







目标检测
目标检测的任务是尝试去看一下这个图片里面到底有那些东西/物体,识别图片里面所有我们感兴趣的物体,是一只猫或者是一只狗等等,而且不仅如此,目标检测还需要把物体在这个图片中的位置给找出来,用方框来框定位置。
边缘框Bounding Box(bbox)
是用来表示物体的位置的,当然表示方法可以有很多种,但一般都是用四个数字来定义,这4个数字就是在预测物体位置的时候需要去预测出来的数据。
通常有如下几种表示方式,都是以整张图片的左上角点为坐标原点(0,0),bbox框的:
(左上x, 左上y, 右下x, 右下y)
(左上x, 左上y, 宽w, 高h)
(中心点x, 中心点y, 宽w, 高h)
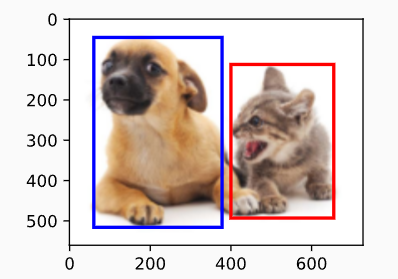
这个边缘框呢按照种类来分又可以分成预测出来的检测框,以及数据集中人工标注的真实框Ground truth,因此在有些资料中也被称作GT框,也就是真值。
数据集
目标检测的数据集其标签label值需要单独存,当然图片是要存储的,而标签值的存储方法有很多,简单来讲就是可以用一个文本文件来存储所有的标签值,里面有很多行,每一行表示一个图片中的一个物体,需要存储:图片文件名、物体类别以及边缘框的4个值等共6个数据。然后有很多行,这样一个文件就可以存储完所有图片的标签值了。其中的物体类别呢就是所有你感兴趣或者有标号的物体类别的序号,如0-人 1-狗 2-猫等等之类的。
一个非常著名的开源数据集被称为COCO数据集,官方网址为:COCO - Common Objects in Context
在学术界用的非常广泛。
与边缘框相关的代码如下:
# 在PyCharm中
import torch
from d2l import torch as d2l
import matplotlib.pyplot as plt
# 设置 Matplotlib 后端
import matplotlib
matplotlib.use('TkAgg')
d2l.set_figsize()
img = d2l.plt.imread('./img/catdog.jpg')
d2l.plt.imshow(img)
# 确保显示图像
# plt.show()
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
# 各列 这些张量的形状都是 (N,),即 N 个数。
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
# 这些张量的形状仍然是 (N,)。
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
# torch.stack 会在指定维度 新增 一个维度,并把所有输入的张量堆叠在一起
# 沿着最后一个维度(axis=-1)堆叠,得到的 boxes 形状变为 (N, 4),
# 即 N 行,每行有 4 个元素 (cx, cy, w, h),对应新的坐标格式。
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









