






有很多新手小白还是不是很清楚如何去介绍自己做的项目以及在面试中需要回答的问题
在这里我抽取了几个面试环节的必答题希望对大家有帮助!
文章目录
前言
随着大数据的大火,现在市场的空缺越来越大,很多朋友都想转行大数据,我也刚好从事大数据行业项目,每日更新一些非常重要的知识点希望对大家有帮助
=
一、请简单介绍一下的你的项目
一般去公司面试,面试官都会问你些关于大数据的问题,以及你从事的行业,如果回答不上来基本就会凉凉 在这里写一些通用模板
模板:
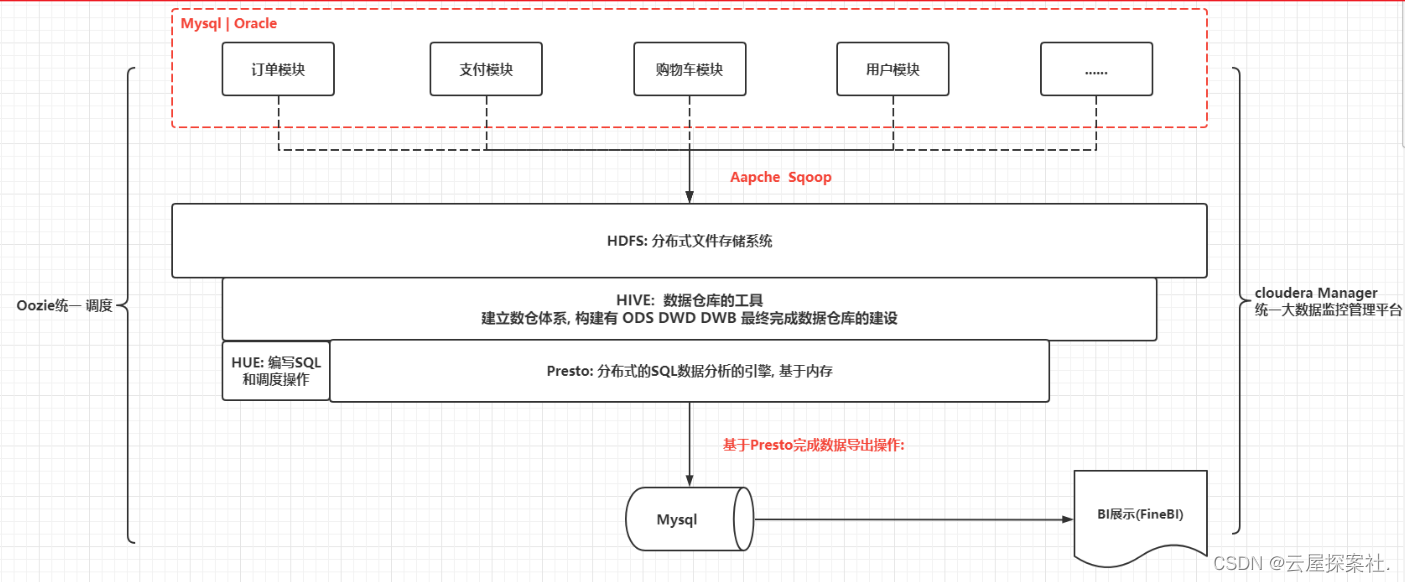
面试官您好, 我最近做了一个XXX项目, 当时主要是给XXX公司做的一个关于零售行业的项目, 项目的架构情况
后面描述这个项目的基本情况,整体做了那些工作, 项目团队与多少个人, 负责我们大数据开发有几个人等一些基本情况, 我在这个项目中主要参与了哪一部分的工作
完整回答(5-8分钟后即可):
面试官你好,我在最近做了一个亿万商品项目,当时主要给胖东来商贸集团做的一个汇总零售行业的项目,在这个项目里我们是基于cloudera manger搭建的大数据分析平台,在此平台上我们搭建有 hadoop hive oozie sqoop hue zookeeper 等协议大数据相关的组件,首先我们和甲方进行沟通拿到源数据,在这里我们还把数据分成了不同的模块以方便后面查找数据和调取数据,之后我们将数据导入到Oracle和Mysql中 因为考虑到数据的安全性所以我们将订单数据和支付数据存储等到Oracle中像用户模块和购物车模块我们通常存储在mysql中,之后通过sqoop将数据导入到HDFS上,基于HIVE构建ODS,DWS,DWB等数据仓库的建设,再基于presto完成统计分析的操作完成统计分析的操作,最后将统计的数据用presto来导入到mysql在这里我们也试着尝试用impala去导出数据但是存在一些瑕疵,还是选择了presto来导出 最终是通过finebi完成图表展示, 整个项目是统一基于oozie完成定时调度操作, 基于CM完成各个软件的监控管理,在这个项目中我们将整个阶段划分为两个并且对全国34家胖东来超市以及4家胖东来商场和一家胖东来家具城进行数据分析,在第一阶段中我们首先完成了初期的大数据平台的构建建初期我们只有11台机器,并且还要去完成调度平台的搭建工作,之后将源数据进行数据迁移把数据导入到Hadoop上,
我们还将整个整个销售主题的建模进行分析和操作,最后实现业务的基础销售需求指标,在第一阶段里我们的团队一共有5人 一位项目经理,3个大数据开发工程师,以及1名数据分析师共同分配完成整个项目在这一阶段我们用时2个月完成用了在这里我们主要利敏捷开发将一个大的项目分为多个小的小项目完成
