







1. 数据说明
这里只是为了学习,利用python爬取它的第1,2和3集danmu评论数据,具体的过程就不细述了,下面我们来细说,处理和分析《雪中悍刀行》的danmu评论。
2. 数据处理
首先,读取并采用concat方法合并各集danmu评论数据,同时,增加一列标签,以区两个合并后的数据来自哪一集。
import pandas as pd
df1 = pd.read_csv("./data/雪中悍刀行第1集弹幕.csv")
df1["集数"] = "1"
df2 = pd.read_csv("./data/雪中悍刀行第2集弹幕.csv")
df2["集数"] = "2"
df3 = pd.read_csv("./data/雪中悍刀行第3集弹幕.csv")
df3["集数"] = "3"
df = pd.concat([df1, df2, df3])
# 保存合并后的数据
df.to_csv("./data/雪中悍刀行第123集danmu.csv", encoding = "utf_8_sig", index=False)
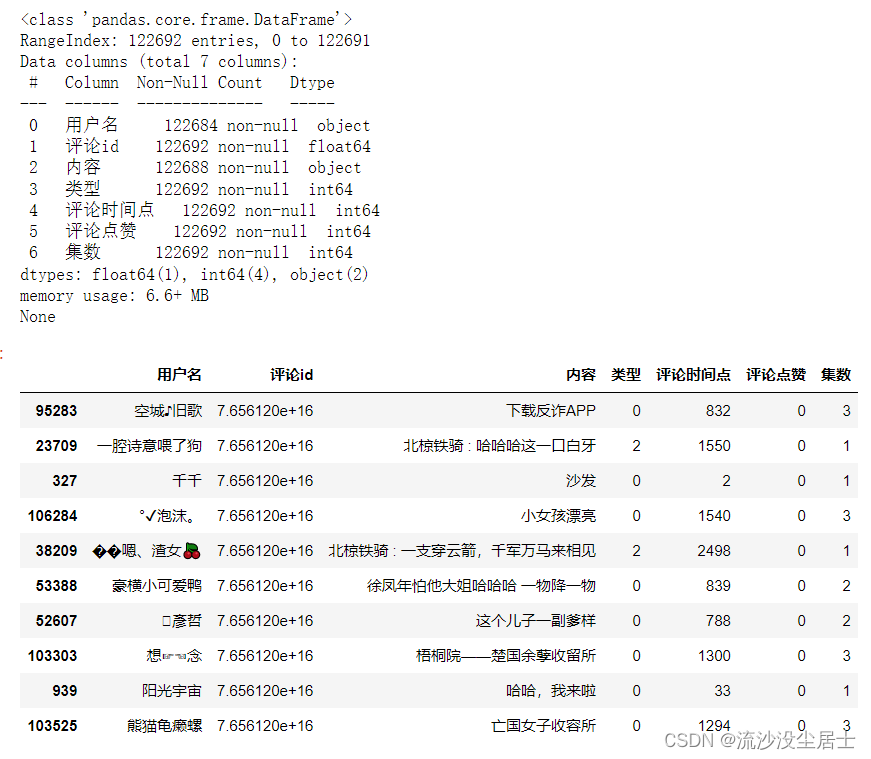
# 查看数据属性信息
print(df.info())
df.sample(10)
预览如下
2.1 查看各列整体是否有缺失值,重复值情况
# 查看一下各列整体的缺失值
df.isnull().sum(axis=0)
结果
用户名 8
评论id 0
内容 4
类型 0
评论时间点 0
评论点赞 0
集数 0
dtype: int64
# 再查看一下每一行数据是否存在重复值
df.duplicated().sum()
得到竟然有61373行数据是存在重复值。
通过上面,观察数据,发现数据存在以下几个问题:
字段名称可调整;用户名字列和内容列有缺失值,可删除;评论时间点字段类型需要调整;数据存在重复值删除。
# 重命名字段
df = df.rename(columns={'用户名':'用户昵称','内容':'弹幕内容','评论时间点':'发送时间','评论id':'弹幕id'})
删除重复数据。根据列的唯一性,可以把它作为作为参照,如存在多行相同,那么只保留最开始出现的一行。
df.drop_duplicates(subset=['弹幕内容','发送时间'], keep='first', inplace=True)
# 重置索引
df.reset_index(drop=True, inplace=True)
df.shape
缺失值处理
df.dropna(how = 'all') #只删除全是缺失值的行
