







本次主要使用决策树对sklearn中提供的iris数据集进行分类,并可视化决策树。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV # 使用网格搜索和交叉验证来查看最佳参数
iris_data = load_iris()
# 数据集划分
x_train,x_test,y_train,y_test = train_test_split(iris_data.data,iris_data.target,train_size=0.8)
# 数据预处理---归一化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 预估器流程---决策树进行预估
estimator = DecisionTreeClassifier()
estimator = GridSearchCV(estimator,{'criterion':['gini','entropy'],'max_depth':[1,3,5,7,9,10]},cv=4) # 进行4折交叉验证
estimator.fit(x_train,y_train)
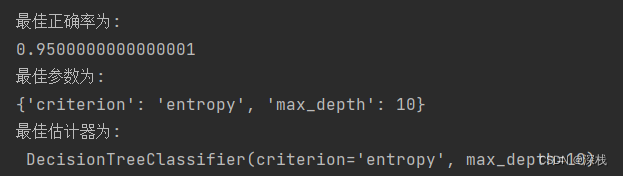
print(f'最佳正确率为:\n{estimator.best_score_}')
print(f'最佳参数为:\n{estimator.best_params_}')
print("最佳估计器为:\n", estimator.best_estimator_)
print(f"交叉验证结果为:{estimator.cv_results_}")
前三项的运行结果如下所示:
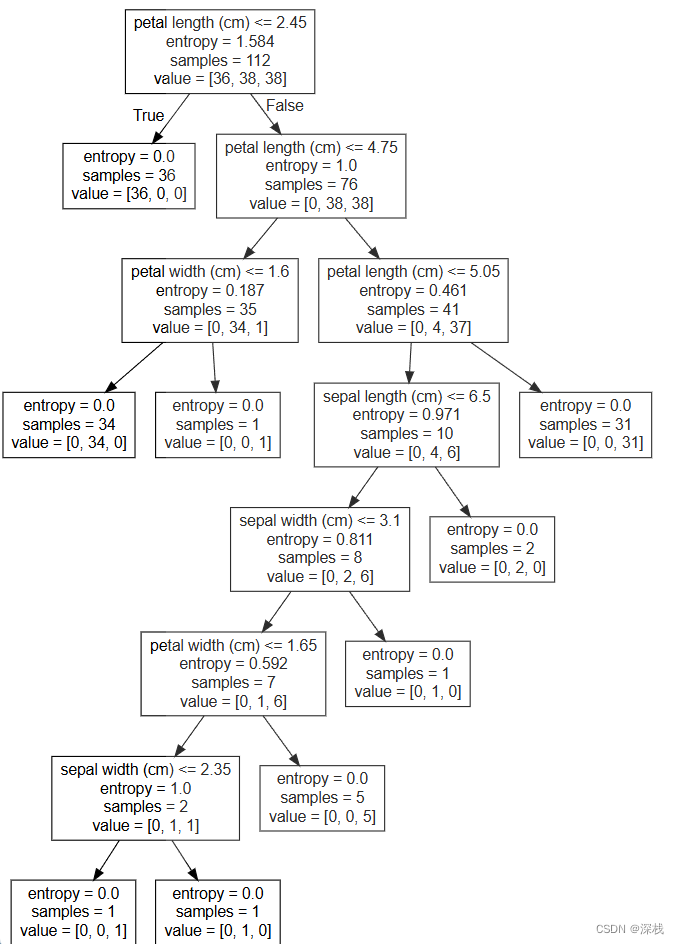
max_depth=8时决策树如下所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









