







mysql复习
1.查询
select 字段名 from 表名称
select和from都是关键字,字段名和表明是标识符
select DNAME from dept
2.查询多个字段
select 字段名,字段名 from 表名称
3.查询所有
selete * from 表名
不建议使用*转化为字段效率低,并且可读性差
select * from dept;
4.查询结果起一个别名
select 字段名,字段名 as 字段名 from 表名
as可以用空格代替
select 字段名,字段名 字段名 from 表名
5.查询一个字段的n倍,字段可以参加加减乘除运算
select 字段名*12 from 表名
select ENAME,SAL*12 from emp;
select ENAME,SAL*12 ‘年薪’ from emp;
6.条件查询
selete 字段 from 表明 where 条件
=等于, select ENAME,SAL ‘薪水’ from emp where SAL=800;
<=小于等于,, select ENAME,SAL ‘薪水’ from emp where SAL<=800;
‘’>=大于等于
!=不等
<>不等
‘>大于
在两个值之间
between 。。 and 。。
<= xx and>= xx
select ENAME,SAL ‘薪水’ from emp where SAL>=800 and sal<=2500;
select ENAME,SAL ‘薪水’ from emp where sal between 800 and 2400;
使用between and 必须做小有大
is null 为空
数据库为null 不能使用=null ,数据库为空是真为空,内部无任何数据。
必须使用 is null
select ENAME from emp where comm is null ;
is not null 不为空
select ENAME from emp where comm is not null ;
and 合并多个条件,并且
select sal ,ename
from emp
where job=‘manager’ and sal >2400
or 或者
select sal ,ename,job
from emp
where job=‘manager’ or
job=‘salesman’
and和or 的优先级
select *
from emp
where sal >2500 and deptno=10 or deptno=20;
工资大于2500编号为10 或者编号为20的信息
加上括号,解决这个问题
select *
from emp
where sal >2500 and( deptno=10 or deptno=20);
in or in 包含,in相当于多个or
select *
from emp
where job=‘manager’ or job =‘slaesman’;
select *
from emp
where job in (‘manager’,‘slaesman’);
like 模糊查询
select *
from emp
含有m
where job like ‘%m%’;
以m开头
where job like ‘m%’;
以m结尾
where job like ‘%m’;
第2个是m
where job like ‘_m’;
如果要查的里面有_可以使用\转义
where job like ‘%_’;
6.排序查询
升序
select ename ,sal
from emp
order by
sal (asc);
降序
select ename ,sal
from emp
order by
sal desc;
多个字段进行排序,只有排序字段一样时才会启用第二个字段
select ename ,sal
from emp
order by
sal ,ename;
7.数据处理函数
7.1单行处理函数, 一个输入对应一个输出
一行行进行处理
多行处理,处理函数,多个输入一个输出
select 可以跟着字段名和数据,像java的变量
lower 转小写 select lower(ename) ,sal from emp
upper 转大写 select UPPER(name) from t_student
substr 截取字符床第一个是从什么位置开始,第二个是截取多长 select substr(ename,1,1) as name from emp;
concat 字符串拼接 select concat(name,age) from emp;
trim 去除前后空白 select name from student whrere name=trim(’ kli ‘)
round 四舍五入第一个是数字,第二个保留几位 select round(121.545,1) as number from emp;

