







 文章探讨了面对海量数据存储的问题,提出了从单机纵向扩展到多机横向扩展的解决方案,尤其是分布式存储。通过元数据记录来加速文件查询,使用分块存储提升大文件传输效率,并通过冗余存储和副本机制确保数据安全性。同时,通过目录树结构统一用户查询视角,保持与传统文件系统的操作体验一致。
文章探讨了面对海量数据存储的问题,提出了从单机纵向扩展到多机横向扩展的解决方案,尤其是分布式存储。通过元数据记录来加速文件查询,使用分块存储提升大文件传输效率,并通过冗余存储和副本机制确保数据安全性。同时,通过目录树结构统一用户查询视角,保持与传统文件系统的操作体验一致。
如何解决海量数据存不下的问题
传统做法是是在宕机存储。但随着数据变多,会遇到存储瓶颈
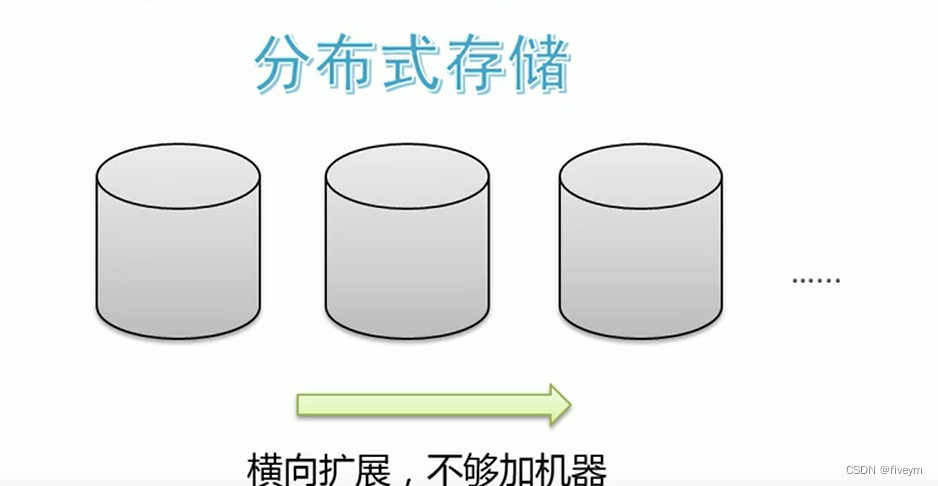
单机纵向扩展:内存不够加内存,磁盘不够家磁盘。有上限限制,不能无限制加下去
多机横向扩展:采用多台机器存储,一台不够就加机器。理论上可以无线