发送时间处理
# 发送时间列单位是秒数,这里自定义一个time_change函数进行处理
def time_change(seconds):
m, s = divmod(seconds, 60)
h, m = divmod(m, 60)
ss_time = "%d:%02d:%02d" % (h,m, s)
print(ss_time)
return ss_time
time_change(seconds=6666)
# 将time_change函数用于发送时间列
df["发送时间"] = df["发送时间"].apply(time_change)
设置为需要的时间格式
df['发送时间'] = pd.to_datetime(df['发送时间'])
df['发送时间'] = df['发送时间'].apply(lambda x: x.strftime('%H:%M:%S'))
2.2 danmu评论去重处理
这里的danmu评论内容去重,使用机械压缩去重方法:机械压缩去重即数据句内的去重,我们发现弹幕内容存在,例如:"你你你们也来学习学习真的真的很好很好"这种数据,而实际做情感分析时,只需要一个“你们也来学习真的很好”即可。
# 机械压缩去重:自定义机械压缩函数
def yasuo(st):
for i in range(1,int(len(st)/2)+1):
for j in range(len(st)):
if st[j:j+i] == st[j+i:j+2*i]:
k = j + i
while st[k:k+i] == st[k+i:k+2*i] and k<len(st):
k = k + i
st = st[:j] + st[k:]
return st
print(yasuo(st="你你你们也来学习学习真的真的很好很好"))
# out:'你们也来学习真的很好'
# 调用机械压缩函数,对弹幕内容进行句子进行去重
df["弹幕内容"] = df["弹幕内容"].apply(yasuo)
2.3 特殊字符过滤
特殊字符直接利用正则表达式过滤,只保留中文内容。
# 提取中文内容
df['弹幕内容'] = df['弹幕内容'].str.extract(r"([\u4e00-\u9fa5]+)")
df = df.dropna() #纯表情直接删除
同时,过短的danmu评论内容一般很难看出情感倾向,这里过滤掉评论字数少于2个字的评论。
df = df[df["弹幕内容"].apply(len)>=2]
df = df.dropna()
