







在机器学习中,Facebook用户签到预测案例是一个经典的地理位置预测问题。这个问题的目标是根据用户的历史签到数据预测用户未来可能的签到位置。数据通常包括用户ID、签到时间、签到地点的经纬度、位置ID等。
本次用到的部分数据集如下所示(该数据集测试集一共有8607229条数据,训练集有29118021条数据)
数据集下载点这里Facebook用户数据签到位置预测
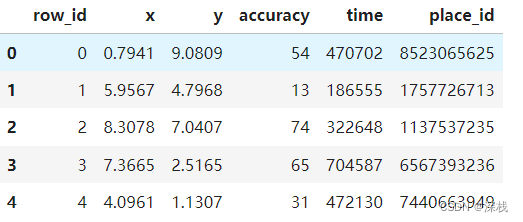
其中,row_id表示数据对应的id,在预测时无作用,x,y表示对应的经纬度,而accuracy表示测量进度,time表示时间戳(1970年1月1日起始),place_id为签到位置对应的id
任务:给定用户的签到记录,预测用户未来可能签到的地点(place_id)
任务流程:
1、首先获取数据
2、数据处理(时间戳转化成对应的年月日,过滤掉签到次数少的地方,认为3次及以下为少)
3、筛选特征值目标值
4、数据集划分(此处仅用训练集的数据进行训练和测试)
5、预估器训练
6、模型评估与调优
具体代码如下(此处使用jupyter notebook):
# 1、获取数据
import pandas as pd
data = pd.read_csv(r"E:\Python_learning\py基础\machine_learning\FBlocation\train.csv")
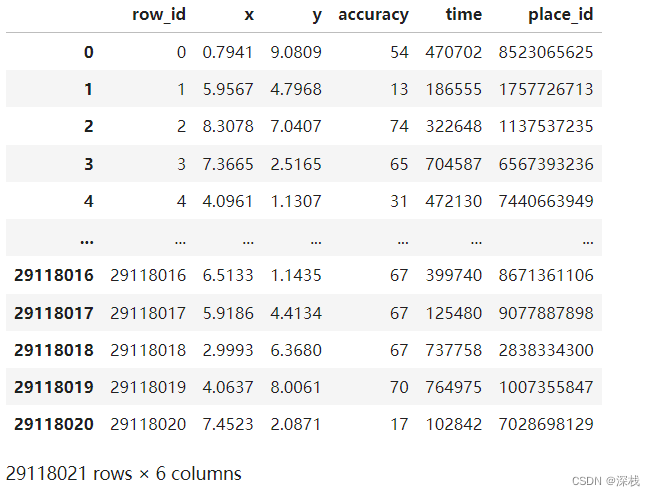
获取的data如下所示:
# 时间戳转换成年月日,过滤掉签到次数少的位置
time_value = pd.to_datetime(data['time'],unit='s')
time_value.values
date = pd.DatetimeIndex(time_value)
# 将转化后的数据添加到原式的数据集中
data['day'] = date.day
data['weekday'] = date.weekday
data['hour']=date.hour
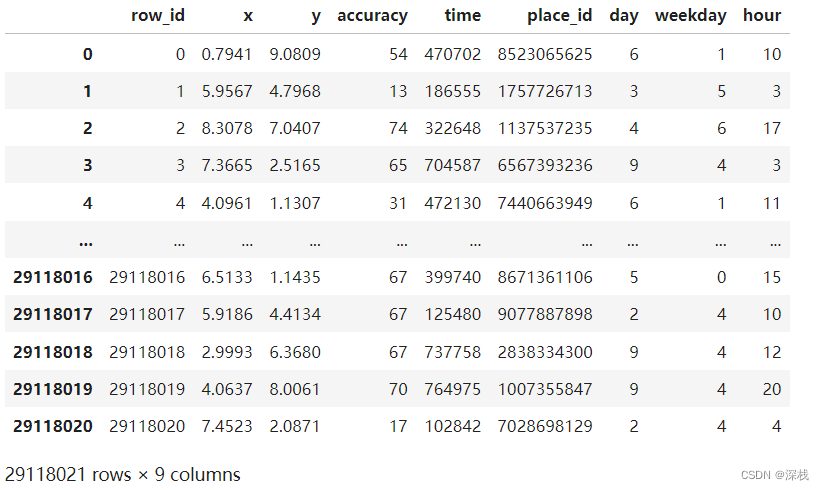
此时data如下所示:
# 过滤掉签到次数比较少的地点以及筛选x在2到2.5之间的数据,y为1到1.5之间的数据,否则数据量太大,训练耗时多
data = data[(data['x'] >= 2) & (data['x'] <= 2.5) & (data['y'] >= 1) & (data['y'] <= 1.5)]
place_count = data.groupby('place_id').count()['row_id']
place_count[place_count > 3].head()
data_final = data[data["place_id"].isin(place_count[place_count > 3].index.values)]