在第二阶段我们由于数据量的增大我们完成了集群的扩容将原来的11台机器扩容到28台机器
同时还完成了presto集群的搭建完成了整个数据的迁移工作 完成以销售为主题的用户 商品 促销模块满足了公司90%以上的数据需求和报表并且可支持财务的成本和利润 在这阶段总共打配有7人1为项目经理 和4位大数据工程师和2名数据分析师并且提前完成任务用时2个月在这个项目中历史5年数据为17.5tb冗余数据为65tb每日新增9.5gb左右
二、请描述在你的这个项目中, 你是如何完成数据采集工作的,包含全量和增量: 8分钟 (6~10分钟)
完整回答:
是这样子的在进行数据采集的时候,我首先考虑的是将数据和数据源的粒度保持相同,并且考虑到数据源有哪些表,那么我们在采集数据的时候考虑有哪些表,表中有哪些字段,在进行导入的时候还需要考虑表的同步方式以及是否需要构建分区表以及是否要采取分桶表和表怎么压缩等问题,以及考虑每一个字段的作用因为在后续的DWS中我需要什么样的字段来进行判断和聚合这都是要考虑的
首先我会考虑到每个表需要用什么样的同步方式:
在面对一些地区表或者日期表我采取全量覆盖的方式来采取数据 因为在全量覆盖的时候不需要构建分区表每次都是将源数据覆盖在一个表中因为数据量不是很大,而且不需要维护
如果我碰见的一些表只有新增的话我会采取构建分区表 比如商品贫家表以及用户登录日志表 因为再考虑到仅新增的时候需要构建分区表并且采取以日期分区 时间的设置一般和更新有关 因为数据量庞大 而且只有新增 无需关心变化
在分析一些表的时候会发现有些表的数据既有新增比如订单表 购物车表又有修改的时候 我会采取拉链表的形式进行存储因为并且按天分区因为数据存在历史变更情况 再导入数据时需要将 新增和更新的数据进行区分导入到相应的区内
这些是我首要分析的三点其次对于表的存储方式,以及是否进行压缩也要去考虑 对于数据的储存格式在这个项目中基本上是按照orc来存储的同时一小部分数据是用textfile从hdfs上导入过来的
另外一个好的项目也要选对压缩方案 在这里呢 我是主要采取ZLIB和SNAPPY进行压缩如果数据写入次数大一读取次数我会采取ZLIB 或者GZ来进行压缩因为更节省空间压缩率也是很高,如果当表中的数据读写次数大于写入次数的时候我会采取snappy的形式进行压缩在这个项目中只有ODS我是采用ZIib进行压缩文件剩下的我用的都是Snappy
在这些分析中我都是一环套一环的进行数据采取的 在下面我会去考虑构建表的时候是创外表还是内标如果数据有控制权我会创建外表来保证数据的安全 如果没有则我用内表创建同时考虑是否构建分区表因为有些数据是需要进行分区同时分区表也能减少扫面的次数而提高查找的性能,同时呢因为数据量很大,难免会发生数据倾斜,在这里我会设置sql语句来避免数据发生倾斜发生,同时当我对一些表进行关联的时候有时候会发生数据效率低下 笛卡尔积过于高在这里我会设置分桶表来减少笛卡尔积 提高性能 并且在整个项目完成要对数据进行抽样调查看数据是否达到预期值我也会利用分桶来进行数据的采样
