






Canal的介绍
Canal是基于Mysql二进制的高性能数据同步系统,Canal在阿里巴巴集团中被广泛使用,以提供可靠的低延迟增量数据管道(白话文:其实就是根据mysql的biglog日志,进行增量同步数据)
Canal的背景
早期,阿里巴巴B2B公司需要在美国和中国杭州之间同步服务器的数据。先前的数据库同步机制是基于trigger以获得增量更新的。从2010年开始,阿里巴巴集团开始使用数据集二进制日志获取增量更新并跨服务器同步数据,这催生了我们的增量订阅和使用服务(现已在阿里云中提供)并开始了一个新时代。
Mysql主从复制原理
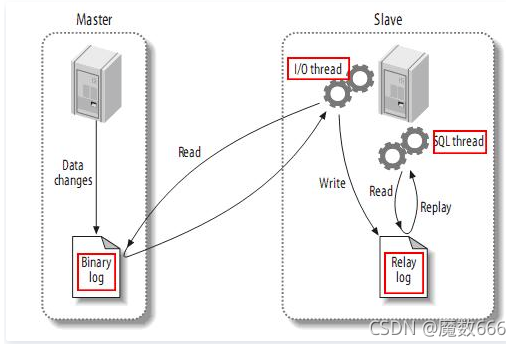
- Slave 上面的IO线程连接上 Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
- Master 接收到来自 Slave 的 IO 线程的请求后,通过负责复制的 IO 线程根据请求信息读取指定日志指定位置之后的日志信息,返回给 Slave 端的 IO 线程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息在 Master 端的 Binary Log 文件的名称以及在 Binary Log 中的位置;
- Slave 的 IO 线程接收到信息后,将接收到的日志内容依次写入到 Slave 端的Relay Log文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的Master端的bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的高速Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”