# 保存清洗后的数据
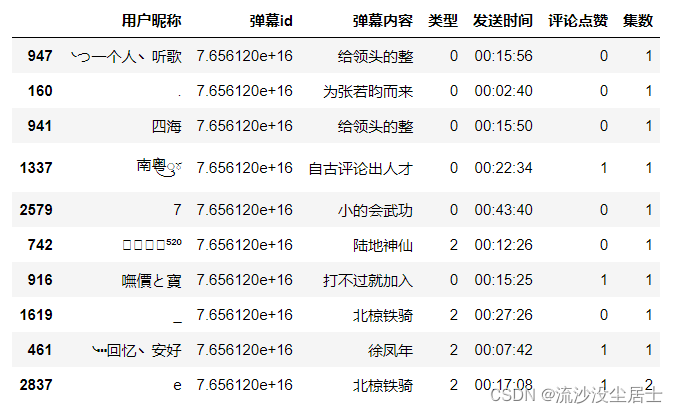
df.to_csv("./data/清洗后_雪中悍刀行第123集danmu.csv",encoding="utf-8",index=False)
# 清洗后数据,如下所示
df.sample(10)
3. 简单可视化分析
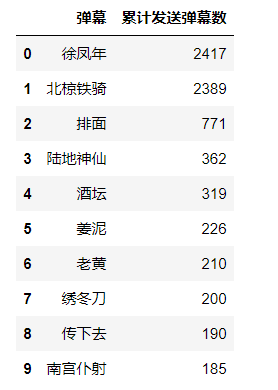
3.1 danmu评论发送量 Top10
# 幕发送量Top10榜单
danmu_counts = df.groupby('弹幕内容')['弹幕id'].count().sort_values(ascending= False).reset_index()
danmu_counts.columns = ['弹幕','累计发送弹幕数']
danmu_counts.head(10)
可视化更直观地看:
from pyecharts.charts import *
import pyecharts.options as opts
from pyecharts.globals import ThemeType
danmu_counts = df['弹幕内容'].value_counts()[:10].sort_values()
x_data = danmu_counts.index.tolist()
y_data = danmu_counts.values.tolist()
b = (Bar()
.add_xaxis(x_data)
.add_yaxis('',y_data)
.set_global_opts(title_opts = opts.TitleOpts(title='累计发送弹幕发送量Top10句子'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
.reversal_axis()
)
b.render_notebook()
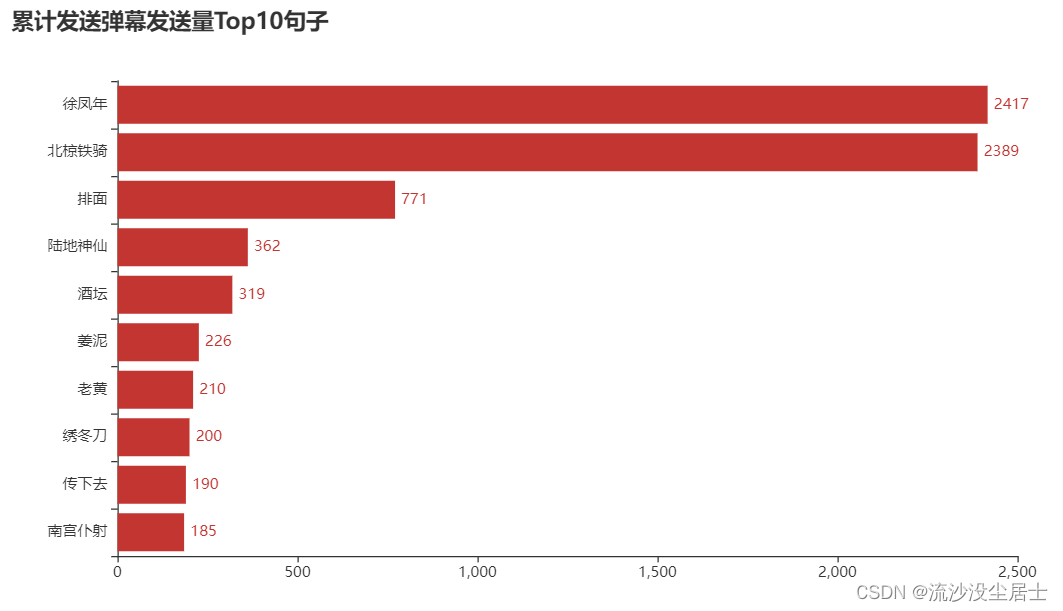
可以看到第一,‘徐凤年’ 2417次,第二,‘北椋铁骑’2389次。这两个词遥遥领先。
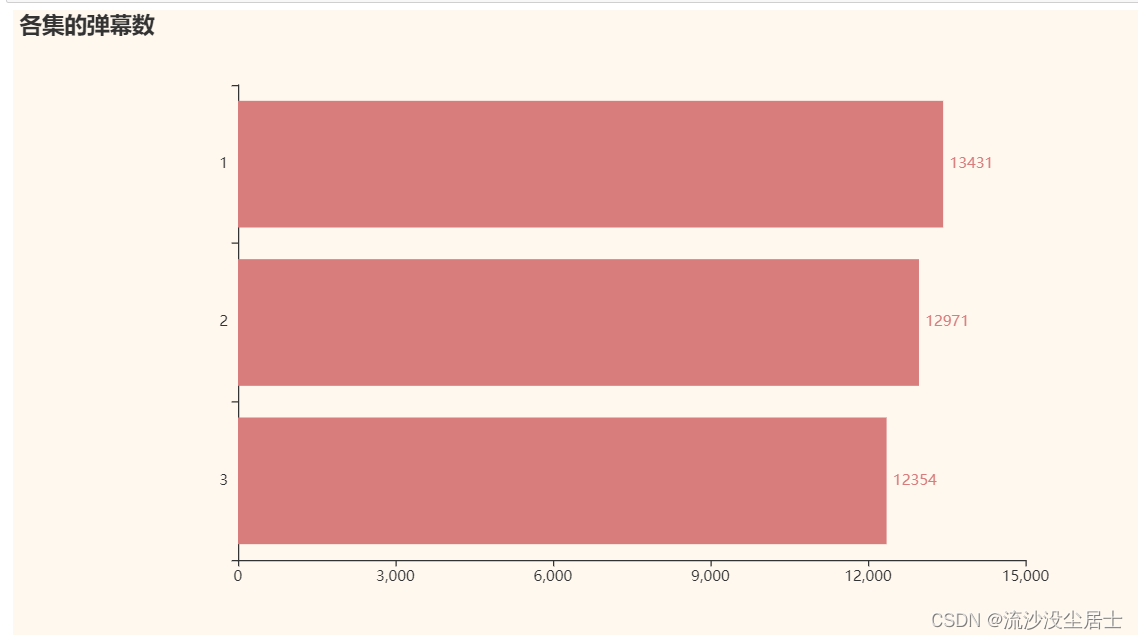
3.2 各集danmu评论数量对比
lt = df['集数'].value_counts().sort_values()
x_data = lt.index.tolist()
y_data = lt.values.tolist()
b = (Bar()
.add_xaxis(x_data)