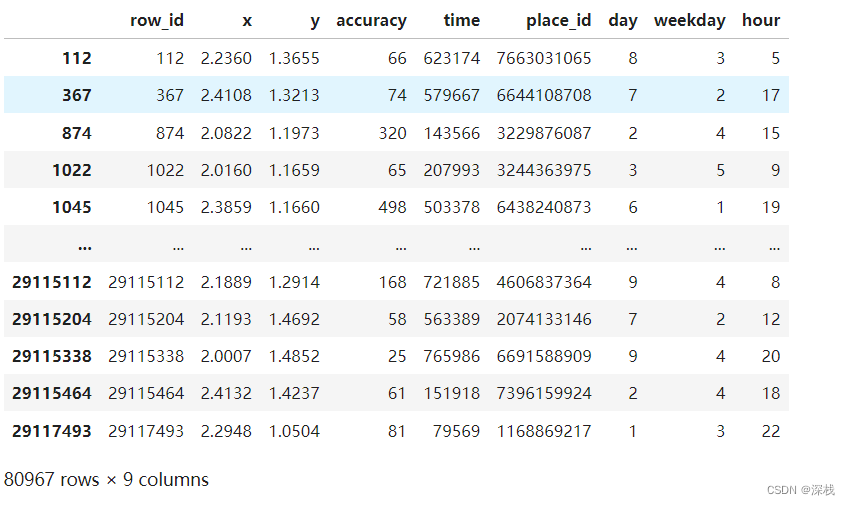
过滤后效果如下:
# 筛选特征值和目标值
x = data_final[['x', 'y', 'accuracy', 'day', 'weekday', 'hour']]
y = data_final['place_id']
# 数据集划分
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y)
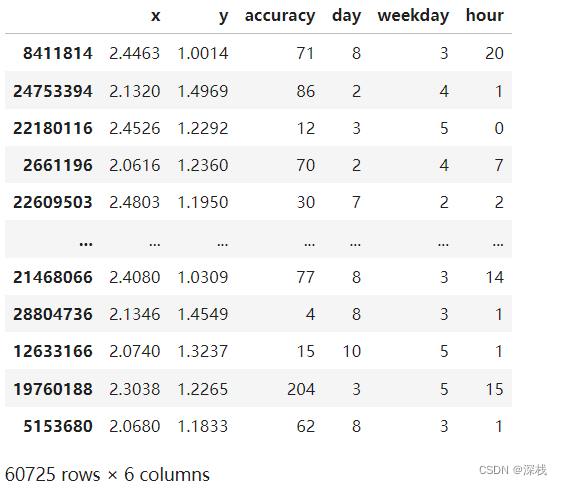
分割后训练集如下所示(60725条数据):
# 特征工程---标准化
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV
# 实例化StandScaler类对象
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# KNN模型训练
estimator = KNeighborsClassifier()
# 网格搜索和交叉验证的参数准备
param_dict = {"n_neighbors":[3,5,7,9,11]}
estimator = GridSearchCV(estimator,param_grid = param_dict, cv=3)
# 训练
estimator.fit(x_train,y_train)
# 模型评估与调优
y_predict = estimator.predict(x_test)
y_predict = estimator.predict(x_test)
print(f"y_predict和y_test是否相等:\n{y_predict == y_test}")
print(f"准确率为:{estimator.score(x_test, y_test)}")
print("最佳参数为:\n", estimator.best_params_)
print("最佳准确率为:\n", estimator.best_score_)
print("最佳估计器为:\n", estimator.best_estimator_)
print("交叉验证结果:\n", estimator.cv_results_)
运行结果如下:
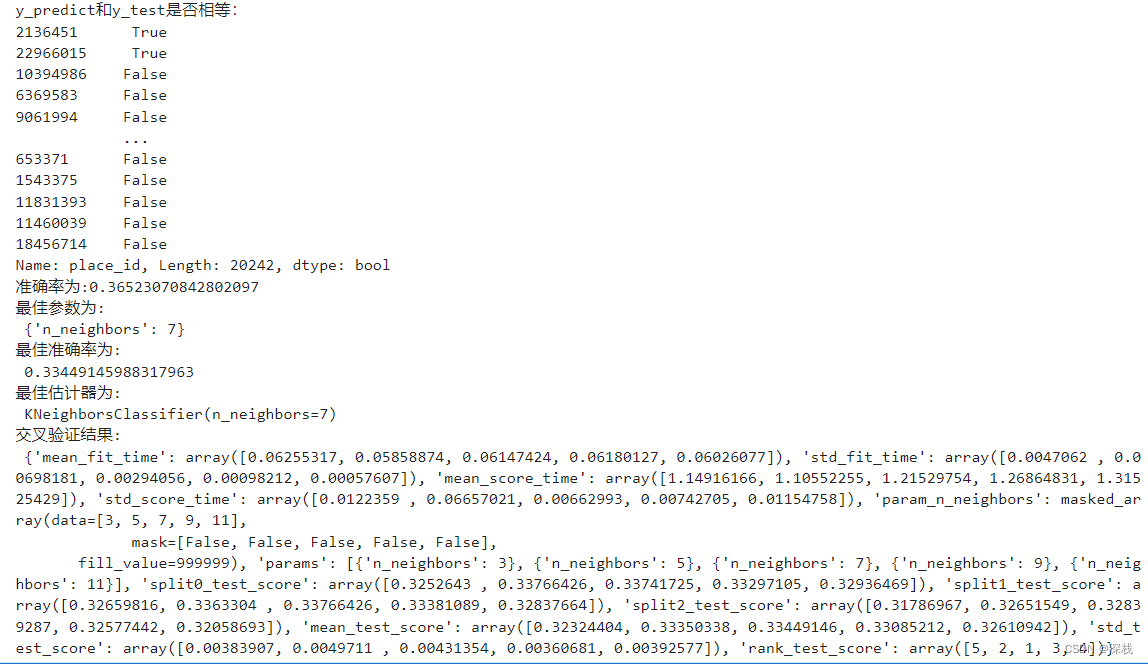
此时正确率较低,是因为筛选了经纬度固定的用户数据,但是我们在处理数据时还新增了一些数据,且过滤掉了次数少于3次的地点,最后,KNN是一个基于距离的算法,对线性关系处理较好。如果数据存在非线性关系,可以尝试其他算法,如随机森林、XGBoost或神经网络等等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









