2755 - val_accuracy: 0.3000 Epoch 60/100 51/51 [==============================] - ETA: 0s - loss: 0.3111 - accuracy: 0.9093 Epoch 60: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 101ms/step - loss: 0.3111 - accuracy: 0.9093 - val_loss: 3.3149 - val_accuracy: 0.3111 Epoch 61/100 51/51 [==============================] - ETA: 0s - loss: 0.3015 - accuracy: 0.9025 Epoch 61: val_accuracy did not improve from 0.31667 51/51 [==============================] - 5s 102ms/step - loss: 0.3015 - accuracy: 0.9025 - val_loss: 3.3743 - val_accuracy: 0.3167 Epoch 61: early stopping
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(loss))
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()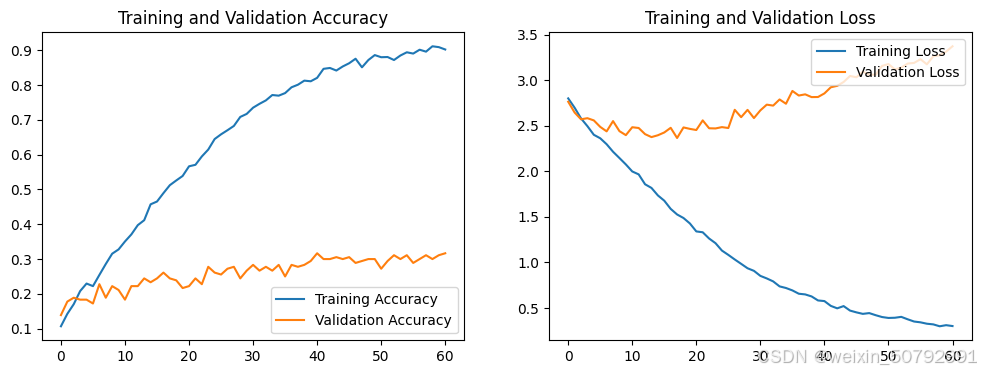
# 加载效果最好的模型权重
model.load_weights('best_model.h5')
from PIL import Image
import numpy as np
img = Image.open("E:/T3/48-data/Jennifer Lawrence/003_963a3627.jpg") #这里选择你需要预测的图片
image = tf.image.resize(img, [img_height, img_width])
img_array = tf.expand_dims(image, 0)
predictions = model.predict(img_array) # 这里选用你已经训练好的模型
print("预测结果为:",class_names[np.argmax(predictions)])1/1 [==============================] - 0s 66ms/step 预测结果为: Jennifer Lawrence
心得:调节期间多种方法 包括改变损失函数权重等方法 均无明显结果 考虑网络架构更换或数据增强 下一步会继续调整 优化学习率


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









