







 本文详细介绍了MySQL的增删改查操作,重点讲解了SQL查询的底层执行原理和各种查询分类,包括基础查询、过滤、排序、分组、连表、子查询和分页。此外,还探讨了如何避免笛卡尔集,以及左外连接的工作方式,并提供了相关案例。最后,概述了常用的字符、数字和日期函数。
本文详细介绍了MySQL的增删改查操作,重点讲解了SQL查询的底层执行原理和各种查询分类,包括基础查询、过滤、排序、分组、连表、子查询和分页。此外,还探讨了如何避免笛卡尔集,以及左外连接的工作方式,并提供了相关案例。最后,概述了常用的字符、数字和日期函数。
数据库
目录
前言:增加,修改,删除都是固定的SQL语句,重点在于查询!!!
1、增加,删除,修改
#增 语法:insert into 表名(列字段) values(?,?,?...)
#补充:
#什么时候需要声明表名后面的列字段?需要添加的数据字段<表的总字段 未添加的字段需要验证约束是否成立
#id如果是自增长,不用声明
#案列:添加一条学生数据到学生表,如果学生表有非空约束的班级cid字段,下面语句添加失败!!!
insert into tb_student(sname,sage,ssex) values('张三',17,'男')
#删 语法:delete from table where 条件
#案例:删除学生表中id为3的学生
delete from tb_table where id=3
#改 语法:update table set 字段=?,字段=? where 条件
#案列:将学生表中id为4的学生的姓名改为李四,年龄改为18
update tb_table set sname='李四',sage=18 where id=42、查询
1、SQL底层执行原理
首先是测试底层执行原理的两张表!tb_number,tb_word
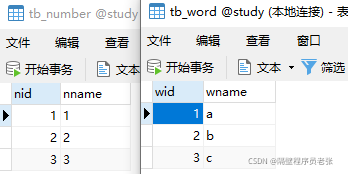
①执行select nname,wname from tb_word w,tb_number n查出来的数据
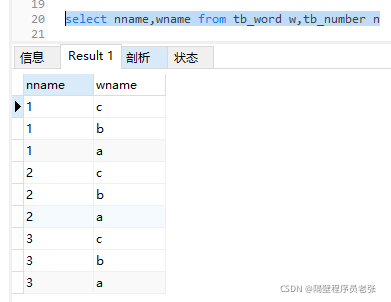
②执行select nname,wname from tb_number n,tb_word w查出来的数据
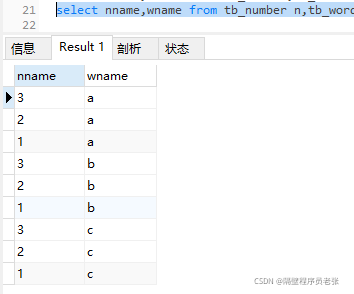
由①②可以推断出这个SQL语句执行时底层的原理
