







安装Linux虚拟机
1.先下载 Linux的CentOS-7-x86_64-DVD-2009.ios 映像,其他版本也可以,但学习一般用CentOS7 官网下载
2.打开 VMware workstation pro 官网下载 安装,然后创建新的虚拟机

3.选择 自定义(高级),然后,下一步
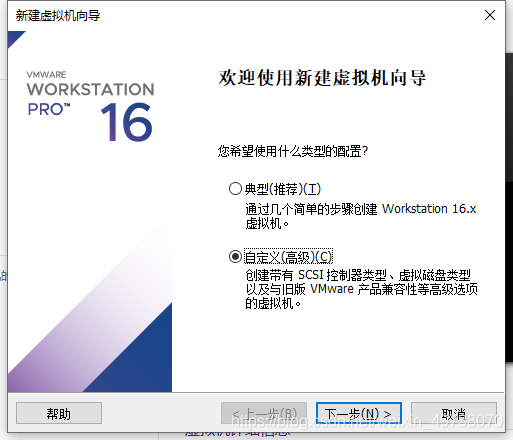
4.选其他版本也可以,然后,下一步
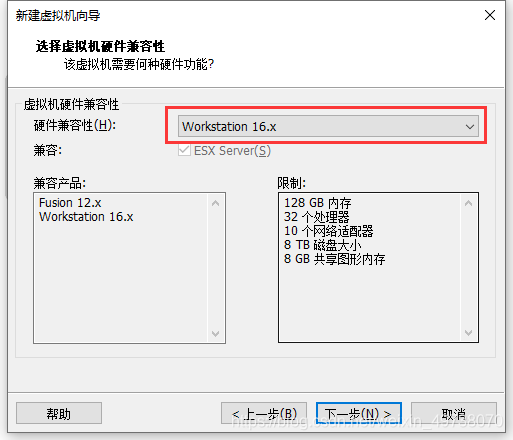