多台机器存储也就意味迈入了分布式存储
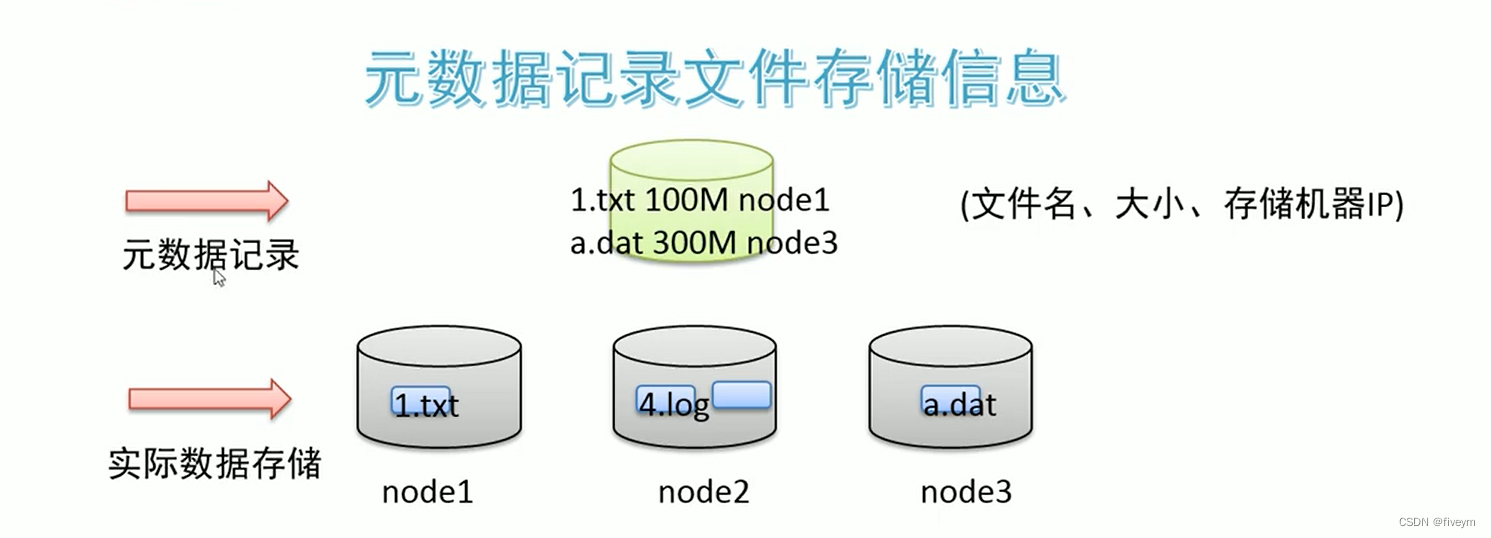
如何解决海量数据文件查询便捷问题
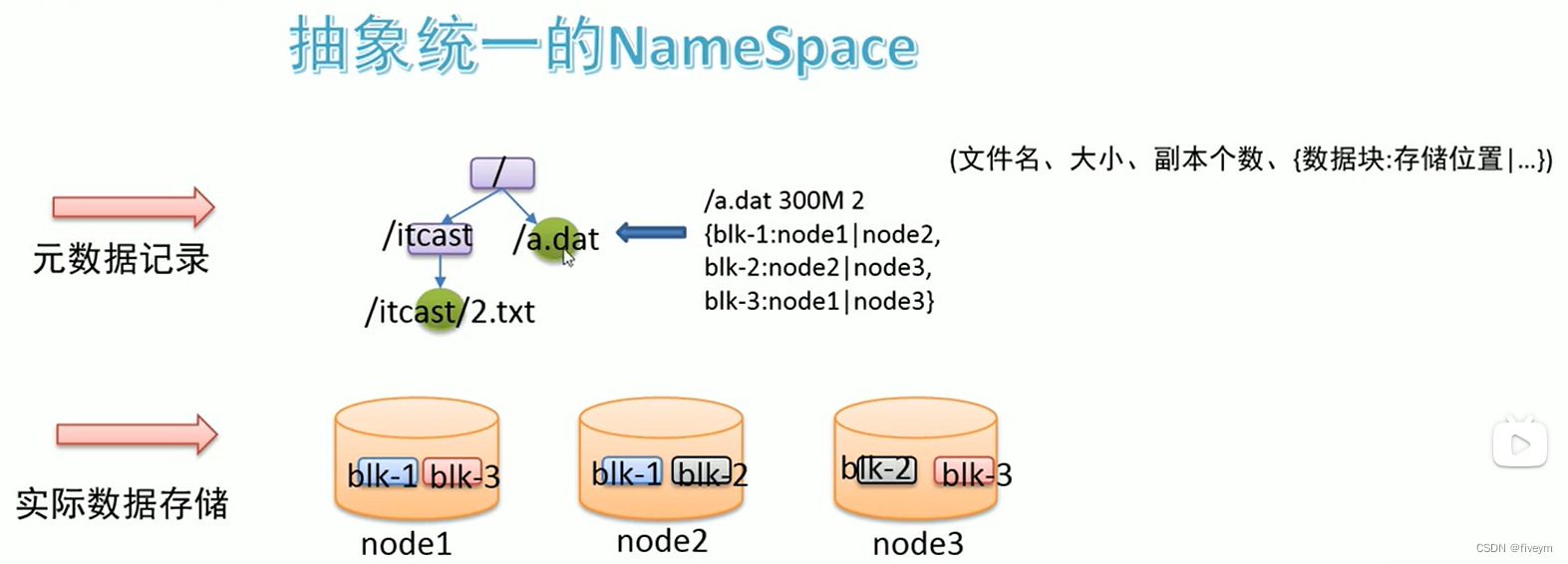
当文件被分布式存储在多台机器之后,后续获取文件的时候如何能快速找到文件位于哪台机器上呢。可以借助元数据记录来解决这个问题。把文件和其存储的机器的位置记录下来,类似图书馆查阅图书系统,这样就可以快速定位存储在哪台机器上了
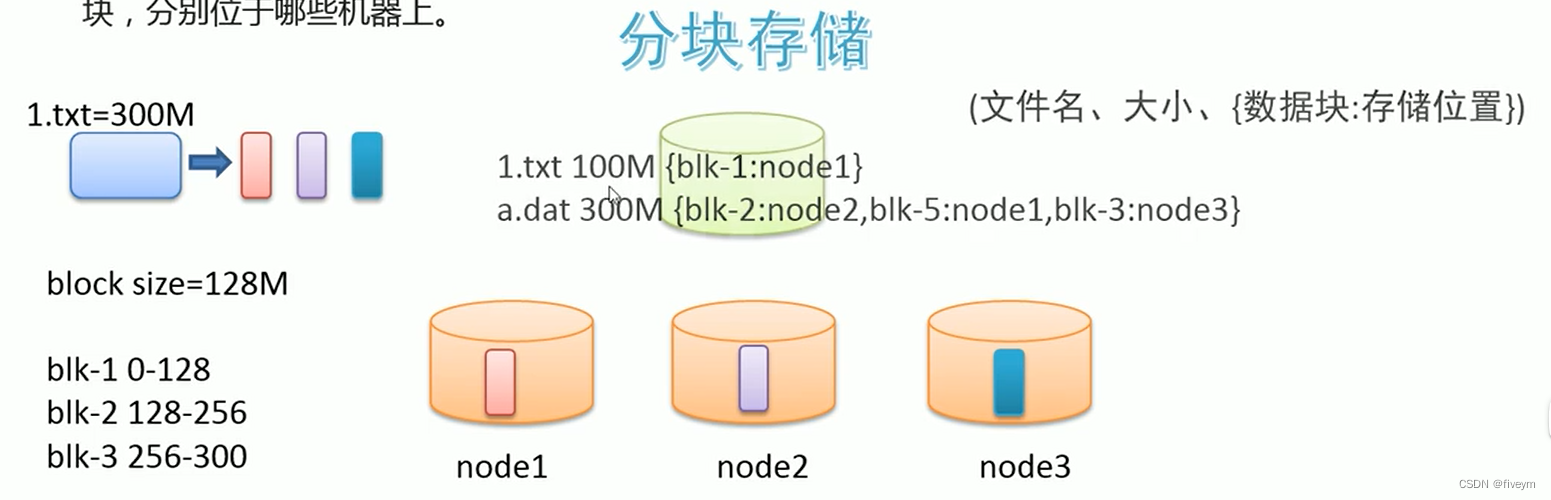
如何解决大文件传输效率慢的问题
大数据使用的场景下:GB,TB级别的大文件是常见的。当单个文件过大的时候,如何提高传输效率?通常的做法是分块存储:把大文件拆分成若干个小块(bolock),分别存储在不同机器上,并行操作提高效率。
此外分块存储还可以解决数据存储负载均衡问题。此时元数据记录信息也应该更加详细:文件分类几块,分别位于哪些机器上。
