







python入门
高级语言–>机器语言
- 编译(c/c++):在执行之前会通过编译器执行
编译过程
- 效率一遍比解释性语言较高
- 解释(python):在程序运行时,通过解释器,一边运行一边解释
- 通过解释器优化,效率可提高,或超过编译性语言
注:java是一种先编译后解释的语言
gui编程:graphical user interface 图形用户界面:采用图形方式显示的一种信息交换媒介
基本语法
注释
解释器不执行注释内容
- 单行注释:#
- 多行注释:(块注释)
"""
注释1
注释2
...
"""
'''
注释1
注释2
...
'''
- 快捷键:ctrl +/ (将选中的行都已#注释掉) 再按ctrl+/取消
缩进
"""
同一逻辑下面的语句具有相同的缩进
"""
if a < b
a = b
print(a)
变量
变量名= 值
命名:
- 大驼峰 :每个单词首字母大写
- 小驼峰:第二个及以后的每个单词手写大写
- 下划线
- 变量名:满足标识符规则即可
+ 的使用
1.可以使用+字符将变量与另一个变量相加
x = "helllo"
y = "world"
print ("output is "+ x + y)
2.对于数字,+字符用作数学运算符
print(1+5) #6
global关键字
1.在函数内部创建全局变量时,使用global关键字
2.如果要在函数内部更改全局变量的值,使用global关键字引用该关键字
变量的赋值
- python中的变量赋值不需要类型声明(同shell脚本编程)
- <变量名> = <变量值>
- 允许为多个变量赋值
a = b = c =1
- 可以为多个变量同时指定变量值
a,b,c = 1,2.2,"sunshine"
- 变量更像是附在对象上的标签
# a == 标签 依赖于具体的空间
a = 100
a = 'strings'
b = 200
print(id(b))
b = 200
print(id(b))
a = 200
print(id(a))
a = 100
print(id(a))
result:
140720874558752
140720874558752
140720874558752 #不同变量的值相同,则都指向同一地址空间
140720874555552 #同一变量的不同值,指向不同的地址空间
数据类型
- 数值型(int 、float)
- 布尔型(True、False)
- 字符串(str)
- 列表(list)
- 元组(tuple)
- 集合(set)
- 字典(dict)
5个标准的数据类型
1. Number(数字类型):用于存储数值
- int : 是一个一个动态增长的类型,理论上可以无限增大
a = 0b10000 #二进制用0b表示
b = 0o23 #八进制用0o表示
c = 18 #十进制直接写
d = 0x12 #十六进制用0x表示
- float :类似于c的double
- conplex(复数):由实数部分和叙述部分组成
c = 1.0 + 2.3j #复数
数据类型强转—数字型
- 只需将数据类型作为函数名即可。如:
complex(x) #将x转换到一个复数,实数部分为x,虚数部分为0
complex(x,y) #将x和y转换到一个复数,x为实数部分,y为虚数部分
- 数学函数
abs()、 log() 、min()、....#同Matlab
- 随机数
choice(seq) : 从序列的元素中随机挑选一个元素,比如:
random.choice(10) #从0~9中随机挑选一个整数
randrange([start,]stop[,step]) : 从指定范围,按指定基数递增的集合中获取一个随机数, 计数值默认为1
seed([x]):改变随机数生成器的种子,不指定时,python会自动选择seed
shuffle(lst):将序列的所有元素随机排序
uniform(x,y):随机生成一个浮点数,范围在[x,y]内
randint(x,y):随机生成一个整数,它在[x,y]范围内
import random #加载random库
a = random.randint(1,5)
print(a)
2. String/bytes(字符串):是由数字、字母、下划线组成的遗传字符串,使用单引号或者双引号标
python语言由两种不同的字符串
- string:存储文本 ,文本字符串内部使用
unicode存储,范围更加广,利于操作 - bytes :存储原始字节,字节字符串存储原始字节并显示
ASCLL(0~255)
正常情况下,实例化一个字符串会得到一个str实例,如果希望得到byte实例,需要在文本前添加b字符利于传输字符串崩由中文,只能是ascll码的字母
text_str = "this is str" #str
byte_str = b"this is bytes"#bytes
1. string--->bytes 用encode() 便于传输
mystr = "我们"
print(mystr)
print(type(mystr))
mybytes = mystr.encode()#默认编码格式unicode
print(mybytes)
print(type(mybytes))
mybytes1 = mystr.encode("utf-8")#指定编码格式
print(mybytes)
print(type(mybytes))
result:
我们
<class 'str'>
b'\xe6\x88\x91\xe4\xbb\xac'
<class 'bytes'>
b'\xe6\x88\x91\xe4\xbb\xac'
<class 'bytes'>
bytes---->string用decode()便于操作
mybytes1 = b"hello world"
print(mybytes1)
print(type(mybytes1))
mystr1= mybytes1.decode("utf-8")
print(mystr1)
print(type(mystr1))
result:
b'hello world'
<class 'bytes'>
hello world
<class 'str'>
- 下标
如:str = “abcdef”
str = "abcdef"
print(str[0]) #a
print(str[1]) #b
print(str[2]) #c
...
