







本人非专业背景,代码来源于GitHub:https://github.com/zhanghuanyuan/r-vine-copula-with-sliding-window.git,非本人原创,仅用于学习记录。不当之处欢迎指正。
使用软件:R V4.3.3版本
功能概述
R-vine Copula 本质上是一种多元 Copula 模型,它是将多个二元 Copula 组合起来构建高维的依赖结构,以此来描述多个变量之间的相关关系。
- 核心目标:结合滚动窗口技术构建高维动态 R-Vine Copula 模型来分析各变量间的动态相依结构。
- 方法:边缘分布使用 AR (1)-GARCH (1,1) (学生 t 分布作为标准化残差的分布假设) 或 AR (1)-GJR (1,1) -Guass 构造,用 R-vine Copula 建模变量间的非线性依赖结构,滚动窗口分析动态变化。
自定义函数 2 :summarise 函数
此函数用于生成数据集的描述性统计表,包含描述性统计量(均值、最大值、最小值、标准差、偏度、峰度)及三类统计检验结果( KS 正态性检验、ADF 单位根检验、ARCH-LM 自回归条件异方差检验)。如下表所示(未考虑 Q (1)):
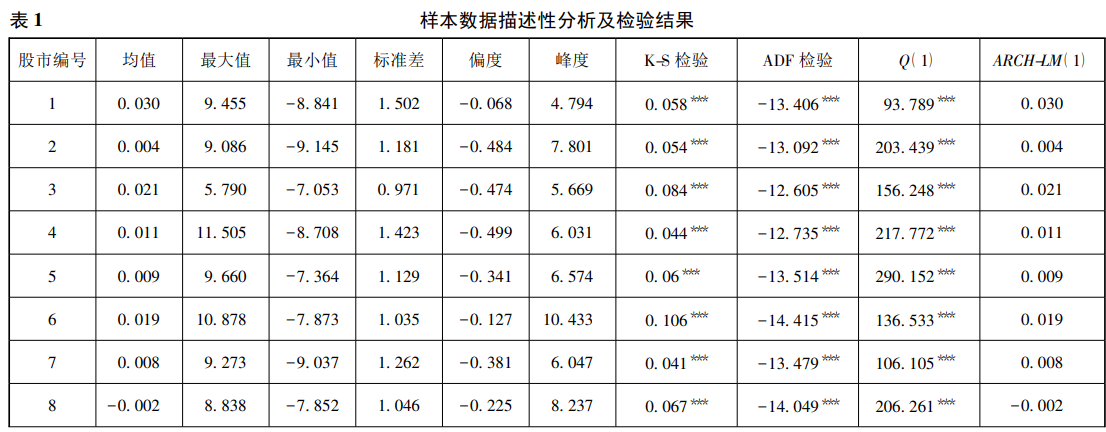
注: ***、**、* 分别表示在 1%、5%、10%的置信水平上显著; Q(1) 是序列自相关滞后 1 阶的统计量; ARCH-LM 是 ARCH 效应的检验统计量; ADF 检验是单位根检验的统计量。
详细信息如下:
1、辅助函数 panduan
根据 p 值为统计检验结果添加显著性标记
p ≤ 0.01→***(在 1% 的置信水平上显著)0.01 < p ≤ 0.05→**(在 5% 的置信水平上显著)0.05 < p ≤ 0.1→*(在 10% 的置信水平上显著)p > 0.1→ 无标记
# "***","**","*"分别表示在 1%、5%、10%的置信水平上显著
panduan<-function(x){
if(x<=0.01){
a="***"
}else if(x<=0.05){
a="**"
}else if(x<=0.1){
a="*"
}else{
a=""
}
return(a)
}
# 使用方法
panduan(ks_result_test[["p.value"]])
panduan(adf_result_test[["p.value"]])
panduan(archlm[["p.value"]])