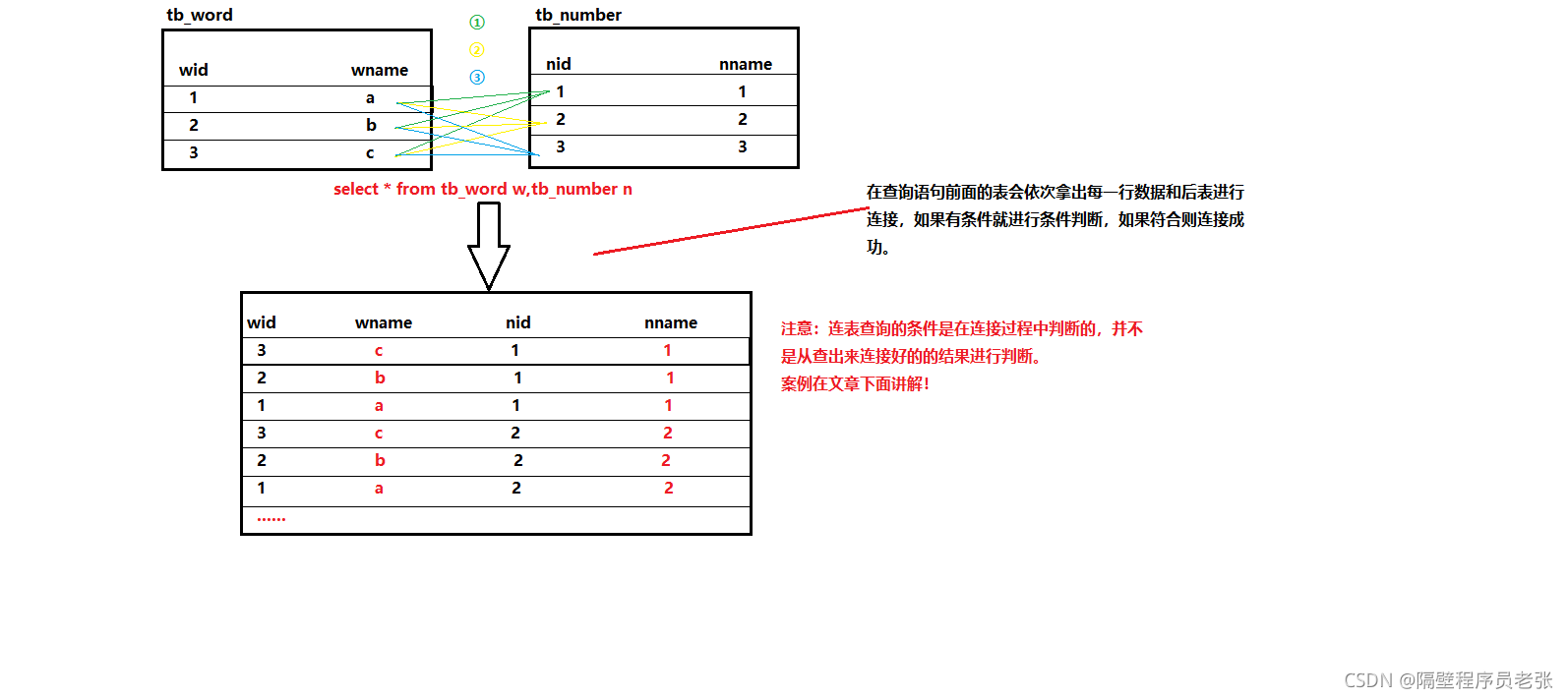
这是全连接的一个执行原理!!!左/右外连接原理和这不一样!
2、查询分类介绍
避免笛卡尔集
笛卡尔集会在下面条件下产生,笛卡尔集是在查询中需要避免的。
– 省略连接条件
– 连接条件无效
– 所有表中的所有行互相连接
• 为了避免笛卡尔集, 可以在 WHERE 加入有 效的连接条件。
按照上述SQL底层执行原理看,如果两张表分别有100条数据,不避免笛卡尔集会查询出
100*100=10000条数据,再进行数据获取,是非常影响速度的!!!
①基础查询
/*
语法:
select 查询列表 from 表名;
类似于:System.out.println(打印东西);
特点:
1、查询列表可以是:表中的字段、常量值、表达式、函数
2、查询的结果是一个虚拟的表格
*/
#3.查询表中的所有字段
#方式一:
SELECT
`employee_id`,
`first_name`,
`last_name`,
`phone_number`,
`last_name`,
`job_id`,
`phone_number`,
`job_id`,
`salary`,
`commission_pct`,
`manager_id`,
`department_id`,
`hiredate`
FROM
t_mysql_employees ;
#方式二:
SELECT * FROM t_mysql_employees;
#区别:
#方式一查询效率快
#4.查询常量值
SELECT 100;
SELECT 'john';
#5.查询表达式
SELECT 100%98;
#6.查询函数
SELECT VERSION();
#7.起别名
/*
①便于理解
②如果要查询的字段有重名的情况,使用别名可以区分开来
*/
#方式一:使用as
SELECT 100%98 AS 结果;
SELECT last_name AS 姓,first_name AS 名 FROM t_mysql_employees;
#方式二:使用空格
SELECT last_name 姓,first_name 名 FROM t_mysql_employees;
#8.去重
#案例:查询员工表中涉及到的所有的部门编号
SELECT DISTINCT department_id FROM t_mysql_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











