







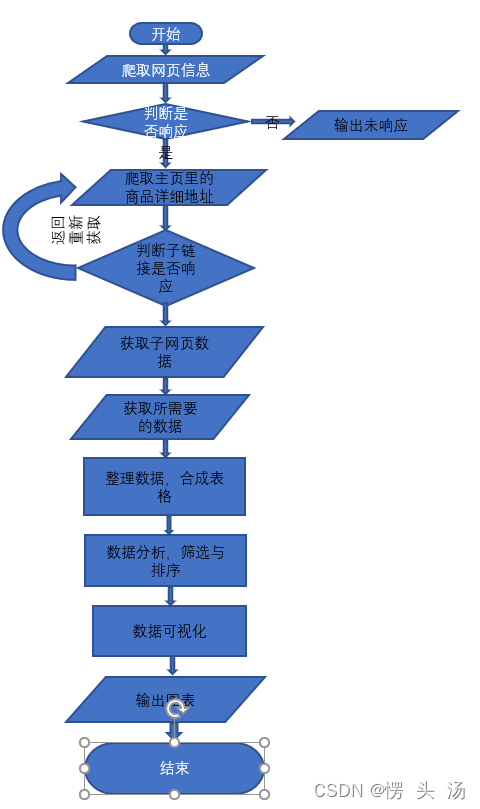
首先需要了解所需要爬取信息的网页、网址,判断是否动态,观察盒子是否有规律,观察翻页是否有规律
步骤:
首先需要爬取整一个搜索页面的源代码。之后会发现每一个商品都需要打开相应的地址才可以查看相应的详细信息。而这个地址往往就在
搜索页面中每一个商品的名称标签里。在确定好标签的相应位置之后,从里面提取出对应的链接。有些herf显示的不是一个完整的链接,那些通常是需要配合主网页的链接,然后合成一个完整的链接赋值给一个新的名称。之后使用爬虫爬取新地址的相应数据,在爬起之前,也是要定位所需要的数据是在哪个标签里面。就可以逐个地爬出自己想要的数据。有些盒子的数据是不一样的所占的数据字数也是不同的。所以应该根据自己想要的哪一个部分的数据来进行切片。这一切片完成之后就可以合成一个总的表。
直接上代码好吧:
##第一方案:
import requests
from bs4 import BeautifulSoup
import pandas
import re
import html
headers = {
'User-Agent': 'Mozilla / 5.0(WindowsNT10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 70.0.3538.25Safari / 537.36Core / 1.70.3756.400QQBrowser / 10.5.4043.400'
}
b = []
i=-1
for i in range(30):
url = 'https://search.suning.com/%E6%89%8B%E8%A1%A8/&iy=0&isNoResult=0&cp={}'.format(i+1)
p = -1
# 接收请求返回
respond = requests.get(url=url, headers=headers)
# 修复乱码
respond.encoding = 'utf-8'
# 处理z
a = BeautifulSoup(respond.text, 'lxml')
c = a.find_all('a',class_='sellPoint')
for n in c:
nike_ = {}
if n == None:
continue
url_01 = "https:{}".format(n['href'])
print(url_01)
respond_01 = requests.get(url=url_01, headers=headers)
c= BeautifulSoup(respond_01.text,'lxml')
key = url_01[38:-5]#切取所需要的字串
key_0 = url_01[27:37] #切取所需要的字串
url_02 = "http://pas.suning.com/nspcsale_0_000000" + key + "_000000" + key + "_" + key_0 + "_20_021_0210101_500353_1000267_9264_12113_Z001___R9006849_3.3_1___000278188__.html?callback=pcData&_=1558663936729"#从网上学到的获取苏宁商品价格的方法
web_data = requests.get(url=url_02, headers=headers)
res = html.unescape(web_data.text)
# print(res)
xh_data = requests.get(url=url_01, headers=headers)
xh = html.unescape(xh_data.text)
# prices = re.findall('"netPrice":"(.*?)","warrantyList":{}', res)
# xinghao = re.findall('>型号:(.*?)</li>', xh)
# print(xinghao)
prices = re.findall('"netPrice":"(.*?)","warrantyList"', res)#模糊匹配搜索
xinghao = re.findall('>型号:(.*?)</li>', xh)
key = re.findall('>可配对系统:(.*?)</li>', xh)
zhon = re.findall('>重量:(.*?)</li>', xh)
pingjia = re.findall('<p>"全部"<span>(.*?)</span>', xh)