.add_yaxis('',y_data)
.set_global_opts(title_opts = opts.TitleOpts(title='各集的弹幕数'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
.reversal_axis()
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()
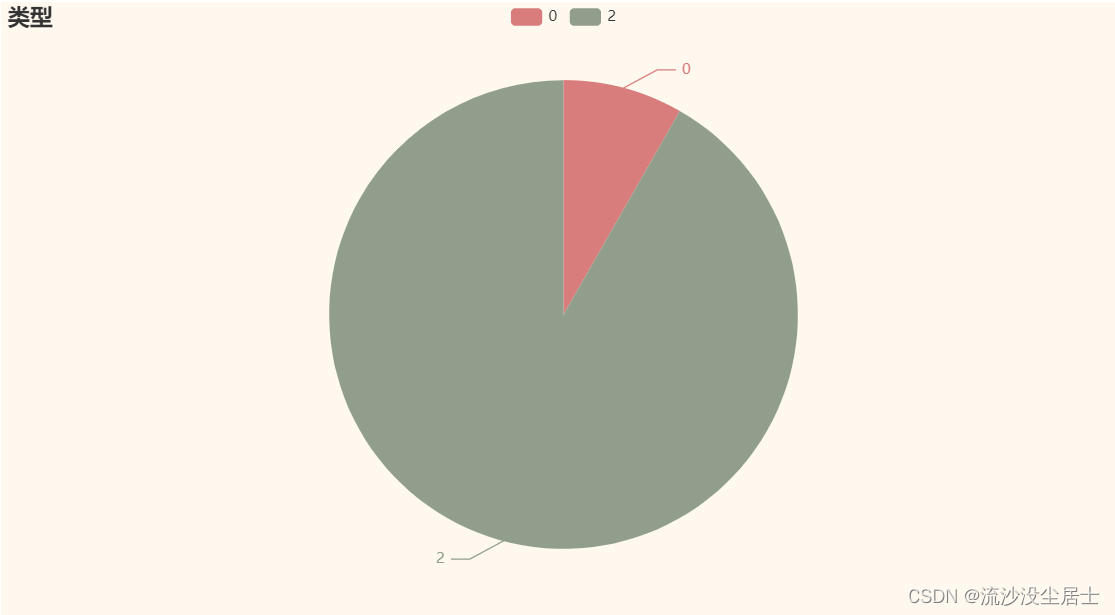
3.3 danmu评论的类型
rt = df["类型"].value_counts()[:10].sort_values().tolist()
print(rt)
b = (Pie()
.add("", [list(z) for z in zip(["0", "2"], rt)])
.set_global_opts(title_opts = opts.TitleOpts(title='类型'))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True,position='right'))
)
grid = Grid(init_opts=opts.InitOpts(theme=ThemeType.VINTAGE))
grid.add(b, grid_opts=opts.GridOpts(pos_left="20%"))
grid.render_notebook()
3.4 谁是danmu评论王
df5 = df["用户昵称"].value_counts()[0:10]
df5 = df5.sort_values(ascending=True)
df5 = df5.tail(10)
print(df5.index.to_list())
print(df5.to_list())
c = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(df5.index.to_list())
.add_yaxis("",df5.to_list()).reversal_axis() #X轴与y轴调换顺序
.set_global_opts(title_opts=opts.TitleOpts(title="弹幕用户TOP10",subtitle="数据来源:腾讯视频",pos_left = 'left'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改横坐标字体大小