5.配置已经下载好的镜像,然后选择稍后安装操作系统,下一步
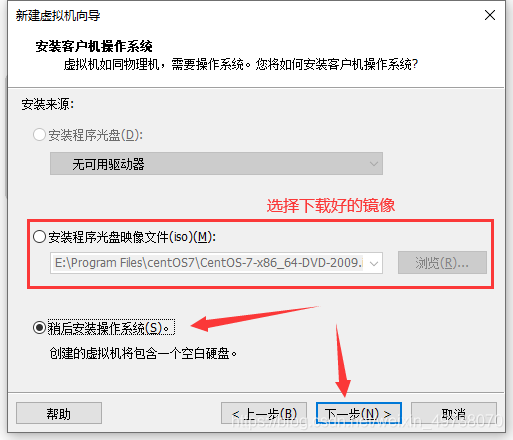
6.选择Linux,下一步
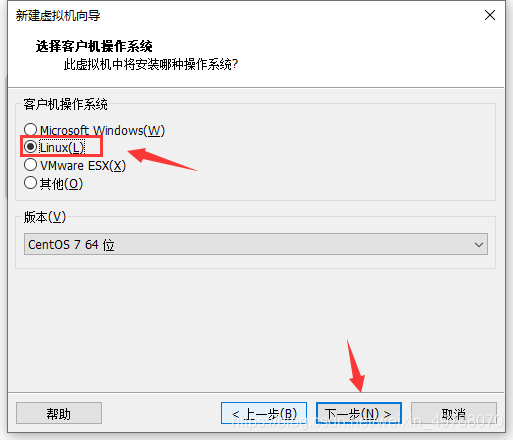
7.自定义虚拟机名称和安装位置,下一步
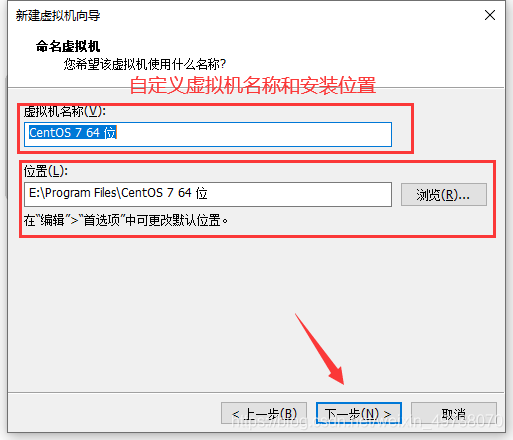
8.按电脑配置,分配自己认为合理的处理器即可,下一步
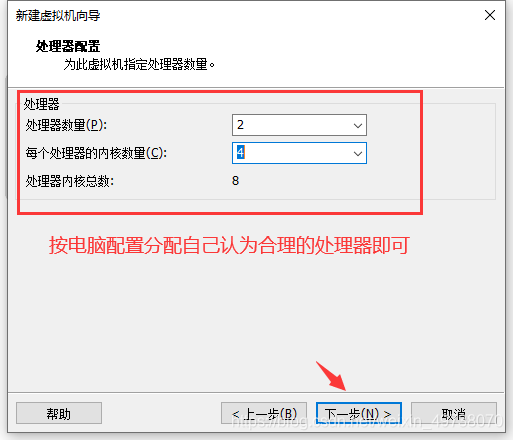
9.给虚拟机分配内存,2g或者4g,下一步
