







数据表基本操作
更新表记录(update)
update 表名 set 字段1=值1,字段2=值2,... where 条件;
注意:update语句后如果不加where条件,所有记录全部更新
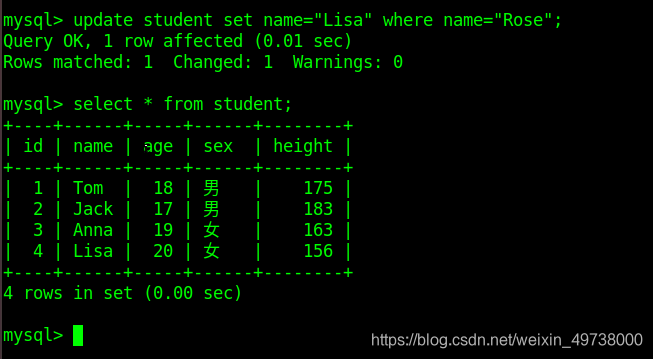
在这里我们把name为Rose的改为Lisa
查看已经更新后的表

删除表记录(delete)
delete from 表名 where 条件;
注意:delete语句后如果不加where条件,所有记录全部清空
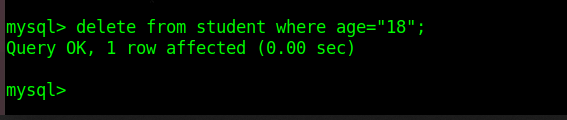
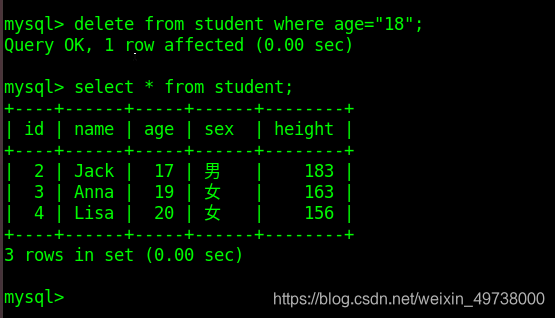
删除age为18的内容
表字段的操作(alter)
语法 :alter table 表名 执行动作;
* 添加字段(add)
alter table 表名 add 字段名 数据类型;
alter table 表名 add 字段名 数据类型 first;
alter table 表名 add 字段名 数据类型 after 字段名;
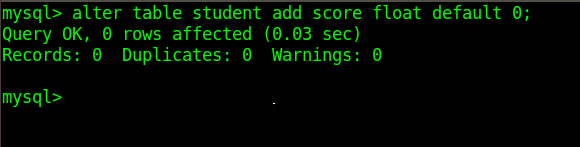
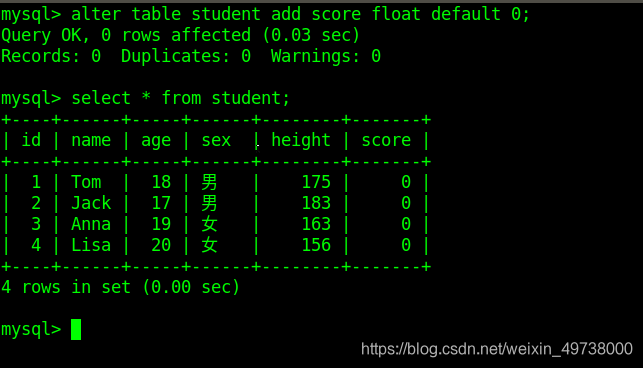
为student表添加了一个score
查看已添加score后的student表
* 删除字段(drop)
alter table 表名 drop 字段名;
删除score,这里我们没有删除后面需要用到

* 修改数据类型(modify)
alter table 表名 modify 字段名 新数据类型;

* 修改字段名(change)
alter table 表名 change 旧字段名 新字段名 新数据类型;
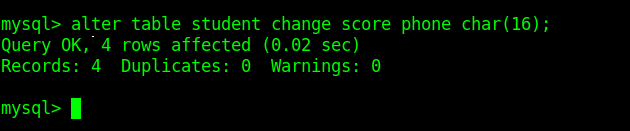
把score改为phone
* 表重命名(rename)
alter table 表名 rename 新表名;
我们把student更改为employee
已成功更改表名