- Slave 的 SQL 线程检测到 Relay Log 中新增加了内容后,会马上解析该 Log 文件中的内容成为在 Master 端真实执行时候的那些可执行的 Query语句,并在自身执行这些 Query。这样,实际上就是在 Master 端和 Slave 端执行了同样的 Query,所以两端的数据是完全一样的。当然这个过程本质上还是存在一定的延迟的。
mysql的binlog
它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间。主要用来备份和数据同步。
binlog 有三种模式:STATEMENT、ROW、MIXED
- STATEMENT 记录的是执行的sql语句
- ROW 记录的是真实的行数据记录
- MIXED 记录的是1+2,优先按照1的模式记录
举例来说,下面的sql:
update user set age=20
对应STATEMENT模式只有一条记录,对应ROW模式则有可能有成千上万条记录(取决数据库中的记录数)。
canal 工作原理
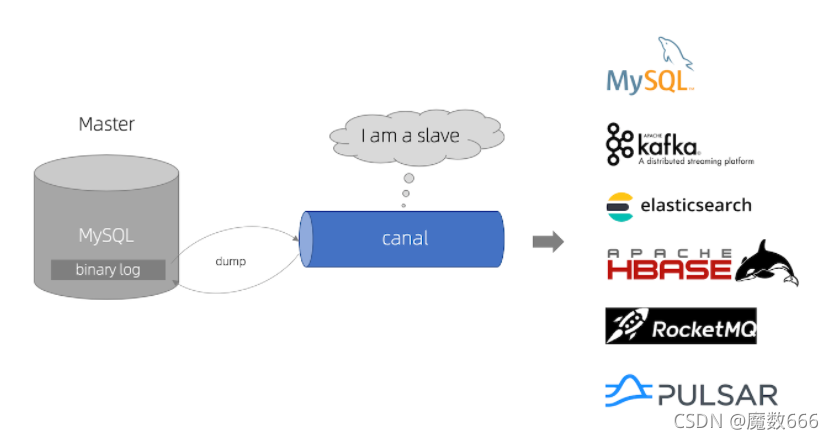
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
canal 的架构
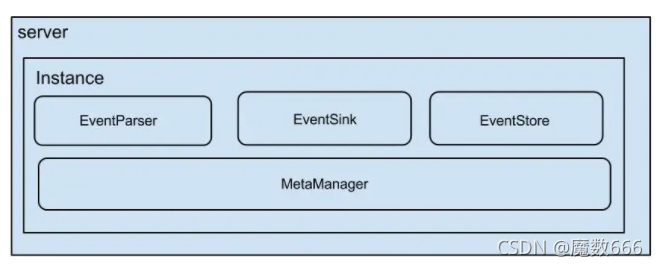
说明:
- server代表一个canal运行实例,对应于一个jvm
- instance对应于一个数据队列 (1个server对应1…n个instance)
instance模块:
- eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)
- eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)
- eventStore (数据存储)
- metaManager (增量订阅&消费信息管理器)
-
EventParser设计
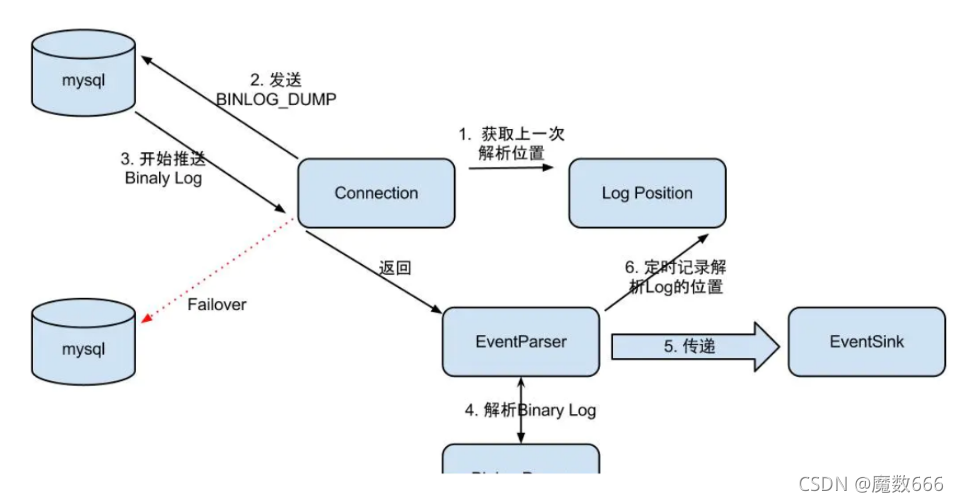
整个parser过程大致可分为几步:
- Connection获取上一次解析成功的位置 (如果第一次启动,则获取初始指定的位置或者是当前数据库的binlog位点)
- Connection建立链接,发送BINLOG_DUMP指令
0. write command number- write 4 bytes bin-log position to start at
- write 2 bytes bin-log flags
- write 4 bytes server id of the slave
- write bin-log file name
- Mysql开始推送Binaly Log
- 接收到的Binaly Log的通过Binlog parser进行协议解析,补充一些特定信息
// 补充字段名字,字段类型,主键信息,unsigned类型处理 - 传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功
- 存储成功后,定时记录Binaly Log位置
EventSink设计
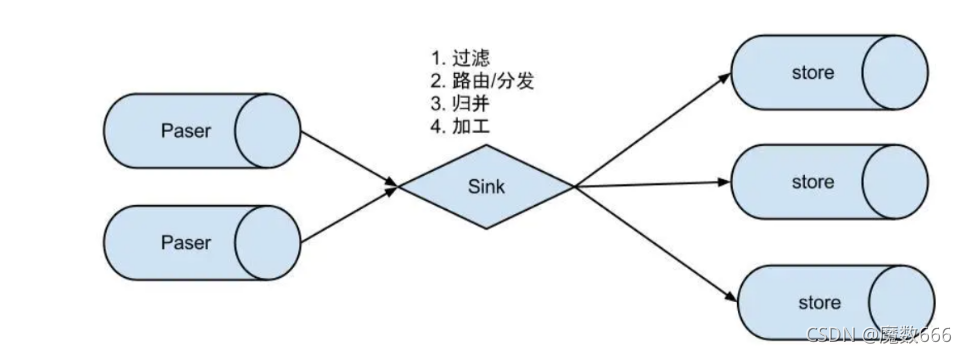
- 数据过滤:支持通配符的过滤模式,表名,字段内容等
- 数据路由/分发:解决1:n (1个parser对应多个store的模式)
- 数据归并:解决n:1 (多个parser对应1个store)