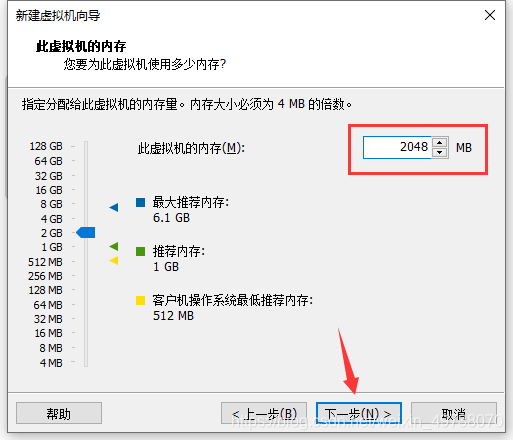
10.使用桥接模式,下一步
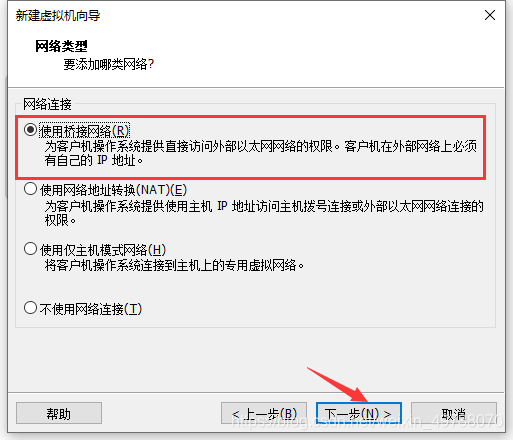
11.推荐,下一步
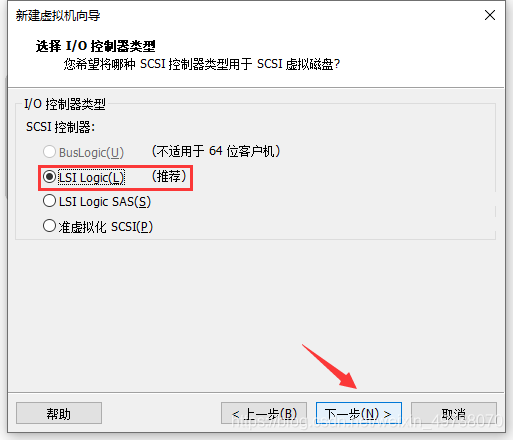
12.推荐,下一步
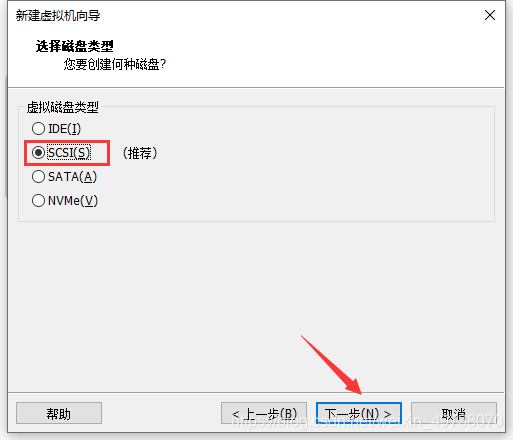
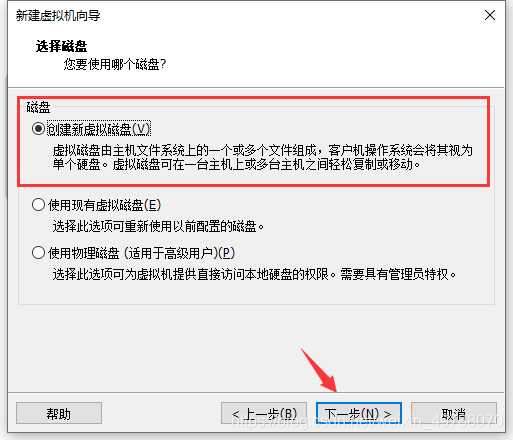
13.创建新虚拟磁盘,下一步