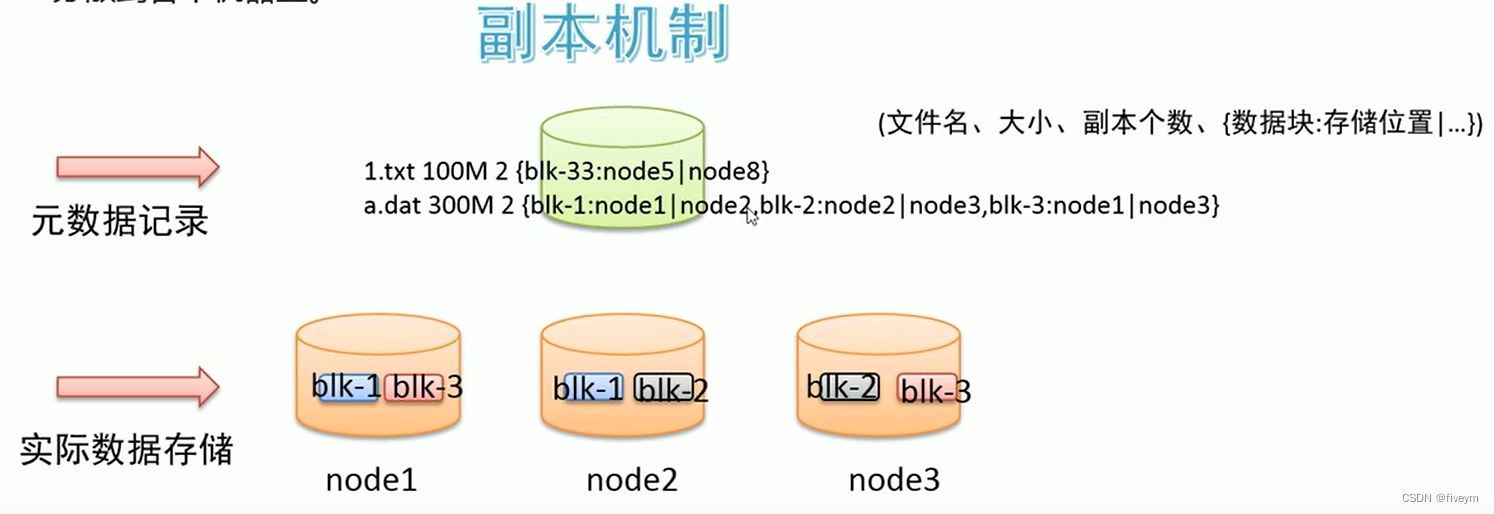
如何解决硬件故障数据丢失问题
机器、磁盘等硬件出现故障时难以避免的事情,如何保证数据存储的安全性。如果某台机器故障,数据丢失,对于文件来说整体就是不完整的。冗余存储是个不错的选择。采用副本机制。副本越多,数据越安全、当然冗余也会越多、通过“不要把鸡蛋放在一个篮子里”的思想,可以把数据丢失的方向分散在各个机器上。
如何解决用户查询视角统一规则问题
随着存储的进行,数据文件越来越多,与之对应元数据信息也越来越多,如何让用户视觉层面感觉不到元数据的凌乱,同时也与传统的文件系统操作体验保持一致?传统的文件系统拥有所谓的目录数结构,带有层次感的namespace(命名空间),因此可以把分布式文件系统的元数据记录这一块也抽象成统一的目录树结构。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