- 数据加工:在进入store之前进行额外的处理,比如join
EventStore设计
- 1.目前仅实现了Memory内存模式,后续计划增加本地file存储,mixed混合模式
- 2.借鉴了Disruptor的RingBuffer的实现思路
RingBuffer设计:
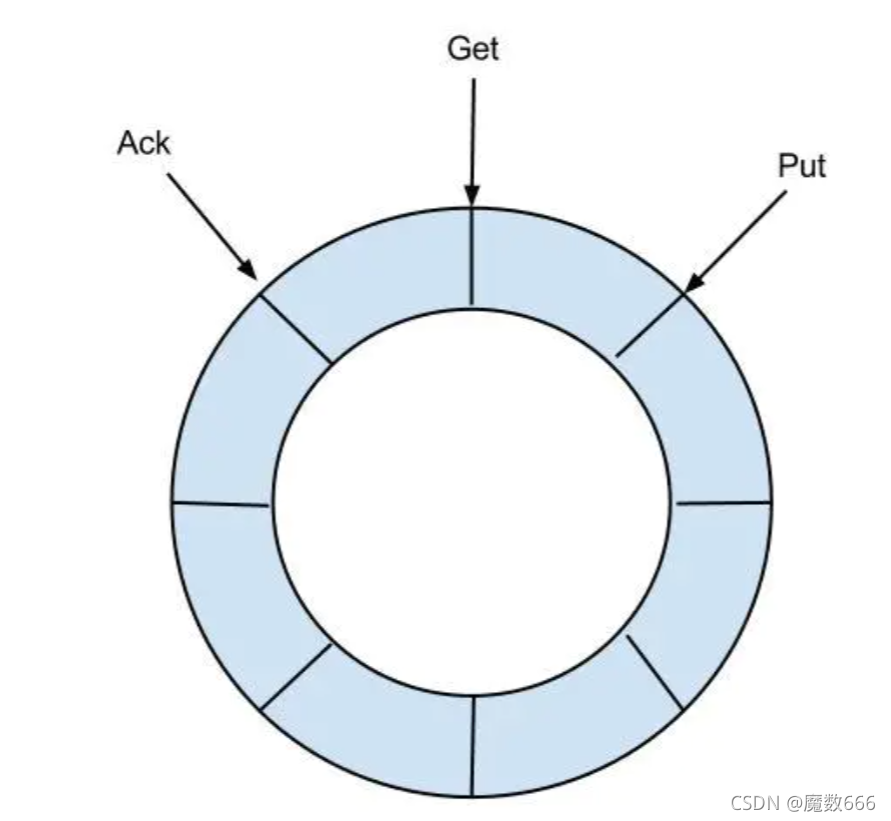
定义了3个cursor
- Put : Sink模块进行数据存储的最后一次写入位置
- Get : 数据订阅获取的最后一次提取位置
- Ack : 数据消费成功的最后一次消费位置
借鉴Disruptor的RingBuffer的实现,将RingBuffer拉直来看:
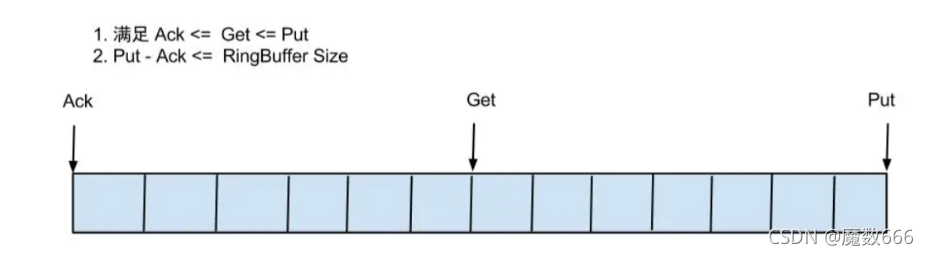
实现说明:
- Put/Get/Ack cursor用于递增,采用long型存储
- buffer的get操作,通过取余或者与操作。(与操作: cusor & (size - 1) , size需要为2的指数,效率比较高)
Instance设计
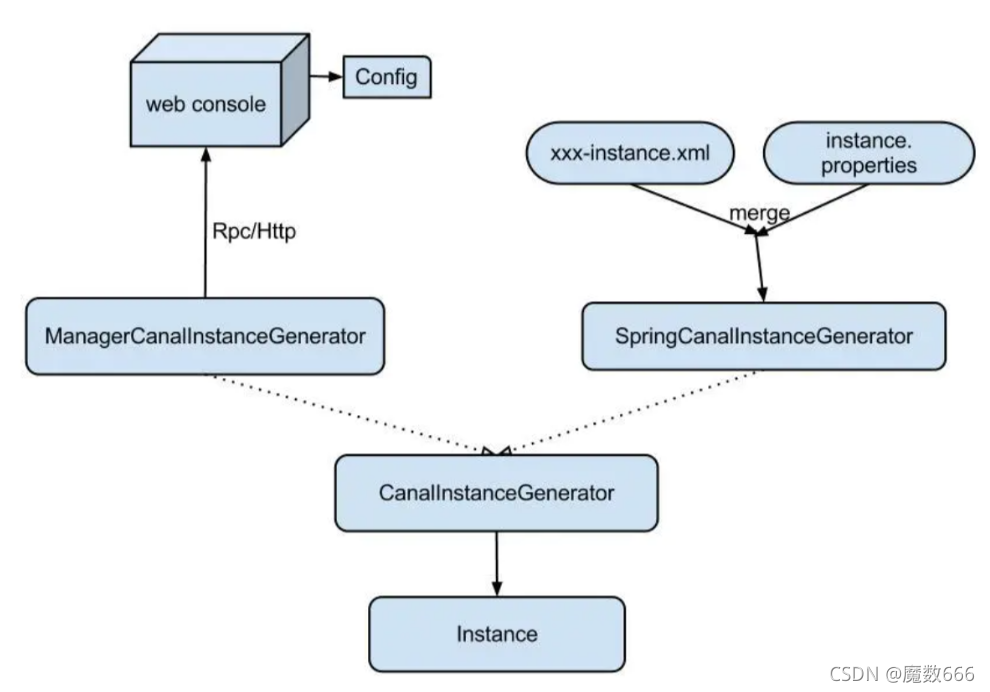
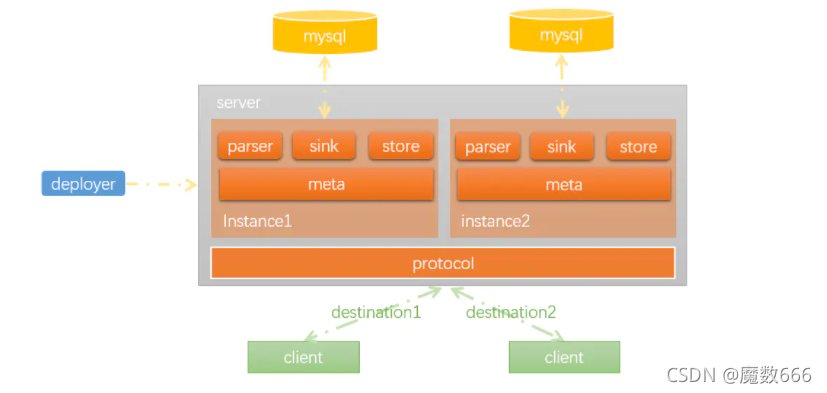
instance代表了一个实际运行的数据队列,包括了EventPaser,EventSink,EventStore等组件。
抽象了CanalInstanceGenerator,主要是考虑配置的管理方式:
- manager方式: 和你自己的内部web console/manager系统进行对接。(目前主要是公司内部使用)
- spring方式:基于spring xml + properties进行定义,构建spring配置.