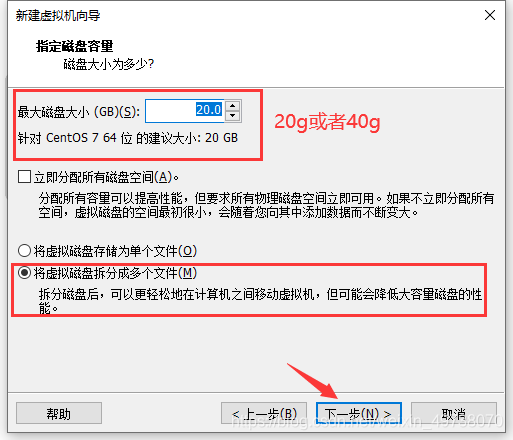
14.磁盘大小20g或者40g,下一步
15.下一步
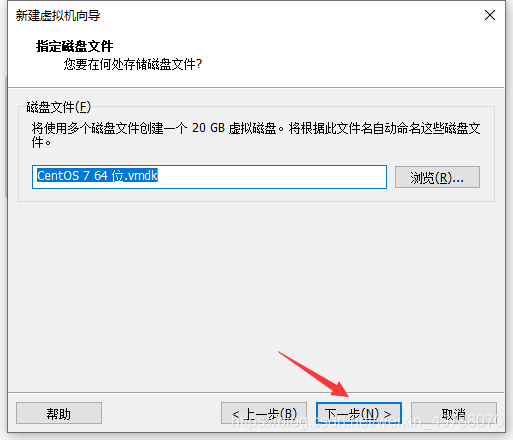
16.完成
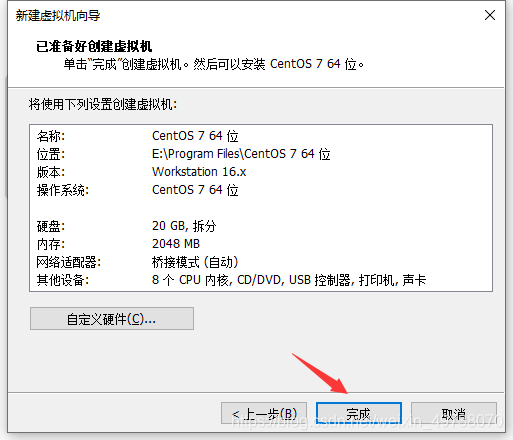
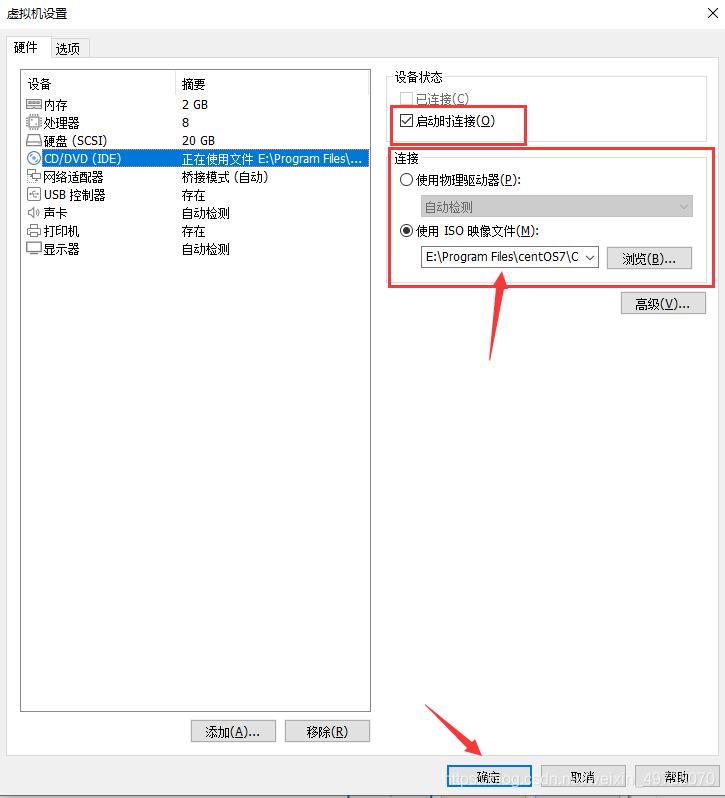
17.先配置网络适配器桥接模式,再配置好cd/dvd
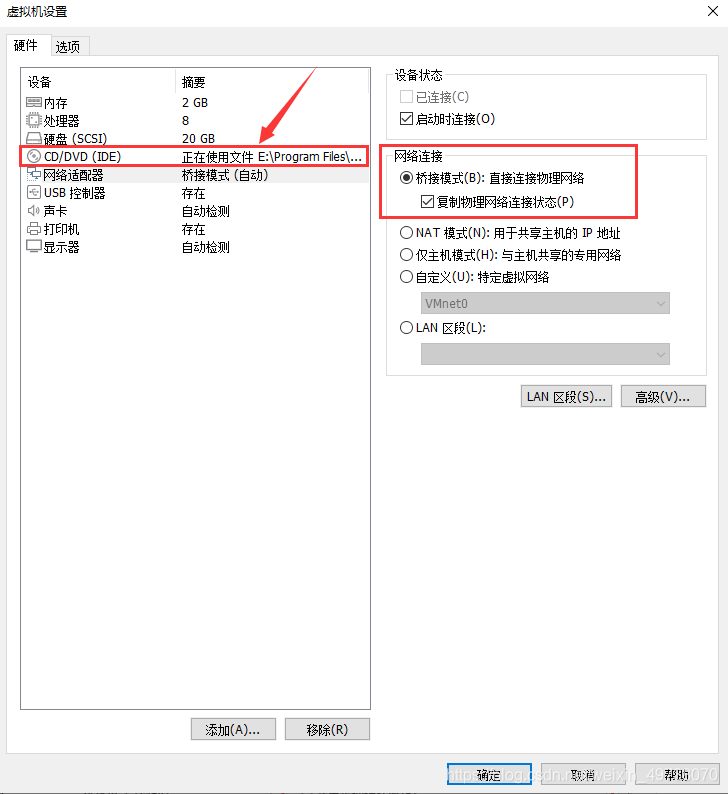