# ...
2、辅助函数 market_simp_name
通过数字索引映射变量名(如 1→"SH", 2→"US")。
market_simp_name<-function(x){
name<-switch(x,
"SH",
"US",
"FR",
"UK",
"HK",
"JP",
"CH",
"SG",
"TW")
}
3、Summarise 函数
(1)利用 summary 函数计算均值、最大值、最小值。函数输出:
#mean,max,min
a<-as.numeric(summary(data_1))
summ[i,2]<-a[4] #mean
summ[i,3]<-a[6] #max
summ[i,4]<-a[1] #min
(2)计算标准差、偏度、峰度:
summ[i,5]<-sd(data_1) #sd
summ[i,6]<-skewness(data_1) #skewness
summ[i,7]<-kurtosis(data_1) #kurtosis
(3)KS 检验:用于判断样本数据是否与某个理论分布一致。
在原代码 ks.test(data, "pnorm") 中:
- 原假设(H₀):
data服从标准正态分布。 - 备择假设(H₁):
data不服从标准正态分布。
若 p 值 < 显著性水平(如 5%),则拒绝原假设,认为 data 不服从标准正态分布。
修正:检验一般正态分布:
ks.test(data, "pnorm", mean = mean(data), sd = sd(data))
(4)Augmented Dickey-Fuller(ADF)检验:检验时间序列是否存在单位根,即判断序列是否平稳。
在原代码 adf.Test (data) 中:
- 原假设(H₀):序列存在单位根(非平稳)。
- 备择假设(H₁):序列不存在单位根(平稳)。
若 p 值 < 显著性水平(如 5%),则拒绝原假设,认为 data 不存在单位根,平稳。
代码未显式指定滞后阶数,依赖 adf.test 函数的默认选择:trunc((length(x)-1)^(1/3))。
(5)ARCH-LM 检验
检验时间序列残差是否存在自回归条件异方差(ARCH 效应),即波动聚集性(Volatility Clustering)。
在原代码 ArchTest(data,1) 中,滞后阶数为 1 :
- 原假设(H₀):残差序列无 ARCH 效应(无异方差性)。
- 备择假设(H₁):残差存在 ARCH 效应(存在异方差性)。
若 p 值 < 显著性水平(如 5%),则拒绝原假设,认为存在 ARCH 效应。
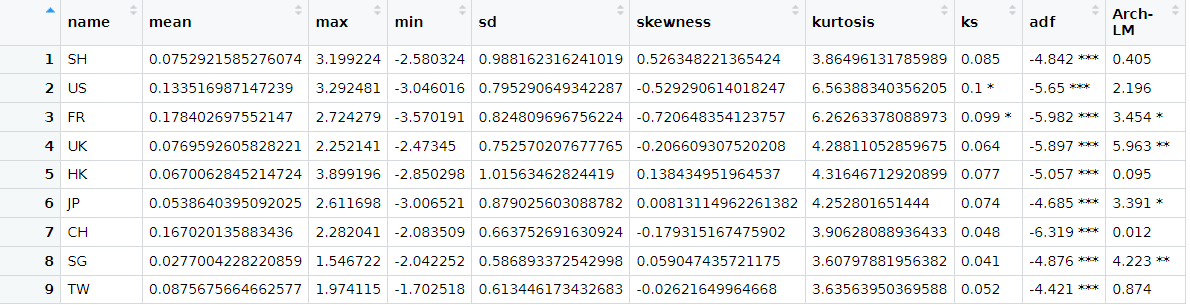
使用方法:
# 生成描述性统计表
descr_stats <- summarise(returns, RC)