Server设计
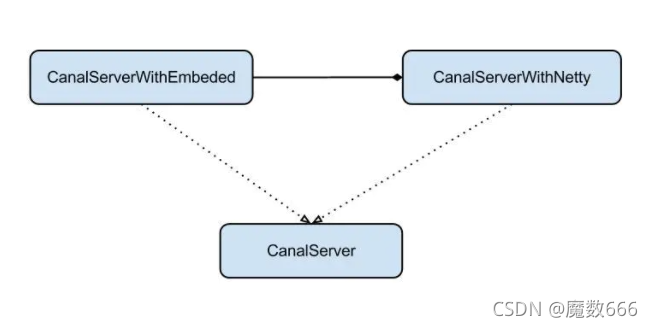
server代表了一个canal的运行实例,为了方便组件化使用,特意抽象了Embeded(嵌入式) / Netty(网络访问)的两种实现
- Embeded : 对latency和可用性都有比较高的要求,自己又能hold住分布式的相关技术(比如failover)
- Netty : 基于netty封装了一层网络协议,由canal server保证其可用性,采用的pull模型,当然latency会稍微打点折扣,不过这个也视情况而定。(阿里系的notify和metaq,典型的push/pull模型,目前也逐步的在向pull模型靠拢,push在数据量大的时候会有一些问题)
增量订阅/消费设计
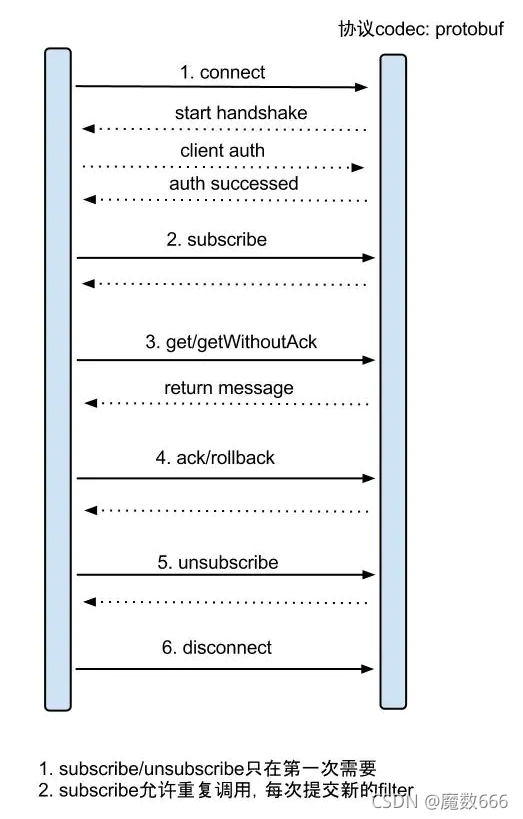
get/ack/rollback协议介绍:
- Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:
a. batch id 唯一标识
b. entries 具体的数据对象,对应的数据对象格式:EntryProtocol.proto - void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
- void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
canal的get/ack/rollback协议和常规的jms协议有所不同,允许get/ack异步处理,比如可以连续调用get多次,后续异步按顺序提交ack/rollback,项目中称之为流式api.
流式api设计的好处:
-
get/ack异步化,减少因ack带来的网络延迟和操作成本 (99%的状态都是处于正常状态,异常的rollback属于个别情况,没必要为个别的case牺牲整个性能)
-
get获取数据后,业务消费存在瓶颈或者需要多进程/多线程消费时,可以不停的轮询get数据,不停的往后发送任务,提高并行化. (作者在实际业务中的一个case:业务数据消费需要跨中美网络,所以一次操作基本在200ms以上,为了减少延迟,所以需要实施并行化)
流式api设计:
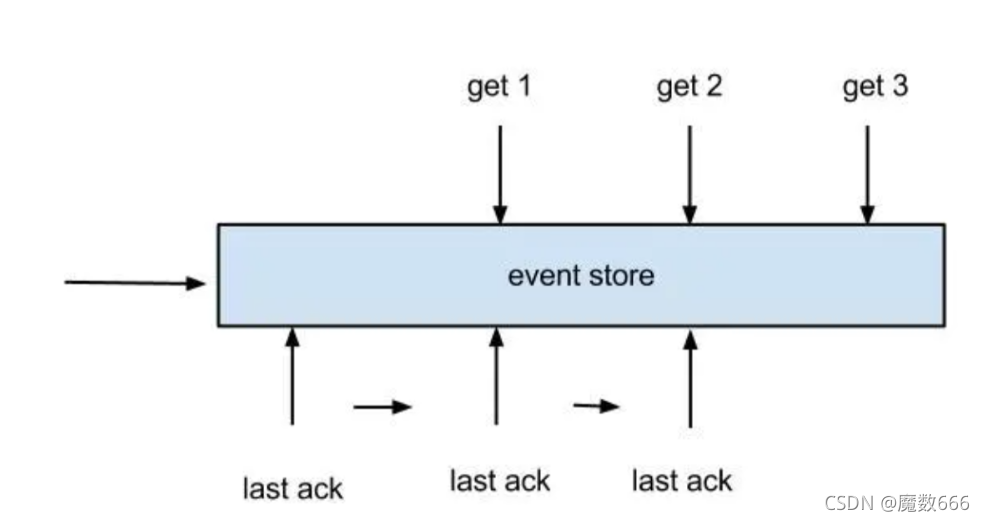
-
每次get操作都会在meta中产生一个mark,mark标记会递增,保证运行过程中mark的唯一性
-
每次的get操作,都会在上一次的mark操作记录的cursor继续往后取,如果mark不存在,则在last ack cursor继续往后取
-
进行ack时,需要按照mark的顺序进行数序ack,不能跳跃ack. ack会删除当前的mark标记,并将对应的mark位置更新为last ack cusor
-
一旦出现异常情况,客户端可发起rollback情况,重新置位:删除所有的mark, 清理get请求位置,下次请求会从last ack cursor继续往后取
数据对象格式: EntryProtocol.proto
Entry
Header
logfileName [binlog文件名]