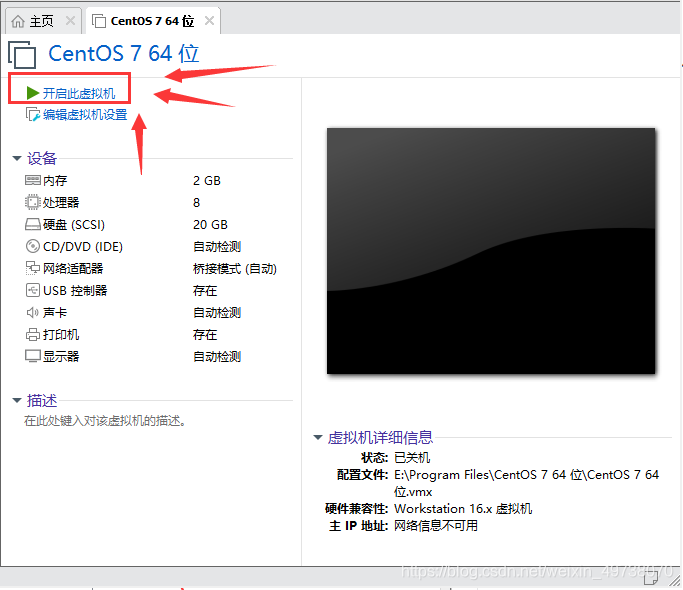
18.开启虚拟机
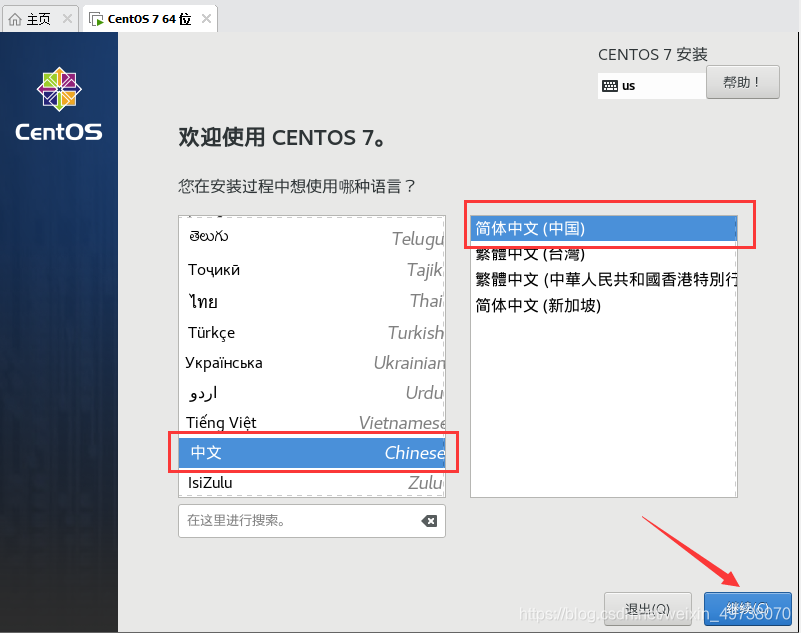
19.等待……好多好多黑框框,和英文字母,还有ok过去后,继续……
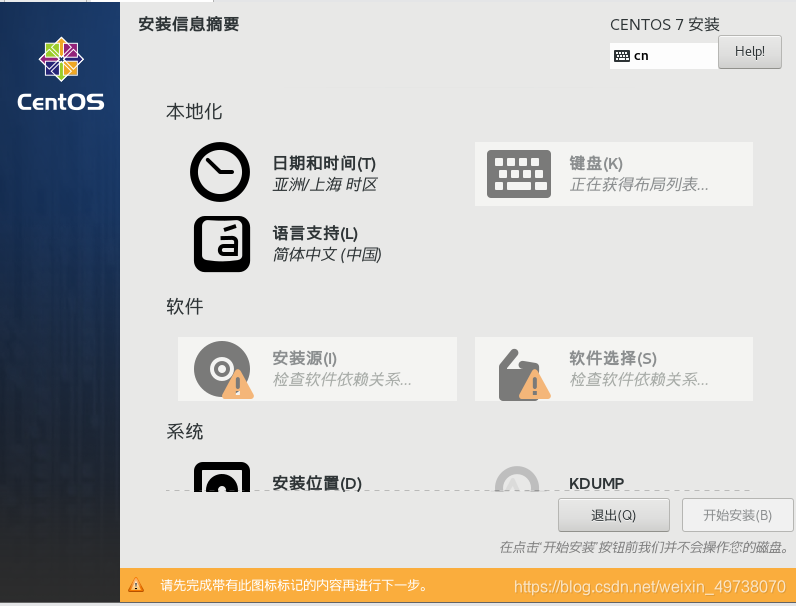
20.等待检测完毕,然后配置软件选择,开发及生成工作站可以以全选,接着完成
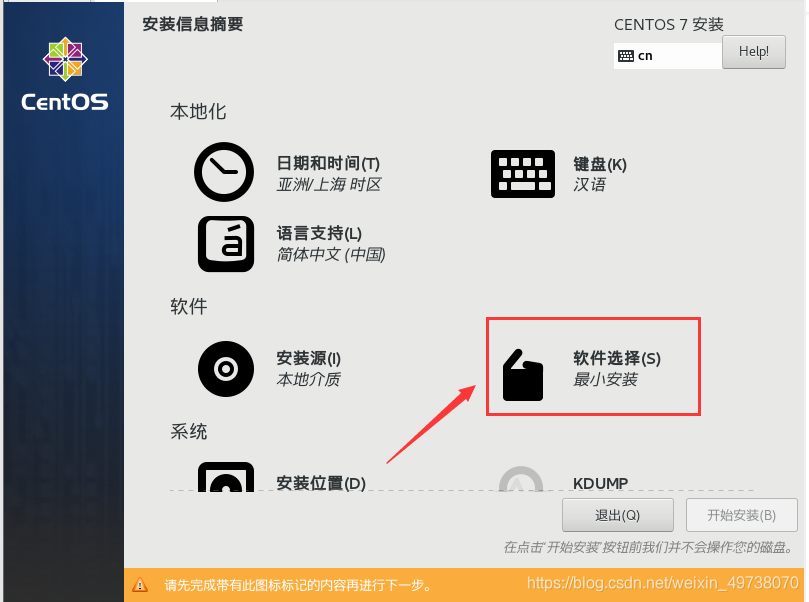
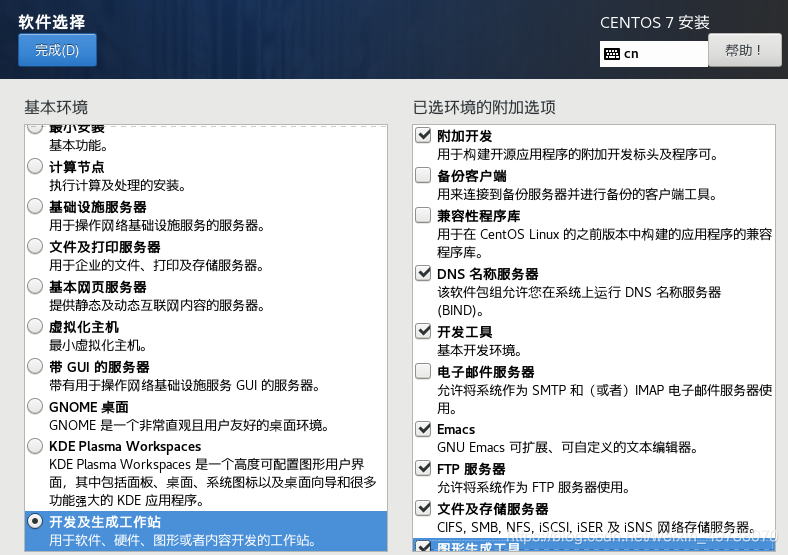
