







正则表达式
1.什么是正则表达式?
正则表达式就是一系列规则,描述了一种字符串匹配的模式,通过这个规则可以在字符串中找到相关的内容;以下以c++语言使用正则表达式为例;
2.正则表达式使用大致流程
c++中正则表达式API基本在regex头文件中,使用正则表达式的大致流程:
- 你有一段需要处理的文本,字符串、文本文件、日志等
- 有一个特定目标,找出文本文件中所有的时间和日期等
- 根据可能的格式写出具体的正则表达式,比如日期是2020-01-01,正则表达式可能是这样:\d{4}-\d{2}-\d{2}。
- 将文本和正则表达式交给正则表达式引擎(由具体的语言提供),引擎会在文本中搜索到匹配的结果;
3.三种最常见的使用方式
- 匹配:判断给的字符串是否符合某个正则表达式,比如判断当前文本是否全部由数字组成:

- 搜索:在一大段文本中搜索匹配的目标:

- 替换

4.正则表达式语法
-
c++中内置了多种正则表达式语法,在创建的时候可以通过参数来选择;我们直接使用默认选项ECMAScript语法,也就是ECMA-262(JavaScript中也是使用它);详情可以点击链接:http://ecma-international.org/ecma-262/5.1/#sec-15.10
-
如果正则表达式有太多的转义字符,变得很复杂的时候,可以使用Raw string literal,原始字符串,他不会将反斜杠解释为转义字符;比如:
string s = R"(\w\w\\w)"; -
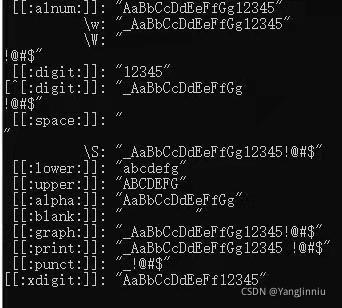
字符类:对字符的分类,比如0~9属于数字字符;
字符类 简写 说明 [[:alnum:]] 字母和数字 [_[:alnum:]] \w 字母,数字以及下划线 [^_[:alnum:]] \W 非字母,数字以及下划线 [[:digit:]] \d 数字 [^[:digit:]] \D 非数字 [[:space:]] \s 空白字符 [^[:space:]] \S 非空白字符 [[:lower:]] 小写字母 [[:upper:]] 大写字母 [[:alpha:]] 任意字母 [[:blank:]] 非换行符的空白字符 [[:cntrl:]] 控制字符 [[:graph:]] 图形字符 [[:print:]] 可打印字符 [[:punct:]] 标点字符 [[:xdigit:]] 十六进制的数字字符
说明:
①字符类通过[]来标识,使用方括号包含一系列字符能够匹配其中任意一个字符,比如[abc]就是匹配a或b或c。
所以这两个字符在正则表达式中是特殊字符,如果想使用这两个字符,需要转义;相同的还有\r、\n、\t、\\、^、\.、\$等
②在[]内部,^标识否定;
③一些常用的字符类拥有简写


输出结果为:
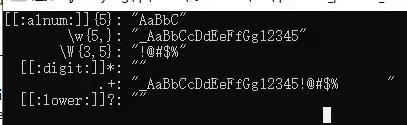
4. 重复:一次性匹配一个完整的字符串,例如一个电话号码
字符 说明
{n} 重复n次
{n,} 重复n或更多次
{n,m} 重复n~m次
* 等同于{0,}
+ 等同于{1,}
? 等同于{0,1}

输出结果为:
5.正则表达式编程
-
迭代器:统计出文档中单词的数量

-
正则表达式选项
在创建正则表达式时,除了描述规则本身之外的字符串之外,还可以传递一个flag_type类型的参数,定义在std::regex_constants::syntax_option_type中;flag_type类型有以下值:值 效果 icase 以不考虑大小写进行字符匹配。 nosubs 进行匹配时,将所有被标记的子表达式 (expr) 当做非标记的子表达式 (?:expr) 。 不将匹配存储于提供的 std::regex_match 结构中,且 mark_count() 为零 optimize 指示正则表达式引擎进行更快的匹配,带有 令构造变慢的潜在开销。例如这可能表示将 非确定 FSA 转换为确定 FSA 。 collate 形如 “[a-b]” 的字符范围将对本地环境敏感。 multiline(C++17) 若选择 ECMAScript 引擎,则指定^匹配行 首,$应该匹配行尾。
这其中最常用的就是icase,比如要匹配文本中所有的"hahaha",并不区分大小写,就可以这样构建正则表达式:
regex word_regex("hahaha?",regex::icase);
- 匹配结果与分组
当我们使用正则表达式时,有时需要捕获匹配结果的子串,比如我们匹配了日期之后还希望拿到年份、月份等信息;
std::match_results用来存储匹配结果,分组(c++中分组叫做子匹配:std::sub_match)用来捕获子串,圆括号()就是用来分组的;当在正则表达式中配对的使用圆括号时就会形成一个分组,分组通过编号0,1,2…来区分,编号0是匹配的整体,其他的根据分组顺序确定;
这些分组最终可以在匹配完成之后通过std::match_results的API来获取:
API 说明
empty 检查匹配是否成功
size 返回结果的匹配数
max_size 返回子匹配的最大可能数
length 返回特定分组的长度
position 返回特定分组首字符的位置
str 返回特定分组的字符串
operation[] 返回指定的分组
prefix 返回目标序列起始和完整匹配起始之间的分组
suffix 返回完整匹配结果和目标序列结尾之间的分组
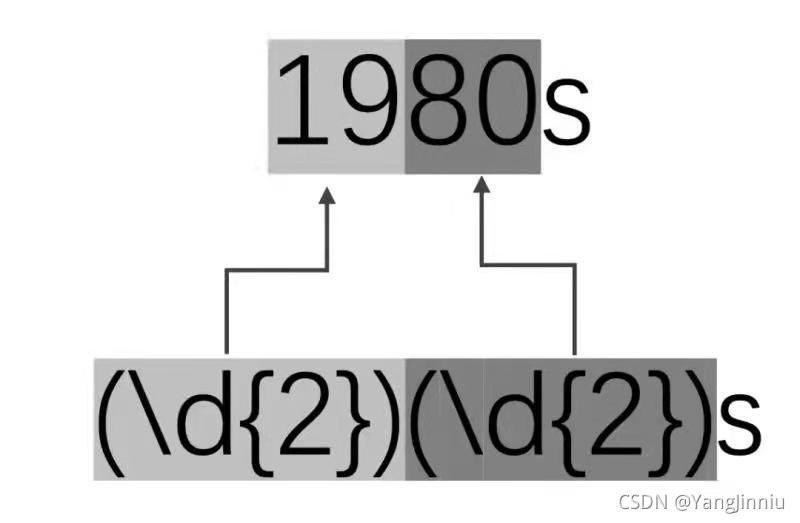
示例:查找出文本文件中的所有年代,并分离出世纪部分和年份部分:

在实际应用中,常常会写出非常复杂的正则表达式,可以点这里查看一些实例: http://regexlib.com/DisplayPatterns.aspx
复杂的正则表达式常常很难理解,以下两个工具可以帮上忙:
https://regex101.com
https://www.debuggex.com
深入学习可以看书《精通正则表达式》
6说明
本文来自公众号c语言与cpp编程中的文章《c++与正则表达式》;

















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