logfileOffset [binlog position]
executeTime [binlog里记录变更发生的时间戳]
schemaName [数据库实例]
tableName [表名]
eventType [insert/update/delete类型]
entryType [事务头BEGIN/事务尾END/数据ROWDATA]
storeValue [byte数据,可展开,对应的类型为RowChange]
RowChange
isDdl [是否是ddl变更操作,比如create table/drop table]
sql [具体的ddl sql]
rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]
beforeColumns [Column类型的数组]
afterColumns [Column类型的数组]
Column
index [column序号]
sqlType [jdbc type]
name [column name]
isKey [是否为主键]
updated [是否发生过变更]
isNull [值是否为null]
value [具体的内容,注意为文本]
说明:
- 可以提供数据库变更前和变更后的字段内容,针对binlog中没有的name,isKey等信息进行补全
- 可以提供ddl的变更语句
HA机制设计
canal的ha分为两部分,canal server和canal client分别有对应的ha实现
- canal server: 为了减少对mysql dump的请求,不同server上的instance要求同一时间只能有一个处于running,其他的处于standby状态.
- canal client: 为了保证有序性,一份instance同一时间只能由一个canal client进行get/ack/rollback操作,否则客户端接收无法保证有序。
整个HA机制的控制主要是依赖了zookeeper的几个特性,watcher和EPHEMERAL节点(和session生命周期绑定)
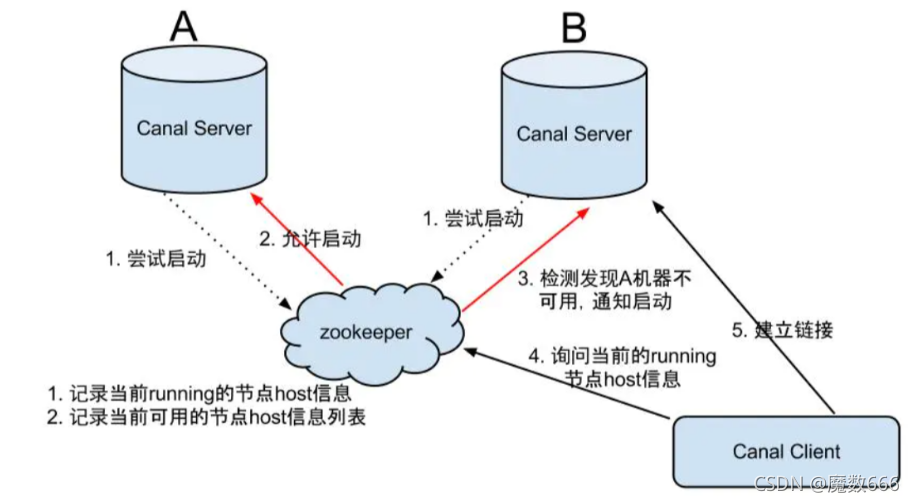
大致步骤:
- canal server要启动某个canal instance时都先向zookeeper进行一次尝试启动判断 (实现:创建EPHEMERAL节点,谁创建成功就允许谁启动)
- 创建zookeeper节点成功后,对应的canal server就启动对应的canal instance,没有创建成功的canal instance就会处于standby状态
- 一旦zookeeper发现canal server A创建的节点消失后,立即通知其他的canal server再次进行步骤1的操作,重新选出一个canal server启动instance.
- canal client每次进行connect时,会首先向zookeeper询问当前是谁启动了canal instance,然后和其建立链接,一旦链接不可用,会重新尝试connect.

















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