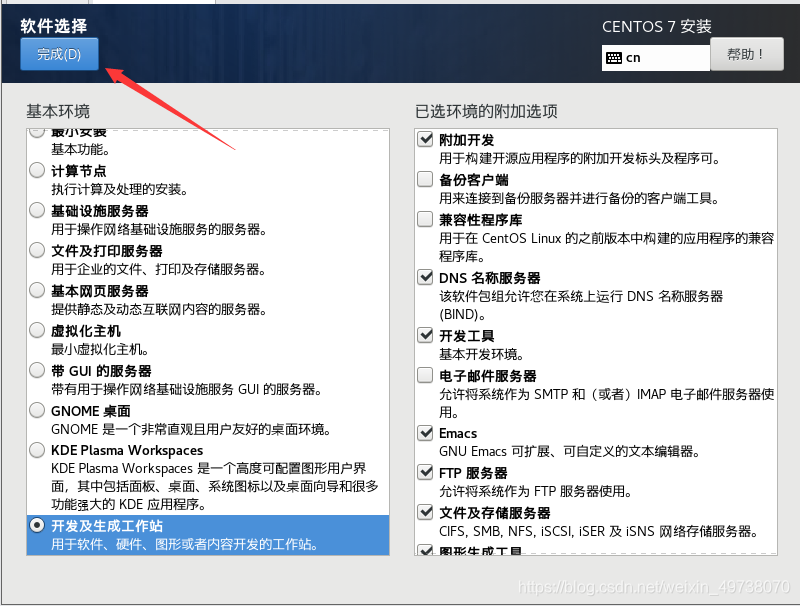
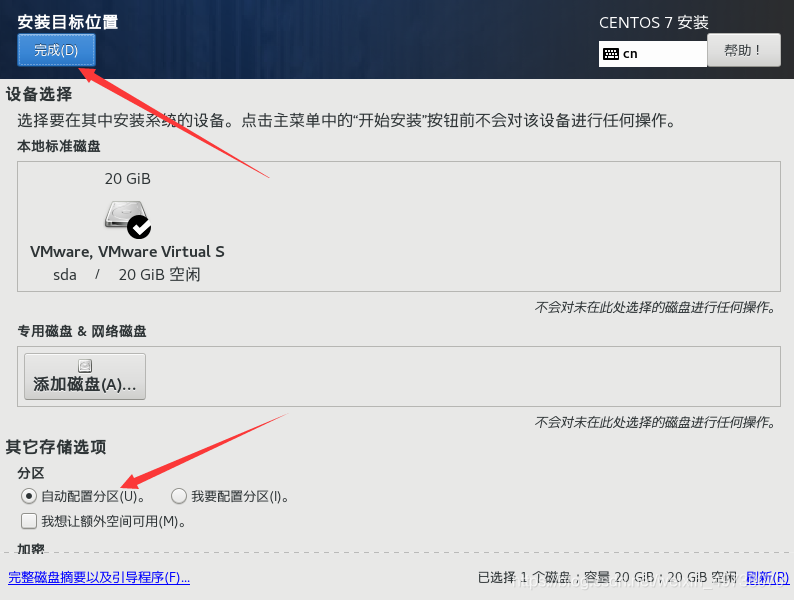
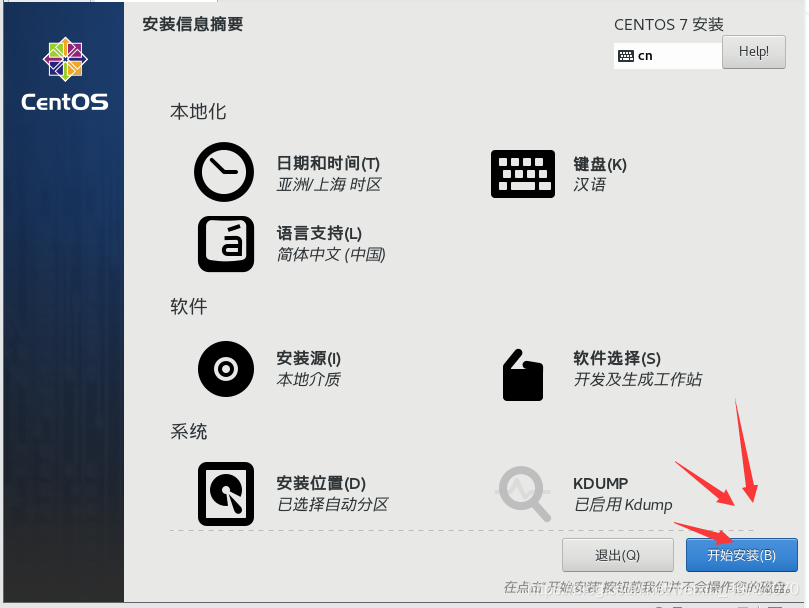
21.安装位置,然后开始安装,漫长等待……(耐心点)
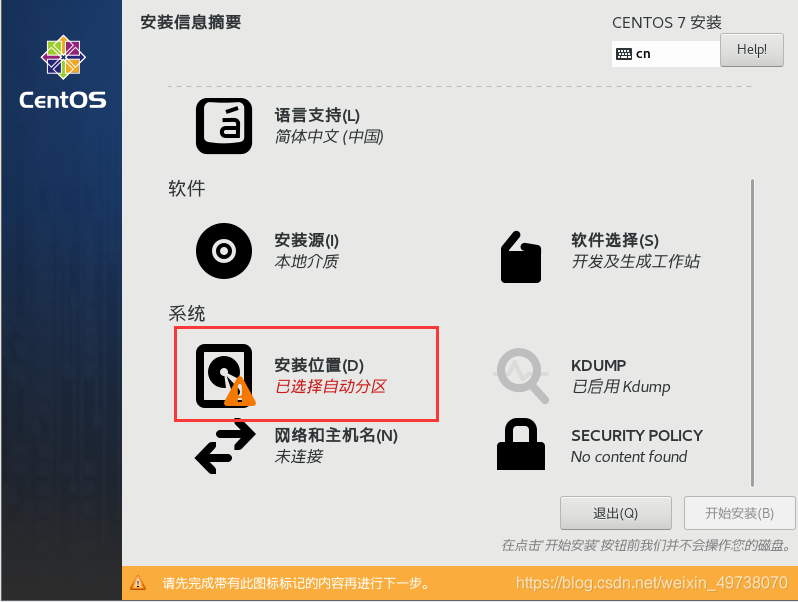
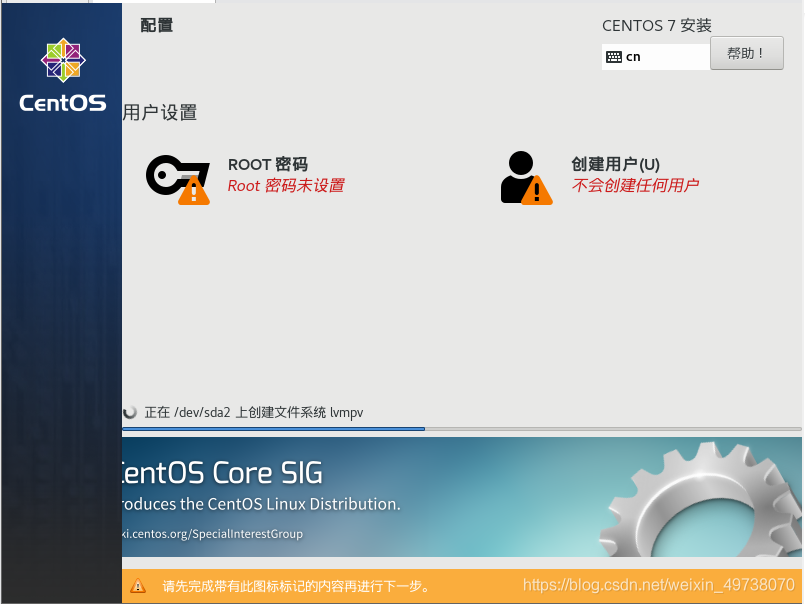
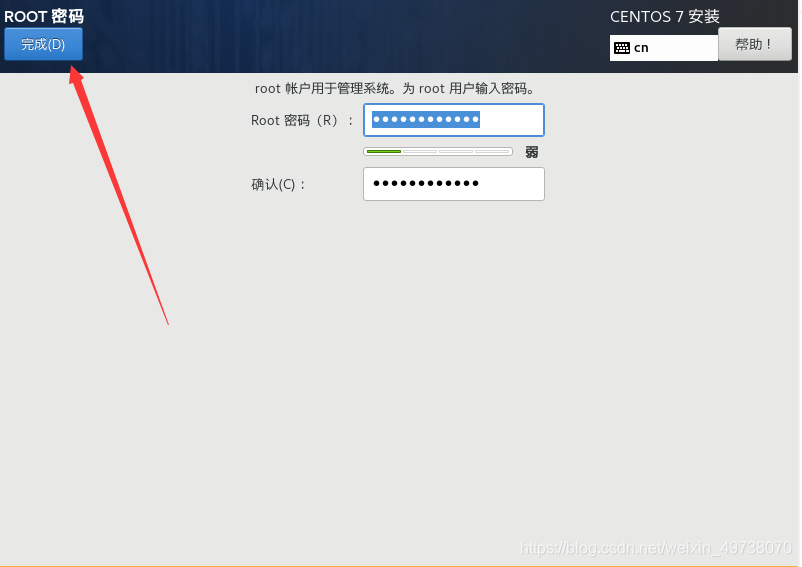