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=13)), #更改纵坐标字体大小
)
.set_series_opts(label_opts=opts.LabelOpts(font_size=16,position='right'))
)
c.render_notebook()
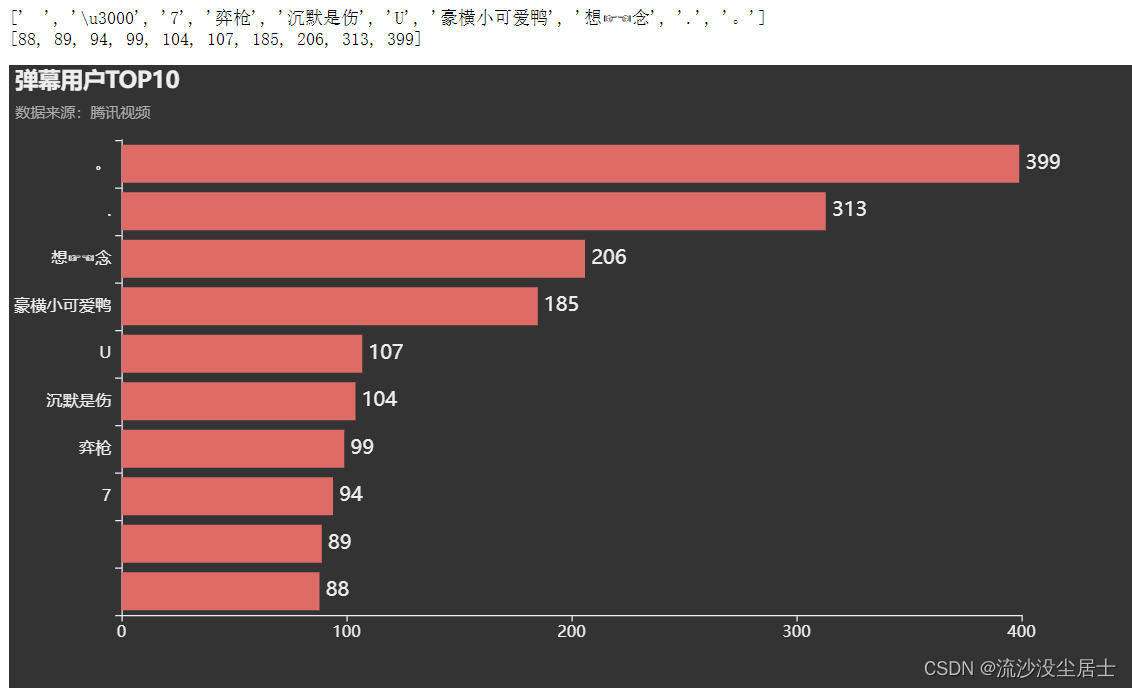
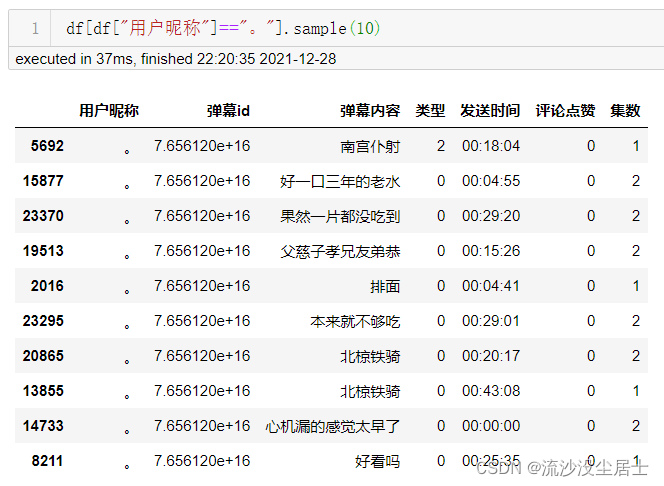
用户昵称是*。* 的观众的danmu评论数量最多,其次是*.*用户昵称的观众。下面随机抽取10条数据,看看第一用户发了什么弹幕。
3.5 danmu评论都在说什么
import jieba
import stylecloud
import matplotlib.pyplot as plt
from IPython.display import Image
# 定义分词函数
def get_cut_words(content_series):
# 读入停用词表
stop_words = []
with open("./stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 可添加关键词
my_words = ['']
for i in my_words:
jieba.add_word(i)
# 可自定义停用词
my_stop_words = ['']
stop_words.extend(my_stop_words)
# 分词
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
# 绘制词云图
text1 = get_cut_words(content_series=df['弹幕内容'])
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=300,
collocations=False,
font_path='STXINWEI.TTF',
icon_name='fas fa-square',
size=653,
output_name='./雪中悍刀行.png')
Image(filename='./雪中悍刀行.png')

通过danmu评论词云图,我们发现,出现概率最大的弹幕有“北椋铁骑、徐凤年、排面、姜泥、公主、老黄和可爱”等。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









