







1、特征降维是什么?
降维是指在某些特定的限定条件下,降低随机变量(特征)的个数,得到一组“不相关”主变量过程
相关特征:两个特征之间存在某些关系,例如降雨量和空气湿度是相关特征。
2、特征降维的方法有哪些?
Filter(过滤式)
a)方差选择法:低方差特征过滤(例如判断鸟的种类中,特征是否有爪子属于低方差特征,低方差数据比较集中,过滤)
sklearn.feature_selection.VarianceThreshold(threshold=0.0)
threshold为阈值,默认为0,即删除所有方差为0的特征
Variance.fit_transform(x):x为numpy array格式的数据,返回值为低于threshold的特征删除后的结果
import numpy as np
from sklearn.feature_selection import VarianceThreshold
# 示例数据
X = np.array([
[0, 2, 0, 3],
[0, 1, 4, 3],
[0, 1, 1, 3]
])
# 初始化 VarianceThreshold,默认 threshold=0.0
selector = VarianceThreshold()
# 进行特征选择
X_reduced = selector.fit_transform(X)
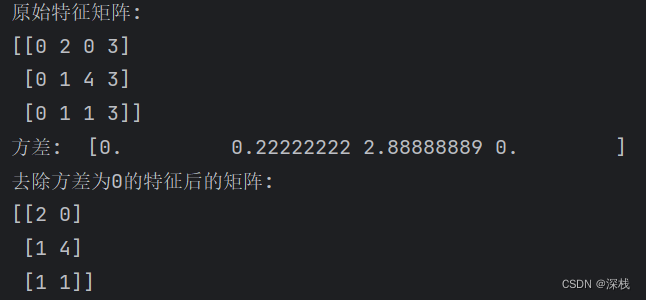
print("原始特征矩阵:")
print(X)
print("方差: ", selector.variances_)
print("去除方差为0的特征后的矩阵:")
print(X_reduced)
初始矩阵第一列和第四列元素为0,即方差为0,所以执行后结果如下:
b)相关系数法:衡量特征与特征之间相关性,相关性很强需要处理。
皮尔逊相关系数计算公式如下:
r
=
∑
i
=
1
n
(
X
i
−
X
‾
)
(
Y
i
−
Y
‾
)
∑
i
=
1
n
(
X
i
−
X
‾
)
2
∑
i
=
1
n
(
Y
i
−
Y
‾
)
2
r=\frac{\sum\limits_{i=1}^n(X_i-\overline{X})(Y_i-\overline{Y})}{\sqrt{\sum\limits_{i=1}^n(X_i-\overline{X})^2}\sqrt{\sum\limits_{i=1}^n(Y_i-\overline{Y})^2}}
r=i=1∑n(Xi−X)2i=1∑n(Yi−Y)2i=1∑n(Xi−X)(Yi−Y)
通常用皮尔逊相关系数法,相关系数
r
r
r介入
−
1
-1
−1到
1
1
1之间
当
r
r
r大于
0
0
0,二者呈正相关,
r
r
r小于
0
0
0,二者呈现负相关,
∣
r
∣
|r|
∣r∣越接近于
1
1
1,相关性越强,一般按以下三级划分
∣
r
∣
<
0.4
|r|<0.4
∣r∣<0.4为低度相关
0.4
≤
∣
r
∣
<
0.7
∣
0.4≤|r|<0.7|
0.4≤∣r∣<0.7∣为显著相关
0.7
≤
∣
r
∣
<
1
0.7≤|r|<1
0.7≤∣r∣<1为高度线性相关
API:from scipy.stats import pearsonr
pearsonr(x,y),x,y为两个特征,返回相关系数
import numpy as np
from scipy.stats import pearsonr
# 示例数据
# 两个特征的数据
feature1 = np.array([1, 2, 3, 4, 5])
feature2 = np.array([2, 4, 6, 8, 10])
# 计算 Pearson 相关系数
pearson_correlation = pearsonr(feature1, feature2)
print("特征1: ", feature1)
print("特征2: ", feature2)
print("Pearson 相关系数: ", pearson_correlation)
运行结果如下:

下面用数学方法计算:
feature1的均值为
3
3
3,feature2的均值为6
分子:
(
1
−
3
)
(
2
−
6
)
+
(
2
−
3
)
(
4
−
6
)
+
(
3
−
3
)
(
6
−
6
)
+
(
4
−
3
)
(
8
−
6
)
+
(
5
−
3
)
(
10
−
6
)
=
20
(1-3)(2-6)+(2-3)(4-6)+(3-3)(6-6)+(4-3)(8-6)+(5-3)(10-6)=20
(1−3)(2−6)+(2−3)(4−6)+(3−3)(6−6)+(4−3)(8−6)+(5−3)(10−6)=20
∑
i
=
1
n
(
X
i
−
X
‾
)
2
=
10
{\sqrt{\sum\limits_{i=1}^n(X_i-\overline{X})^2}}=\sqrt{10}
i=1∑n(Xi−X)2=10
∑
i
=
1
n
(
Y
i
−
Y
‾
)
2
=
40
{\sqrt{\sum\limits_{i=1}^n(Y_i-\overline{Y})^2}}=\sqrt{40}
i=1∑n(Yi−Y)2=40
则皮尔逊系数为
r
=
20
10
40
=
20
20
=
1
r=\frac{20}{\sqrt{10}\sqrt{40}}=\frac{20}{20}=1
r=104020=2020=1
与上述结果一致。
p
−
v
a
l
u
e
p-value
p−value 是一个统计量,用于检验两个变量之间的相关性是否显著。
如果
p
−
v
a
l
u
e
p-value
p−value很小(通常小于
0.05
0.05
0.05),则可以拒绝原假设,认为两个变量之间存在显著的线性关系。
如果
p
−
v
a
l
u
e
p-value
p−value很大,则不能拒绝原假设,认为两个变量之间的线性关系不显著。
Embedded(嵌入式)
a)决策树:信息熵、信息增益
b)正则化:L1,L2
c)深度学习:卷积等
PCA降维
主成分分析 (Principal Component Analysis, PCA) 是一种用于降维的线性算法,旨在通过将数据投影到主成分上来减少数据的维度,同时尽可能保留数据的方差。主成分是原始特征的线性组合,按解释的方差从大到小排序。通过保留前几个主成分,可以在保留大部分信息的前提下显著减少特征的数量。
API:sklearn.decomposition.PCA(n_components=None)
将数据分解成较低维空间
n_components:
①小数:表示保留百分之多少的信息
②整数:减少到多少特征
PCA.fit_transform(x):numpy array格式数据,返回指定维度的array
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
# 示例数据:4个特征,10个样本
X = np.array([
[2.5, 2.4, 2.3, 2.2],
[0.5, 0.7, 0.8, 0.6],
[2.2, 2.9, 2.6, 2.4],
[1.9, 2.2, 2.1, 2.0],
[3.1, 3.0, 3.2, 3.3],
[2.3, 2.7, 2.5, 2.6],
[2, 1.6, 1.8, 1.9],
[1, 1.1, 1.2, 1.0],
[1.5, 1.6, 1.7, 1.8],
[1.1, 0.9, 1.0, 0.8]
])
# 创建PCA对象,并将数据降维到2个主成分
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
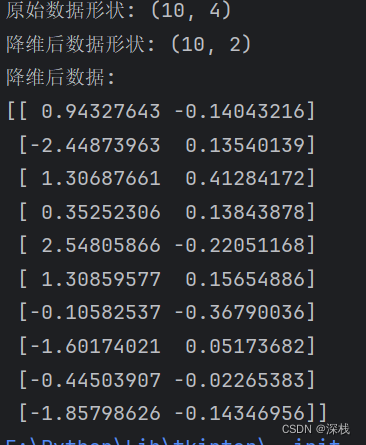
print("原始数据形状:", X.shape)
print("降维后数据形状:", X_pca.shape)
print("降维后数据:")
print(X_pca)
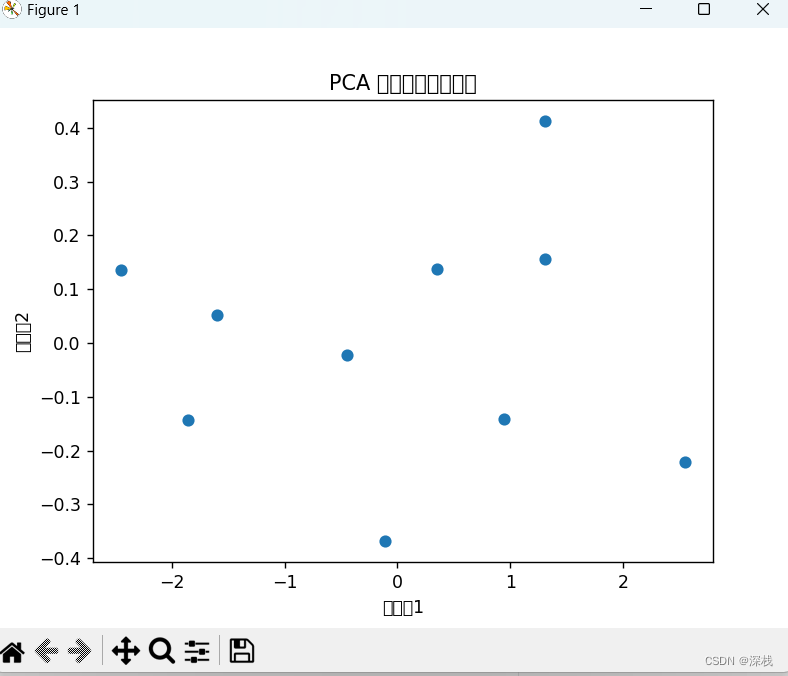
# 绘制降维后的数据
plt.scatter(X_pca[:, 0], X_pca[:, 1])
plt.xlabel('主成分1')
plt.ylabel('主成分2')
plt.title('PCA 降维后的数据分布')
plt.show()
运行结果如下:

















 8278
8278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