22.等待安装中可以配置root密码
23.安装完成后重启
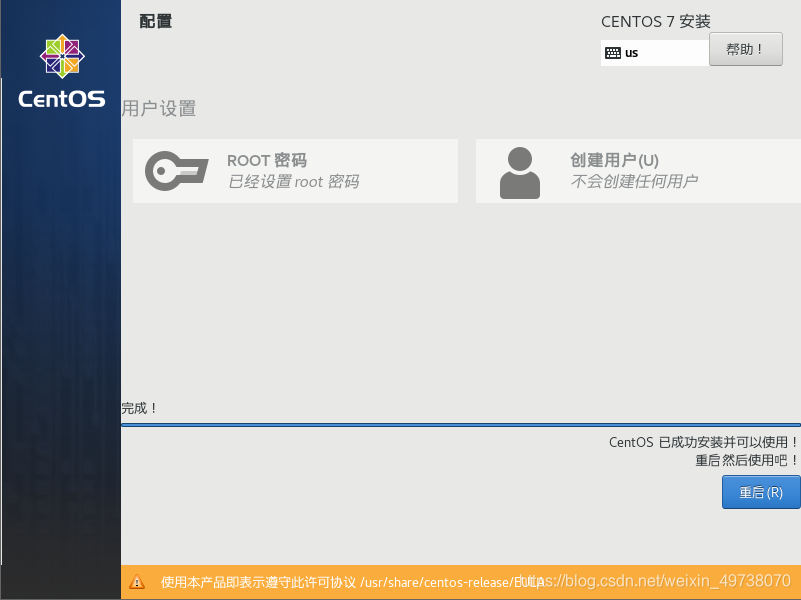
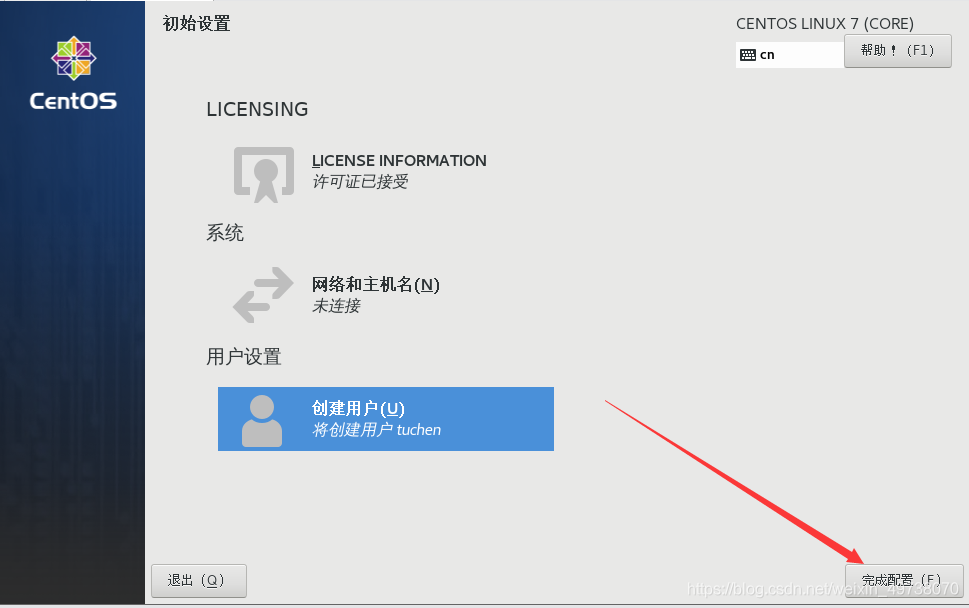
24.接受许可证,创建用户,完成配置
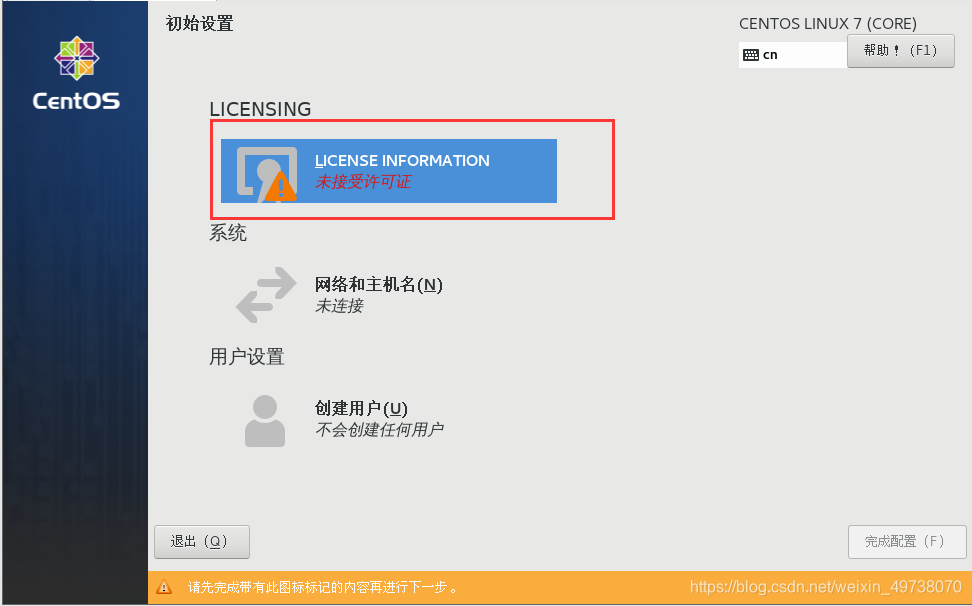
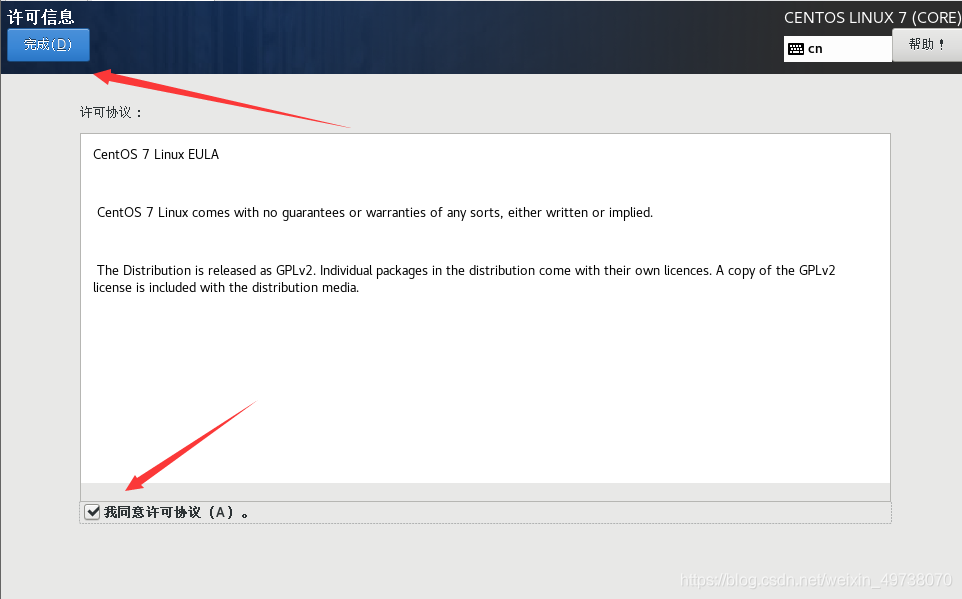
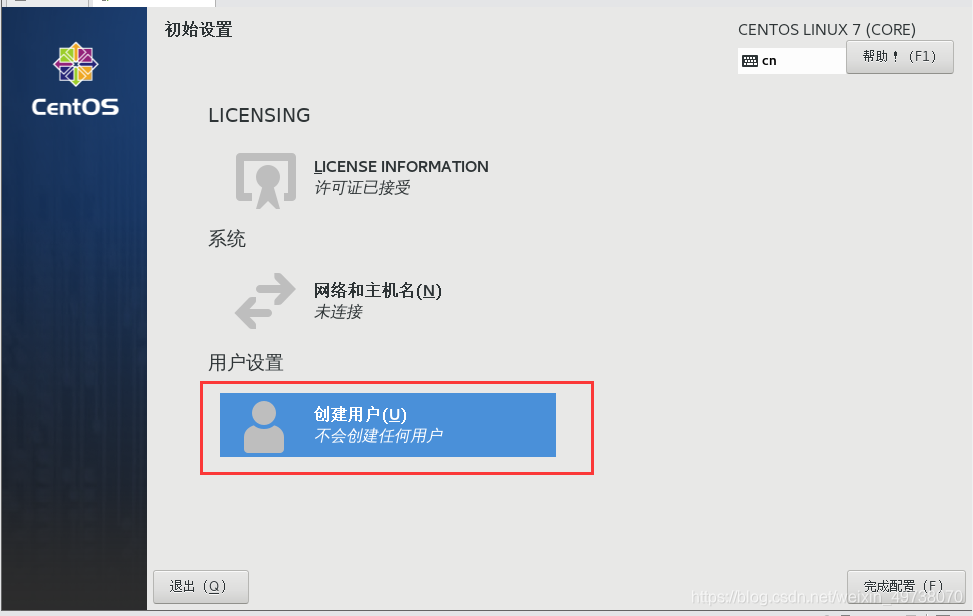
