







 本文详细探讨了数据清洗的重要性,从数据质量的评价指标到数据清洗的定义、原理、基本流程和策略。强调了准确性、完整性、简洁性和适用性作为数据质量的核心,并分类了基于数据源和清洗方式的“脏”数据。介绍了数据清洗的常见方法,如处理缺失值、重复值和错误值,以及数据清洗流程的五个步骤。
本文详细探讨了数据清洗的重要性,从数据质量的评价指标到数据清洗的定义、原理、基本流程和策略。强调了准确性、完整性、简洁性和适用性作为数据质量的核心,并分类了基于数据源和清洗方式的“脏”数据。介绍了数据清洗的常见方法,如处理缺失值、重复值和错误值,以及数据清洗流程的五个步骤。
因为原始数据中存在着一些错误、重复的数据,直接使用的话会严重影响数据决策的准确性和效率,所以要对原始数据进行有效的清洗是大数据分析过程中的关键环节。
1.1.1数据质量的评价指标
包括数据的准确性、完整性、简洁性、适用性。 其中准确性、完整性、简洁性是为了保证数据的适用性
1.1.2数据质量的问题分类
一类是基于数据源的“脏”数据分类;另一类是基于清洗方式的“脏”数据分类。
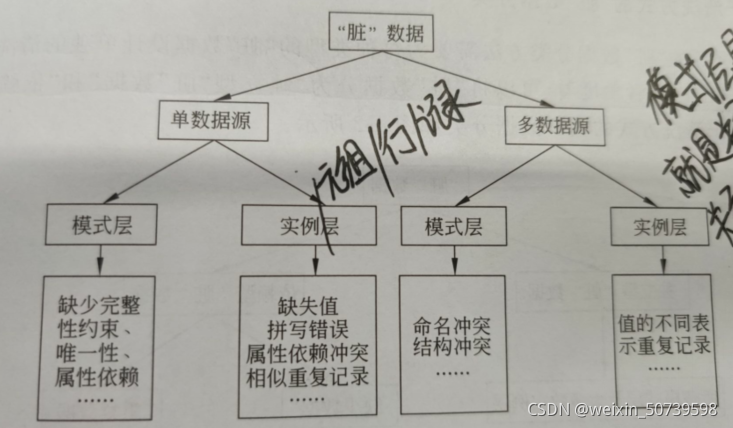
A.基于数据源的“脏”数据分类
数据又分为单数据源和多数据源,数据源又下分为模式层和实例层(元祖、行、记录),模式层是指数据库的结构,就是关系结构,实例层是指关系中具体存储的数据记录或元组。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 833
833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









