






简介:
Scrapy是一个基于Python的开源异步爬虫框架,它被广泛用于从网页或App中,提取数据并将其保存到本地或数据库。由2.8版本以后提供了 http2.0协议的爬虫支持。
扩展:
scrapy是基于twisted框架开发而来,twisted是一个流行的事件驱动,使用了一种非阻塞(即异步)的代码实现并发,Scrapy之所以能实现异步,得益于twisted框架。
安装命令
# 安装命令
pip install scrapy
# 查看安装结果命令
scrapy --v显示一下版本页面表示安装成功
scrapy中文官网
一、Scrapy的五大核心组件
(1) 调度器(Scheduler)
用来接受引擎发过来的请求,并按照一定的方式进行整理排列,放到队列中,当引擎需要时,交还给引擎。可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址。
(2) 下载器(Downloader)
负责下载引擎发送的所有Request请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。Scrapy下载器是建立在twisted这个高效的异步模型上的。
(3) 爬虫(Spider)
用户根据自己的需求,编写程序,用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。跟进的URL提交给引擎,再次进入Scheduler(调度器)。
(4) 管道(Pipelines)
用于接收网络爬虫传过来的数据,以便做进一步处理。例如验证实体的有效性、清除不需要的信息、存入数据库(持久化实体)、存入文本文件等。
(5) 引擎(Engine)
框架核心,用来处理整个系统的数据流的流动, 触发事务(判断是何种数据流,然后再调用相应的方法)。也就是负责爬虫、管道、下载器、调度器中间的通讯,信号、数据传递等,所以被称为框架的核心。 引擎相当于计算机的CPU,它控制着整个流程。
二、Scrapy框架的工作原理如下:
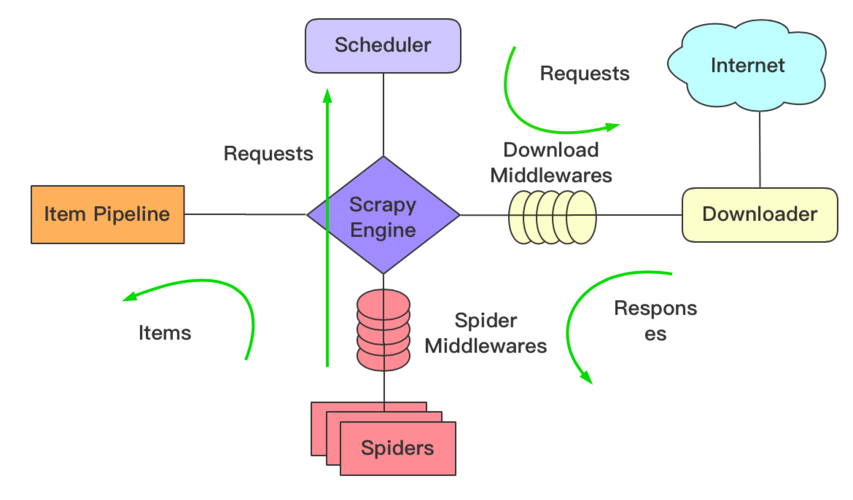
1.引擎会向spider索要url
2.引擎拿到url地址后会分发给调度器入队列,在调度器中会进行去重等处理
3.调度器会把整理好的url队列分发给下载器,进行下载数据,并把相应内容返回给spider。
下载器中间件,可以把他理解成是引擎与下载器中间的一个钩子(hook)插件,在这里我们可以修改和添加user-agent、代理ip、cookie、等等模拟浏览器环境行为来对抗各种反爬虫)还可以做异常的捕获与重试等...
4.spider拿到响应后,提取相应并生成item对象分发给管道进行持久化存储。
spider中间件,可以把他理解成是引擎与下载器中间的一个钩子(hook)插件,处理引擎传递给爬虫的响应或者处理爬虫传递给引擎的请求等。
例如,当运行到 yield scrapy.Request()或者 yield item 的时候,spider中间件会被触发。
5.pipelines管道拿到数据后可以持久化存储到数据库、表格等
三、创建scrapy框架
scrapy startproject BaiDu
cd BaiDu
scrapy genspider baidu www.baidu.com
















 64万+
64万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