print(str[5]) #f
- 切片:截取操作对象其中的一部分
语法:[起始:结束:步长]特点左闭右开
print(str[0:3]) #abc str[:3]
print(4:) #ef
print(1:-1) #bcde
print(str[-1]) #f 最后一个元素
- 查早字符串中某个字符对应的索引 find()/rfind()
str = "1234567891"
a = str.find("4") #4 find()从前往后找
b = str.rfind("1") #-1 refind()从后往前找
- 字符串函数
len:返回字符串的长度
find:检测一个字符串是否包含在另一个字符串中,如果是返回开始的索引值,否则返回-1
index:同find但是未检测到包含现象时会包异常
count:返回字符串在start和end之间在另一个字符串中出现的次数
replace:字符串替换
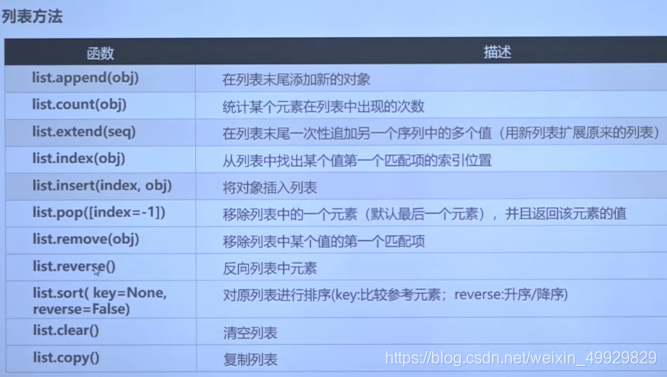
3. List(列表):有序的对象集合,通过偏移来取值
- 自定义格式:
列表名字 = [元素1,原素2,...];元素可以是字符、字符串、数字、列表等
- 元素获取:通过下标
mylist = [1,2.2,"hi",[22,33,44,"hello world"]]
print(mylist[0])
print(mylist[1])
print(mylist[2])
print(mylist[3])
print(mylist[3][2:5])
result:
1
2.2
hi
[22, 33, 44, 'hello world']
[44, 'hello world']
- 其他操作:
mylist = [1,2.2,"hi",[22,33,44,"hello world"]]
#在末尾追加
print(mylist+[55,66,["ni hao"]])#将各个元素都追加到原来的列表
mylist.append([55,66,["ni hao"]])#作为一个整体元素,追加到原来的列表
print(mylist)
result:
[1, 2.2, 'hi', [22, 33, 44, 'hello world'], 55, 66, ['ni hao']]
[1, 2.2, 'hi', [22, 33, 44, 'hello world'], [55, 66, ['ni hao']]]

可修改
4. Tuple(元组):类似于List(列表),用“()”标识,只读,不可变
不可修改
5. dictionary(字典):字典是无序的对象集合,由索引(key)和它对应的值value组成。用“{}”标识,通过键取值
- key可以是数字类型或者字符串类型;value的数据类型不限
- 有2种赋值方式:
mydit = {"name":"sunshine","age":18}#key:value
print(mydit)
mydit["name"] = "sunny" #通过key值修改value
print(mydit)
result:
{'name': 'sunshine', 'age': 18}
{'name': 'sunny', 'age': 18}
可修改
指定变量类型 Casting
- 面向对象的语言,使用类来定义数据类型
- 变量的数据类型——构造函数
- 使用构造函数完成数据类型的转换
输入输出
输入 input
原型:
input([prompt])
>prompt:提示信息
>>>num = input("请输入数据:")
print(type(num))
num1 = int (num)+333
print(num1)