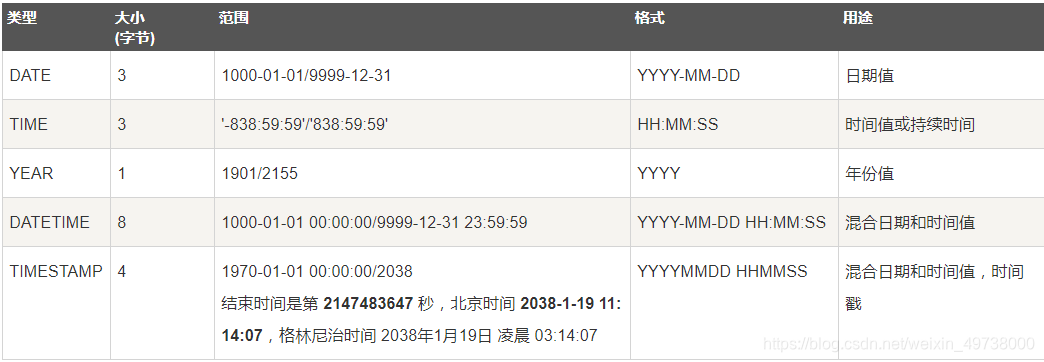
时间类型数据
- 日期 : DATE
- 日期时间: DATETIME,TIMESTAMP
- 时间: TIME
- 年份 :YEAR
- 时间格式
date :"YYYY-MM-DD"
time :"HH:MM:SS"
datetime :"YYYY-MM-DD HH:MM:SS"
timestamp :"YYYY-MM-DD HH:MM:SS"
注意:
- datetime :以系统时间存储
- timestamp :以标准时间存储但是查看时转换为系统时区,所以表现形式和datetime相同
e.g.
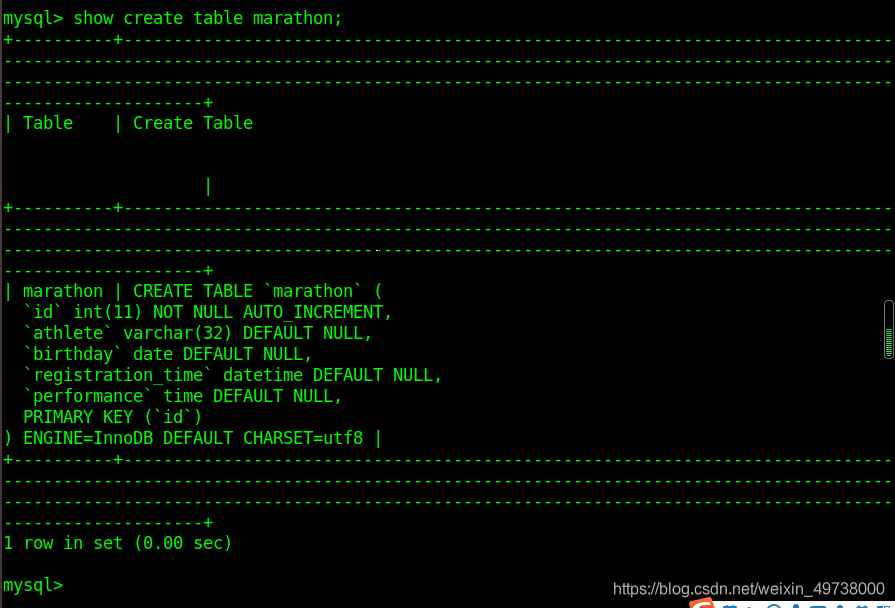
create table marathon (id int primary key auto_increment,athlete varchar(32),birthday date,registration_time datetime,performance time);

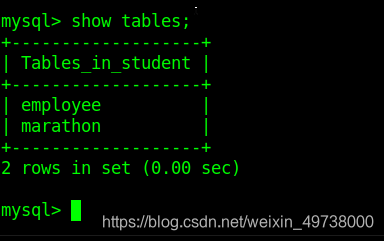
创建一个marathon表
创建成功
查看marathon创建
- 添加数据方法1