一百以内的随机数 select ROUND(rand()*100,0) as number from emp;
有null 参与的运算为null
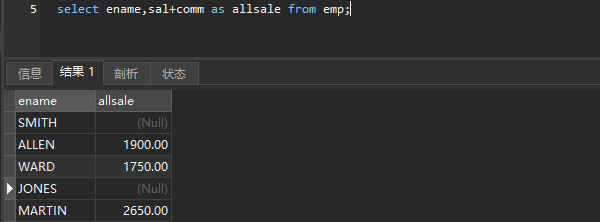
ifnull ifnull(数据)
如果为空当作ifnull的数据
select ename,sal+IFNULL(comm,0) as allsale from emp;
case…when…then…when…then 可以当作if else使用
select ename,job ,sal old,
case job when ‘MANAGER’ then sal1.1 when ‘SALESMAN’ then sal1.5 else sal end as newsal
from emp;
8.分组函数多行处理函数
count 计数
sum 和
avg 平均 select avg (sal) from emp;
max 最大值
min 最小
分组函数自动忽略null
统计总行数
select count(*) from emp;
不为null的行数
select count(salt) from emp;
分组函数能组合使用
我写
select x
from x
where x
goup by x
order x
实际的执行顺序是
from where goupby select orderby
为分组之前where种不能使用分组函数
使用having进行过滤
having需要和goupby共存 不能单独出现,代替where
优先选择having
distinct 只能出现字段的前方,后面的多个字段是对多个字段进行去重,
select count(distinct job,deptno) FROM emp;
9.连接查询
没有限制就会产生 n * n 条记录,成为笛卡儿积现象
加上条件解决问题;但是匹配次数没有减少
select ename,dname from emp,dept where emp.deptno=dept.deptno;
去别名加快效率
select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno;
内链接的等值连接
select e.ename,d.dname from emp e,dept d where e.deptno=d.deptno;
select e.ename,d.dname
from emp e
join dept e
on e.deptno=d.deptno
内链接的不等值连接
select e.ename,e.sal,s.grade
from emp e
join salgrade s
on e.sal between s.losal and s.hisal;
内链接的自连接
select a.ename anme ,b.ename bname
from emp a
join emp b
on a.mgr=b.EMPNO;
外连接,会产生主次关系,匹配不到也显示出来
right 代表join关键字右边的这张表看成主表,主要为了将这张表的数据全部查询出来,少点这关联查询左边的表
left 是左链接
select a.ename anme ,b.ename bname
from emp a
left join emp b
on a.mgr=b.EMPNO;
10.多连接
多个join on 就好了
select e.ename,e.sal,d.dname,s.grade
from emp e
join dept d
on e.deptno=d.DEPTNO
join salgrade s
on e.sal BETWEEN s.LOSAL and s.HISAL;
11.子查询
select内套select
select /from/where 都可以嵌套字查询
where嵌套
select ename,sal from emp where sal>(select min(sal) FROM emp);
from
就是将查询结果当作一张表
select t.*,s.grade
from
(select job,avg(sal) as avgsal from emp group by job) t
join salgrade s
on
avgsal BETWEEN s.LOSAL and s.HISAL;
12.union
将查询结果合并 ,大量结果下效率高一点。将乘法变为加法。
集合合并的时候列数项目,数据类型一致
select ename,job from emp where job=‘MANAGER’
union
select ename,job from emp where job=‘SALESMAN’
13.limit
取多少数据
select ename,sal
from emp
order by sal desc
limit 0,5;
//第一个代表起始位置,第二个代表几个数据,长度
一般的分页是
limit (pageno-1)*pagesize ,pagesize
14.表
crate table 表明(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型
);
15.插入语句
insert into 表明(字段名) values(值);
str_to_data 字符床转日期类型
mysql的日期需要加上% %y %m %d %h %i %s 年月日时分秒
str_to_data(“1999-10-1”,%y-%m-%d)
data_format(日期,日期格式) 格式话转化
data是段日期只有年月日 datatime是长日期有年月日时分秒
默认 %y-%m-%d %h:%i:%s
now()直接获取当前时间带时分秒
16.修改
update 表名 set 字段名=值,字段名=值 where 条件;
update t_student
set no=3,name='eee'
where no=2;
删除
delete from t_student where no=3
插入多条记录
insert into 表明(字段名1,字段名2) values (),(),();
快速创建表
create table emp2 as select * from emp;
快速删除表的数据
delete from dept
delete删除时一个个删除会保留空间可以回滚,删除效率低
truncate 删除物理删除,较快,不支持回滚
truncate table t_student
17.存储引擎
存储引擎就是表的存储数据方法
show create table xx; 查看建表命令
存储引擎有九个
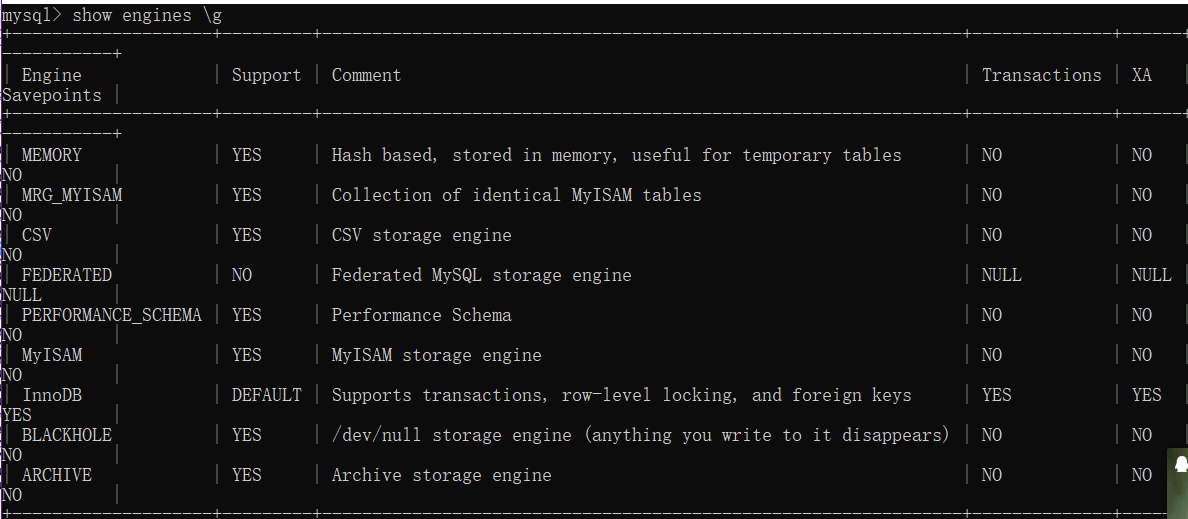
mysql 常用搜索引擎
myisam 用三个文件表示一个表分别是格式文件/数据文件/索引文件,可以压缩和只读来节省空间
innodb默认的存储引擎,支持失误,支持数据库的自动回复。
memory存储存储引擎就是堆引擎存在内存种,查询快,关机断电消失
18.事务
innodb提供了事务活动的日志
提交事务,清空日志文件,将数据持久化到数据库表中
回滚,所有操作全部撤消,清空事务性活动的日志文件
读未提交
事务A能读取B未提交的数据,产生脏读
读以提交
事务A只能读事务B提交的数据,解决了脏读
但是产生了不可重复读取数据,A读刚时B是3,b变为了4,A读取了4;
可重复度
每次都是一次的数据,解决了不可重复读,
但是产生了幻读,读取了事务刚开始的数据
序列化 效率低,就像加锁,不能同步
19.索引
创建
create index emp_xx on emp(ename);
删除
drop index emp_xx on emp;
查看是否使用索引
expain select xxx

















 8811
8811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