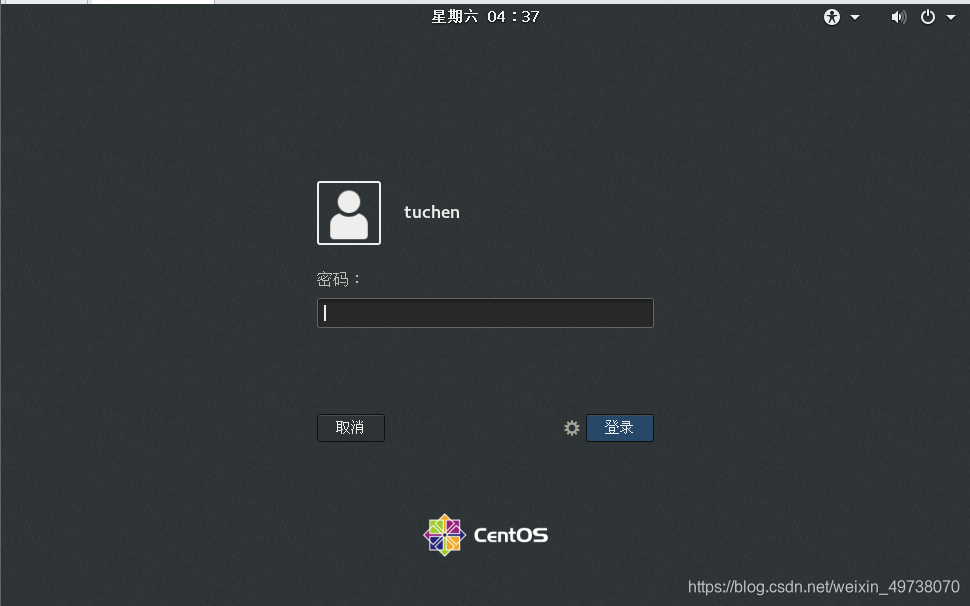
25.登入自己的用户名密码,上面创建的用户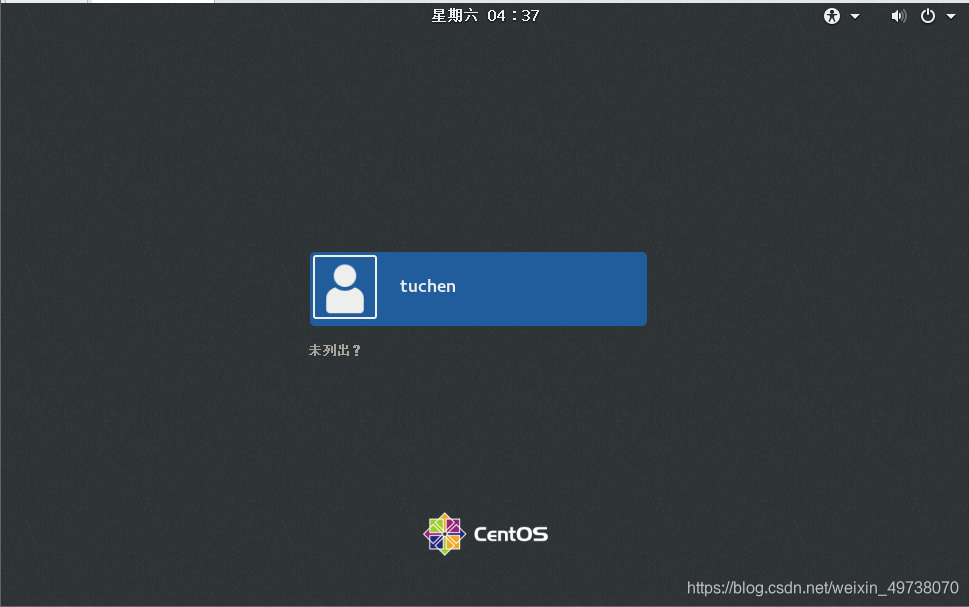
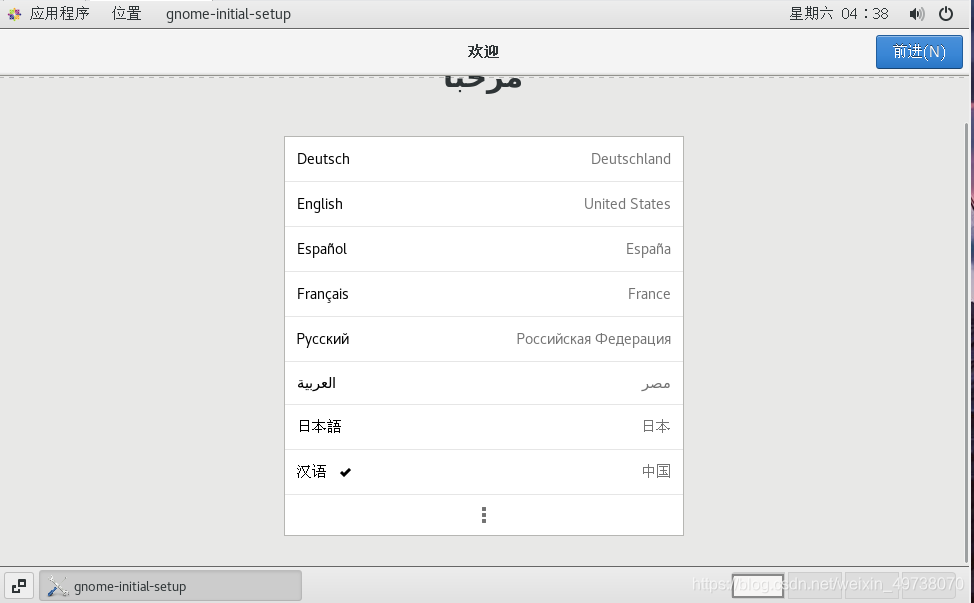
26.接着登录,如下图直到出现主界面,即安装成功,起飞……(一路顺风)
作者:如果还有什么问题,欢迎留言……谢谢

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









