




由于最近做项目需要检测行人,包括检测红外光和可见光两种状态的行人,通过网上购买、爬虫等方式收集了大量的行人相关的数据集,数据集经过清洗和人工筛选,进而用于训练YOLO系列相关的检测模型。

1. 红外光人体数据集-——IR1
这是清洗了的红外数据集,其中包括3493个数据集,标签格式为YOLO格式,能够直接用于YOLO系列模型的训练,类别只有person一个类别。
数据集图片

数据集标签
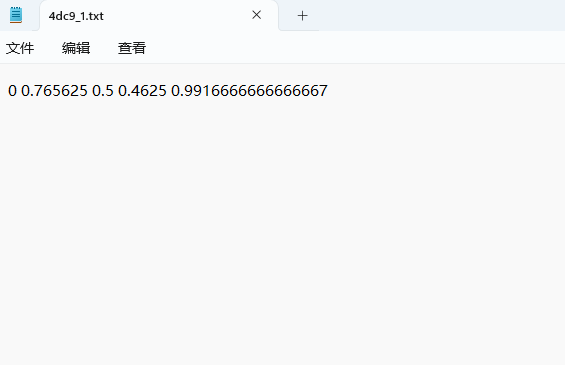
可视化标签

资源下载链接
2. 红外光人体数据集——IR2
清洗了的红外数据集,其中包括9045个数据集,数据集的标签格式为YOLO格式,能够直接用于YOLO系列模型的训练,只有person一个类别。
数据集图片

数据集标签
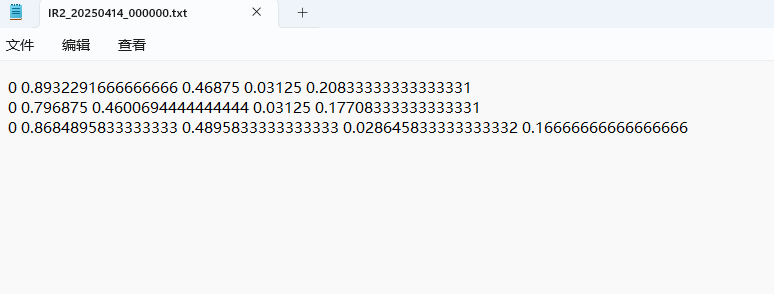
可视化标签

资源下载链接
3. 红外光人体数据集——IR3
红外行人数据集,其中包括14623个数据集,数据集的标签格式为YOLO格式,能够直接用于YOLO系列模型的训练,只有person一个类别。
数据集图片