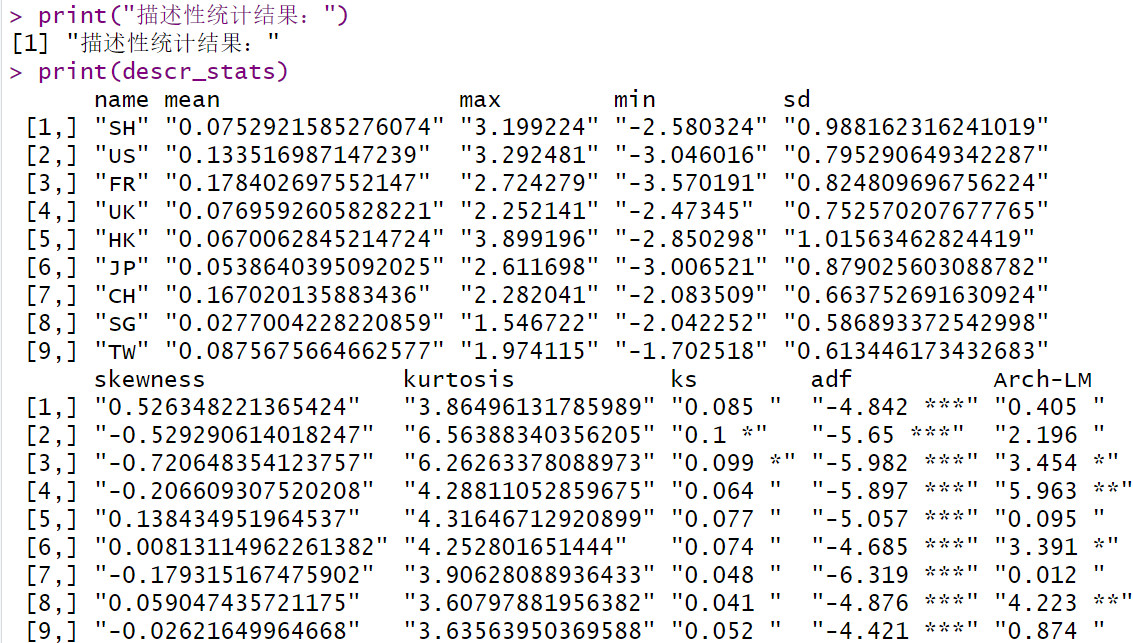
print("描述性统计结果:")
print(descr_stats)
write.csv(descr_stats, "descriptive_statistics.csv", row.names = FALSE)
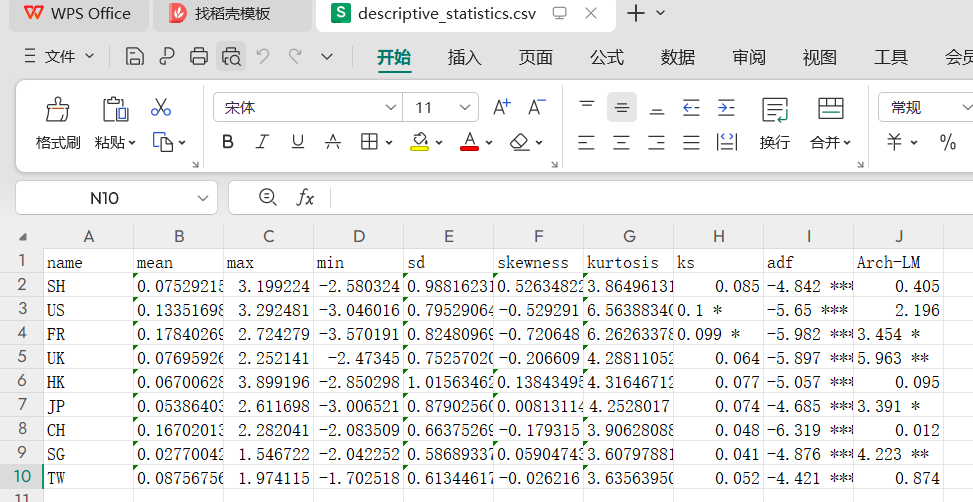
代码:
summarise<-function(data,RC){
data_set=as.numeric(RC$data_set)
summ<-matrix(data=NA,nrow=data_set,ncol=10)
colnames(summ)<-c("name","mean","max","min","sd","skewness","kurtosis","ks","adf","Arch-LM")
for(i in 1:data_set){
#name
summ[i,1]<-market_simp_name(i)
#data
data_1<-as.numeric(c(unlist(data[,(i)])))
#mean,max,min,sd
a<-as.numeric(summary(data_1))
summ[i,2]<-a[4]
summ[i,3]<-a[6]
summ[i,4]<-a[1]
summ[i,5]<-sd(data_1)
#skewness&kurtosis
summ[i,6]<-skewness(data_1)
summ[i,7]<-kurtosis(data_1)
#ks_test&adf_test
ks_result_test<-ks.test(data_1, "pnorm", mean = mean(data_1), sd = sd(data_1))
adf_result_test<-adf.test(data_1)
summ[i,8]<-paste(round(ks_result_test[["statistic"]],3),panduan(ks_result_test[["p.value"]]))
summ[i,9]<-paste(round(adf_result_test[["statistic"]],3),panduan(adf_result_test[["p.value"]]))
#ARCH-LM
archlm<-ArchTest(data_1,1)
summ[i,10]<-paste(round(archlm[["statistic"]],3),panduan(archlm[["p.value"]]))
}
summ
}


















 1307
1307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