p+=1
for price in prices:
try:
for k in c.find_all('ul',attrs={'class':'cnt clearfix'}):
n=k.text.replace('\n', '').replace('\r', '')
nike_[n[:4]] = k.find_all('a')[0].string.strip() #品牌
nike_['链接'] = url_01
nike_['价格'] = price
nike_['型号']=xinghao
nike_['配对系统'] = key
nike_['质量'] = zhon
nike_['评价'] = pingjia
nike_['销量'] = c.find_all('em', attrs={'id':'N07'})
#pj=c.find_all('a',attrs={'name':'item'})
except:
continue
b.append(nike_)
print(nike_)
nike_df = pandas.DataFrame(b)
nike_df.to_csv("苏宁xx性价比.csv", encoding='utf-8_sig')#生成csv
##我尝试的时候第一方案并没有成功
苏宁的网页是需要驱动器来采集的,当使用requests.get时往往是无法获取一些信息的,所以我们另找一条路吧,如果想了解怎么使用selenium爬虫的话可以点击(正在制作)。可以试试第二方案,其实都是给你们瞧瞧哪里不行而已,恍一枪。
#导入相关的库
import requests
from bs4 import BeautifulSoup
import pandas
import re
import html
import json
#进行一些隐藏
headers = {'User-Agent': 'Mozilla / 5.0(WindowsNT10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 70.0.3538.25Safari / 537.36Core / 1.70.3756.400QQBrowser / 10.5.4043.400'}
b = []
ii=33 #需要页数
#开始第一轮循环,得到相应的搜索页面的翻页内容
for i in range(ii):
url = 'https://www.klgwj.com/?m=search&a=index&k=手表&p={}'.format(i+1) #观察网页第一页与第二页或之后的页数之间的连接的变化,使用format函数填充
print(url)#试验
p = -1 #命名p(p为变量,每次进行一次大循环就被重新定义为-1)
respond = requests.get(url=url, headers=headers) #设定respond
respond.encoding = 'utf-8' #编码模式
a = BeautifulSoup(respond.text, 'lxml') #整合进行测试响应
r = a.find_all('a',attrs={'class':'pic-img'}) #将主页面的网页内容放如r中
# print(a) #测试
#进行第二循环
for n in r :
nike_ = {} #添加一个空表
if n == None: #条件进行
continue
url_01 = "https://www.klgwj.com{}".format(n['href']) #索取商品的连接
print(url_01) #测试
m=n['href'][16:-5] #索引商品编号
print(m) #测试
# # key=url_01[38:-5]
# # key_0=url_01[27:37]
# # url_02="http://pas.suning.com/nspcsale_0_000000"+key+"_000000" +key+ "_"+key_0+"_20_021_0210101_500353_1000267_9264_12113_Z001___R9006849_3.3_1___000278188__.html?callback=pcData&_=1558663936729"
respond_01 = requests.get(url=url_01, headers=headers) #测试子页面respond_01 响应
c= BeautifulSoup(respond_01.text,'lxml')