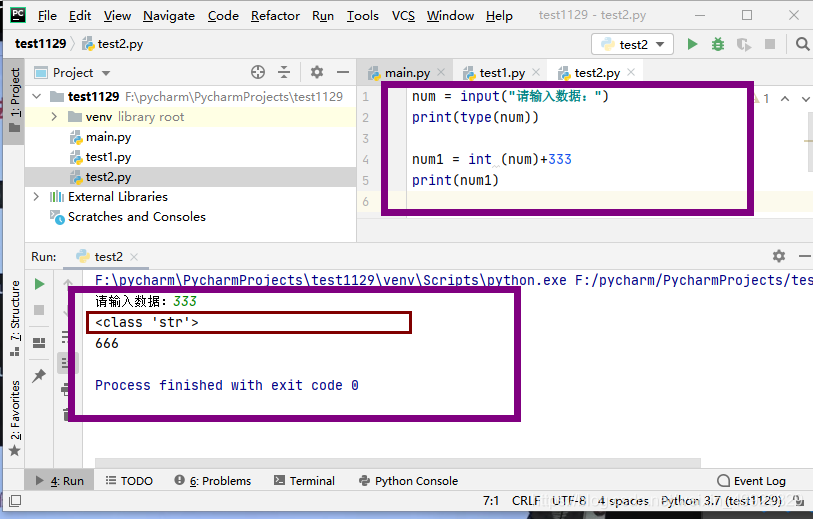
input接收任意性输入,将所有输入默认为字符串处理,并返回字符串类型,如需使用其他类型,需要自己显示做类型转换
在这里插入图片描述
input()接收用户输入的数据都是字符串类型
- 转换数据类型 函数 :类型(转换对象)
输出 print
原型:
print(*values,sep=' ',end='\n',file=sys.stdout,flush=False)
>values:表示要打印的值,各个值之间用‘,’(逗号),打印出来的各个值之间用空格隔开
>>>print('a','b','c')
a b c
>sep:表示当输出多个打印的值时,各个值之间分割方式,默认空格间隔,可以自定义
>end:控制print中传入值输出后的结束符号,默认换行,可以自设置,入“\t”、“ ”等
>file:设置输出对象,即把print中的值打印到什么地方,默认输出到终端,可以设置file=存储文件
>flush:该参数主要时刷新,默认False,关闭再刷新,Ture为实时刷新
h = 13
m = 20
s = 9
print(h,m,s,sep=":",end="\n")
print(h,':',m,":",s)
#今天时间是13:20:9,天气不错
print("今天时间是(",h,m,s,"),天气不错")
print("今天时间是(%d:%d:%d),天气不错"%(h,m,s))
name = "小明"
age = 18
print("%s,年龄%d"%(name,age))
print('{},年龄{}'.format(name,age))
#重复输出
print("{},年龄是{},{},爱好听歌".format(name,age,name))
print("{0},年龄是{1},{0},爱好是听歌".format(name,age))
```result```
13:20:9
13 : 20 : 9
今天时间是( 13 20 9 ),天气不错
今天时间是(13:20:9),天气不错
小明,年龄18
小明,年龄18
小明,年龄是18,小明,爱好听歌
小明,年龄是18,小明,爱好是听歌
- print(’’)默认会换行输出 等效于下面这个
- print(’’,end="\n")
1.格式化输出 :同c/c++ %c、%d、%s… 也可全部由%s代替,执行时会自动匹配相应类型
2.内置函数format() :字符串格式化
格式:str.format(),参数个数不限
3.转义字符
1)\n、\t:同c/c++
运算符
算术运算符
//:整除
*:乘--------------**:指数(2**3= 8)(优先级次于()小括号)
赋值运算符
1.单个变量赋值
2.多个变量赋值
number,float1,float2,str = 1,11.22,22.3,'strings'
3.多变量赋相同值
a = b = c =666
复合、比较运算符(类似)
逻辑运算符
and、or、not
- 特殊:数字之间的逻辑运算
- and运算符,只要有一个值为0,则结果为0,否则结果为最后一个非0数字
- or运算符,只有所有值为0结果才为0,否则结果为第一个非0数字
条件语句
- 逻辑判断
if a > b:
xxxxx
elif a < b:
xxxxxx
else:
xxxxxx
- 循环
while a > b
xxxxxx
break
for i in data:#将data里面的值一个一个的取出来,赋值给i,相当于字符串和数组的遍历
print(i)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