综上所述来进行数据的采集工作
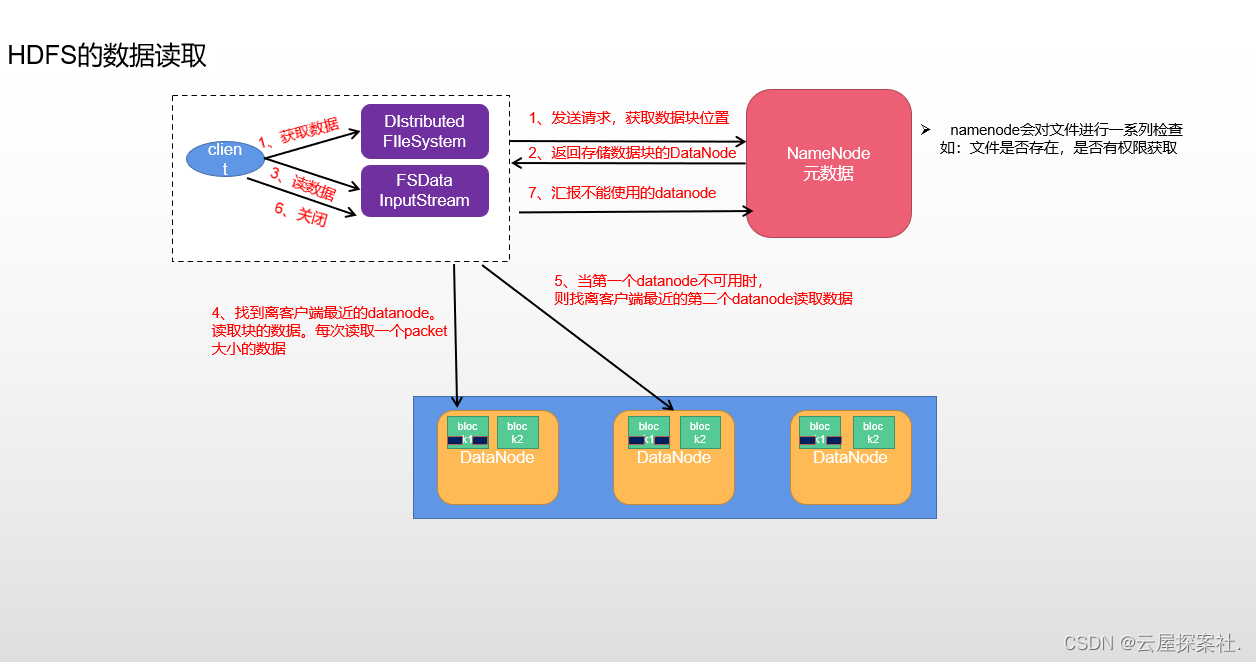
3.请简单介绍一下HDFS的数据读写流程
1.首先客户端发送请求 获取块信息的位置
2.然后namenode会进行一系列检查 比如文件是否存在 是否有权限获得
3.namenode返回datanode所存储的块信息
4.客户端找到最近的datanode 读取数据 每次读取一个packet大小的数据如果第一个datanode不能用的时候那么则找离客户端最近的第二个数据并且是异步的
5.最后关闭客户端 并且汇报不能用的datanode
1客户端数据由dlstributefilesystem保存然后发送请求 请求 上传保存数据
namenode会先去核实信息是否存在 检查路径 并且说可以保存
3.写入数据写入到fsdataoutputstream然后写入packet
当第一个packet写入后换回一个ack应答 接收应答并且读取下一个数据接受到了数据会复制给其他的node 不过复制数据 是异步的
当第一块数据写入后 创建第二个block 接着写入数据 循环往复数据写入完后会关闭
最后向namenode确认是否保存完成
4.请简单描述一下zookeeper中提供四种节点有那些, 以及特点是什么
(1)PERSISTENT-持久节点
除非手动删除,否则节点一直存在于 Zookeeper 上
( 2 ) EPHEMERAL- 临时节点
临时节点的生命周期与客户端会话绑定,一旦客户端会话失效(客户端与 zookeeper 连接断开不一定会话失效),那么这个客户端创建的所有临时节点 都会被移除。
( 3 ) PERSISTENT_SEQUENTIAL- 持久顺序节点
基本特性同持久节点,只是增加了顺序属性,节点名后边会追加一个由父节点维 护的自增整型数字。
( 4 ) EPHEMERAL_SEQUENTIAL- 临时顺序节点
基本特性同临时节点,增加了顺序属性,节点名后边会追加一个由父节点维护的 自增整型数字。
zookeeper原文链接:https://blog.youkuaiyun.com/weixin_43882788/article/details/122077076
————————————————

















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