# print(c)
# web_data = requests.get(url=url_02, headers=headers)
#
# res = html.unescape(web_data.text)
# # print(res)
#
# prices = re.findall('"netPrice":"(.*?)","warrantyList":{}', res)
# for price in prices:
# print(price+'rmb')
p+=1 #循环增加(第二层)
try: #try来尝试索引,索引有误会跳过
# t=c.find_all('div',class_='keyword fl')
# print(t)a
nike_['名称'] = a.find_all('a',attrs={'href':'/item/index/iid/{}.html'.format(m)})[1].text ##主页索取,标签内容加m变量定位
# for k in c.find_all('div', class_="keyword fl"):
# cont = k.find_all('span')
print(p)
lll = c.find_all('em', class_='price')[1].text
nike_['原价'] = lll[0:-1]
nike_['优惠券'] = c.find_all('span', attrs={'class': 'num'})[0].text
nike_['价格'] = c.find_all('em', class_='price')[0].text
kkk = a.find_all('span', attrs={'class': 'sold'})[p].text #主页索取,引入变量p来定位
nike_['销量'] = kkk[0:-4] #切片去除‘已购买’
nike_['折扣'] = c.find_all('span', attrs={'style': 'color:red'})[0].text
nike_['链接'] = url_01
nike_['简介'] = c.find_all('div', attrs={'style': 'padding: 20px 60px;margin-top:10px;background: #fff;'})[0].text
except:
continue
b.append(nike_)
print(nike_) #测试
nike_df = pandas.DataFrame(b)
nike_df.to_csv("快乐街手表性价比.csv", encoding='utf-8_sig') #生csv
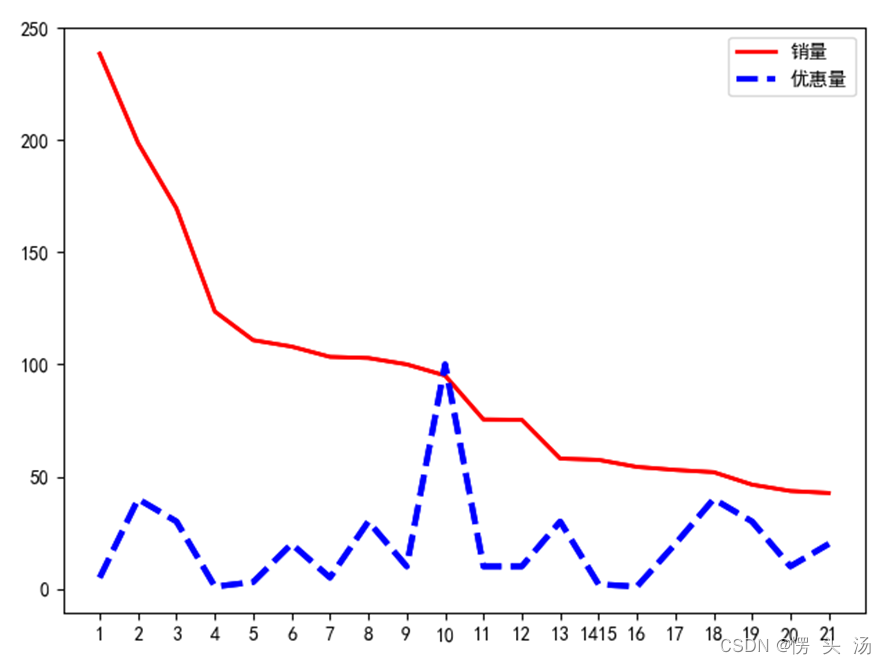
可视化:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
df=pd.read_csv('快乐街手表性价比.csv') #读取
df = df.loc[:,['名称','优惠券','原价','价格','销量']] #筛选列
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 设置显示符号
df = df.sort_values(by='销量', ascending=False) #排序
df=df[0:20] #取前20
you = df['销量']
yuan = df['优惠券']
plt.figure()
x_data =['1','2','3','4','5','6','7','8','9','10','11','12','13','14''15','16','17','18','19','20','21']
y_data = you/200 #为表现更清晰,将数据化小,使得两个数据在同一个范围
y_data2 = yuan
plt.plot(x_data,y_data,color='red',linewidth=2.0,linestyle='-')
plt.plot(x_data,y_data2,color='blue',linewidth=3.0,linestyle='--')
ln1,=plt.plot(x_data,y_data,color='red',linewidth=2.0,linestyle='-')
ln2,=plt.plot(x_data,y_data2,color='blue',linewidth=3.0,linestyle='--')
plt.legend(handles=[ln1,ln2],labels=['销量','优惠量'])
plt.show()



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