数据集标签
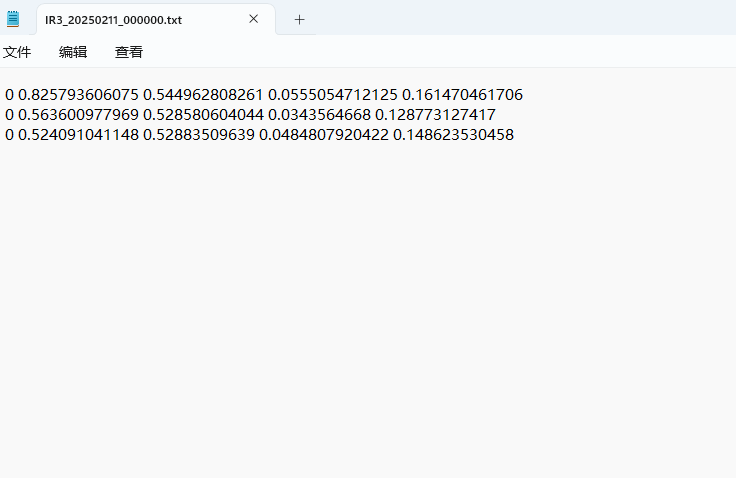
可视化标签
资源下载链接
图像资源:IR3红外光人体检测数据集-YOLO格式-图像数据(1/2)资源-优快云文库
IR3红外光人体检测数据集-YOLO格式-图像数据(2/2)资源-优快云文库
标签资源:IR3红外光人体检测数据集-YOLO格式-标签资源-优快云文库
可视化资源:IR3红外光人体检测数据集-YOLO格式-可视化标签图像数据(1/4)资源-优快云文库
IR3红外光人体检测数据集-YOLO格式-可视化标签图像数据(2/4)资源-优快云文库
IR3红外光人体检测数据集-YOLO格式-可视化标签图像数据(3/4)资源-优快云文库
IR3红外光人体检测数据集-YOLO格式-可视化标签图像数据(4/4)资源-优快云文库
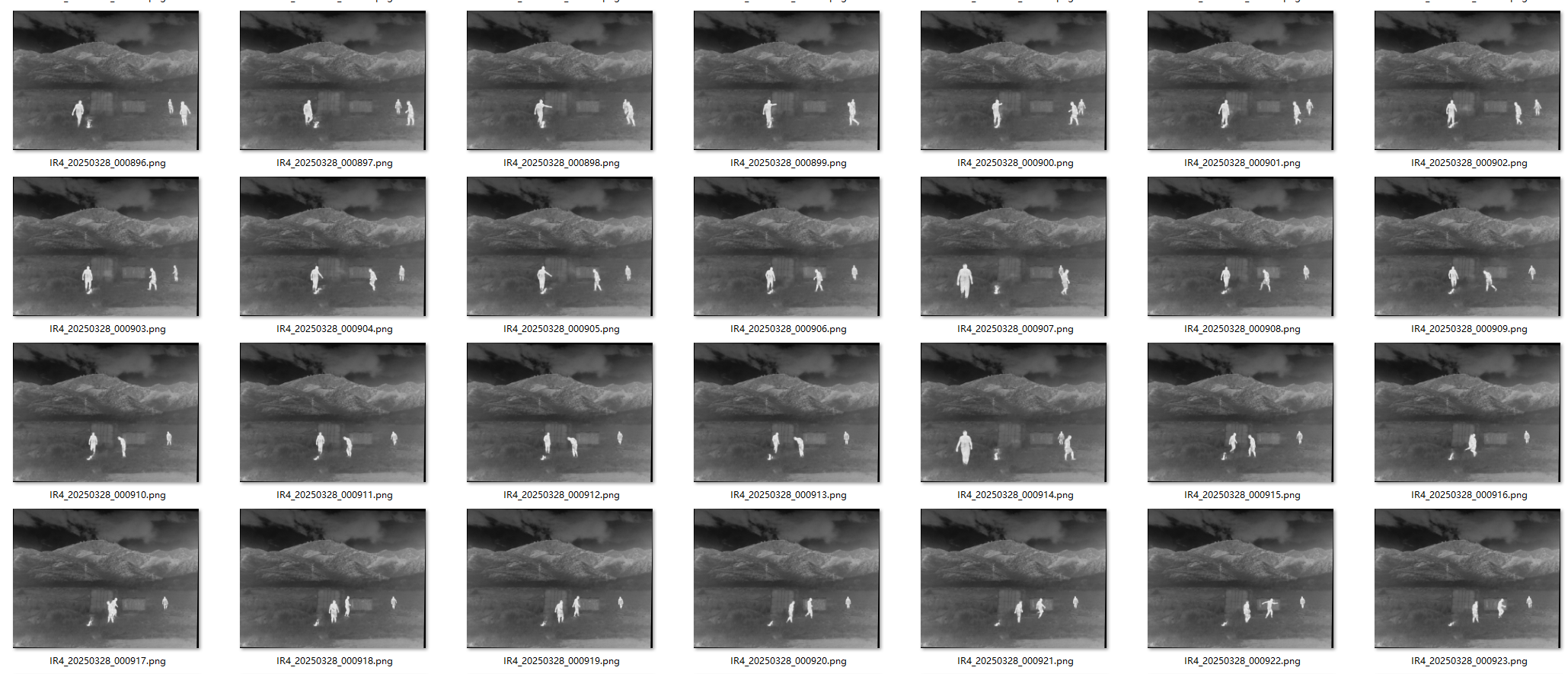
4. 红外光人体数据集——IR4
清洗后的红外行人数据集,其中包括2921个数据集,数据集的标签格式为YOLO格式,能够直接用于YOLO系列模型的训练,只有person一个类别。
数据集图片
数据集标签
可视化标签

资源下载链接
图像资源:IR4红外光人体检测数据集-YOLO格式-图像数据(1/2)资源-优快云文库
IR4红外光人体检测数据集-YOLO格式-图像数据(2/2)资源-优快云文库
标签资源:IR4红外光人体检测数据集-YOLO格式-数据标签资源-优快云文库
可视化资源:IR4红外光人体检测数据集-YOLO格式-可视化标签图像数据(2/2)资源-优快云文库
IR4红外光人体检测数据集-YOLO格式-可视化标签图像数据(2/2)资源-优快云文库
红外人体检测数据集不够解决方案
如果红外光的人体检测数据集不够,可以用以下的代码,可以把以下的可见光人体数据集转化为伪红外的人体检测数据集。相关的python代码如下:
import cv2
import numpy as np
import os
import tqdm
def rgb_to_pseudo_infrared(image):
# 将图像从BGR转换为HSV
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 提取亮度通道(V通道)
v_channel = hsv_image[:, :, 2]
# 归一化亮度通道到0-255
normalized_v = cv2.normalize(v_channel, None, 0, 255, cv2.NORM_MINMAX)
# 反转亮度通道以模拟红外效果
pseudo_infrared = 255 - normalized_v
return pseudo_infrared
if __name__ == '__main__':
# 需修改, RGB图像存放路径
dir_path = r'D:\DataSets\RGB_Body_Detection_Datasets\train2017_imgs'
# 需修改, 伪红外图像存放路径
save_path = r'D:\DataSets\Infrared_Body_Detection_Datasets\FAKE_INFRARED\IMAGES_COCO'
for file_name in tqdm.tqdm(os.listdir(dir_path)):
# 构造输入图像路径
input_image_path = os.path.join(dir_path, file_name)
# 读取输入的RGB图像
input_image = cv2.imread(input_image_path)
# 转换为伪红外灰度图
infrared_image = rgb_to_pseudo_infrared(input_image)
# 构造输出图像路径
output_image_path = os.path.join(save_path, file_name)
# 保存结果
cv2.imwrite(output_image_path, infrared_image)
print(f'{file_name} done!')代码解释:
将图像从BGR转换为HSV,提取亮度通道(V通道),归一化亮度通道到0-255,反转亮度通道以模拟红外效果,返回伪红外图像
转换效果如下:
原图:

转换后的效果:

5. 可见光人体检测数据集——Daimler行人数据集
数据集介绍
该数据库采用车载摄像机获取,分为检测和分类两个数据集。检测数据集的训练样本集有正样本大小为18×36和48×96的图片各15560(3915×4)张,行人的最小高度为72个象素;负样本6744张(大小为640×480或360×288)。测试集为一段27分钟左右的视频(分辨率为640×480),共21790张图片,包含56492个行人。分类数据库有三个训练集和两个测试集,每个数据集有4800张行人图片,5000张非行人图片,大小均为18×36,另外还有3个辅助的非行人图片集,各1200张图片。
数据集图片

资源下载链接
Daimler Mono Ped. Detection Benchmark
6. 可见光人体检测数据集——TUD行人数据集
数据集介绍
TUD行人数据库为评估运动信息在行人检测中的作用,提供图像对以便计算光流信息。训练集的正样本为1092对图像(图片大小为720×576,包含1776个行人);负样本为192对非行人图像(手持摄像机85对,车载摄像机107对);另外还提供26对车载摄像机拍摄的图像(包含183个行人)作为附加训练集。测试集有508对图像(图像对的时间间隔为1秒,分辨率为640×480),共有1326个行人。Andriluka等也构建了一个数据库用于验证他们提出的检测与跟踪相结合的行人检测技术。该数据集的训练集提供了行人的矩形框信息、分割掩膜及其各部位(脚、小腿、大腿、躯干和头部)的大小和位置信息。测试集为250张图片(包含311个完全可见的行人)用于测试检测器的性能,2个视频序列(TUD-Campus和TUD-Crossing)用于评估跟踪器的性能。
数据集图片

资源下载链接
Multi-Cue Onboard Pedestrian Detection - Max Planck Institute for Informatics
7. 可见光人体检测数据集——USC行人数据集
数据集介绍
该数据库包含三组数据集(USC-A、USC-B和USC-C),以XML格式提供标注信息。USC-A[Wu, 2005]的图片来自于网络,共205张图片,313个站立的行人,行人间不存在相互遮挡,拍摄角度为正面或者背面;USC-B的图片主要来自于CAVIAR视频库,包括各种视角的行人,行人之间有的相互遮挡,共54张图片,271个行人;USC-C有100张图片来自网络的图片,232个行人(多角度),行人之间无相互遮挡。
数据集图片
资源下载链接
USC Iris Computer Vision Lab – USC Institute of Robotics and Intelligent Systems
8. 可见光人体检测数据集——INRIA Person行人数据集
无法访问网站
数据集介绍
INRIA Person数据集是一个用于行人检测的人员图像数据集。它包含614张用于训练的人员检测图像和288张用于测试的图像。
数据集图片

资源下载链接
https://pascal.inrialpes.fr/data/human/
9. 人体检测数据集——MIT数据库
无法访问网站
数据集介绍
该数据库为较早公开的行人数据库,共924张行人图片(ppm格式,宽高为64×128),肩到脚的距离约80象素。该数据库只含正面和背面两个视角,无负样本,未区分训练集和测试集。Dalal等采用“HOG+SVM”,在该数据库上的检测准确率接近100%。
资源下载链接
http://cbcl.mit.edu/software-datasets/PedestrianData.html
博客资源说明
由于csdn上传限制,只能上传低于1000MB的资源,因此只能把数据文件拆分多个文件上传,下载完所有相关数据合并为一个文件即可。
相关代码工具
可视化YOLO标签链接
目标检测-可视化YOLO格式标签_yolo标签可视化-优快云博客
数据集划分链接
目标检测-数据划分(YOLO格式)_yolo数据集划分代码-优快云博客



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