- 添加数据方法2

- 添加数据方法3

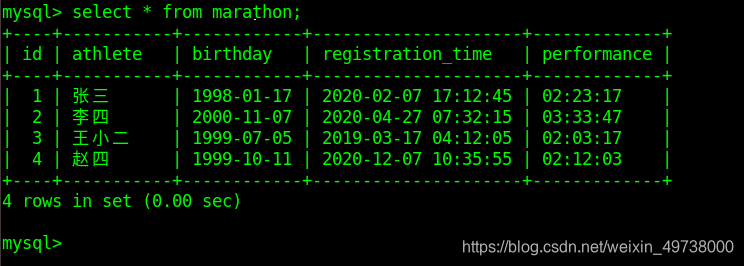
查看添加数据后的marathon
-
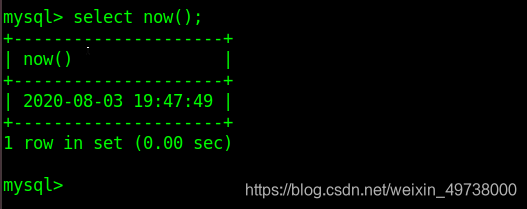
日期时间函数
- now() 返回服务器当前日期时间,格式对应datetime类型
- curdate() 返回当前日期,格式对应date类型
- curtime() 返回当前时间,格式对应time类型
-
时间操作
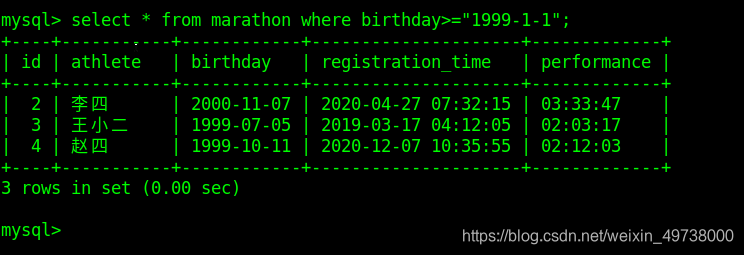
时间类型数据可以进行比较和排序等操作,在写时间字符串时尽量按照标准格式书写。
select * from marathon where birthday>='2000-01-01';
select * from marathon where birthday>="2000-07-01" and performance<="2:30:00";
高级查询语句
- 模糊查询和正则查询
-
模糊查询
LIKE用于在where子句中进行模糊查询,SQL LIKE 子句中使用百分号
%来表示任意0个或多个字符,下划线_表示任意一个字符。
SELECT field1, field2,...fieldN
FROM table_name
WHERE field1 LIKE condition1
e.g.
mysql> select * from class_1 where name like 'A%';
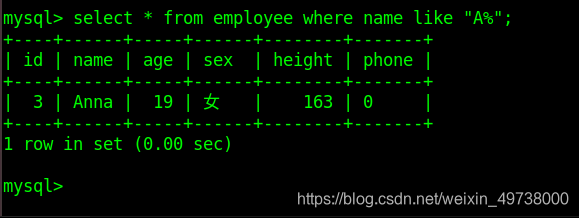
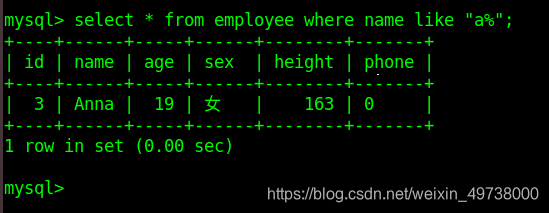
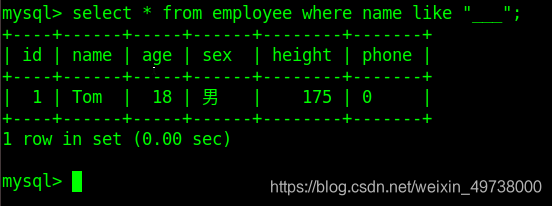
2. 正则查询
mysql中对正则表达式的支持有限,只支持部分正则元字符:
SELECT field1, field2,...fieldN
FROM table_name
WHERE field1 REGEXP condition1
e.g.
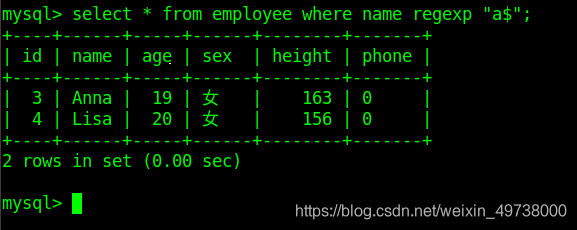
select * from class_1 where name regexp '^B.+';
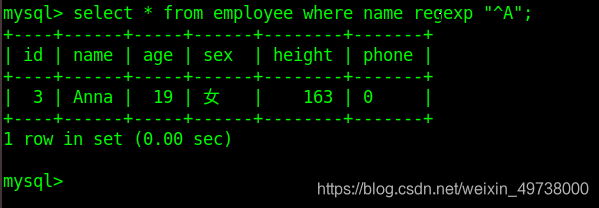
- as 用法
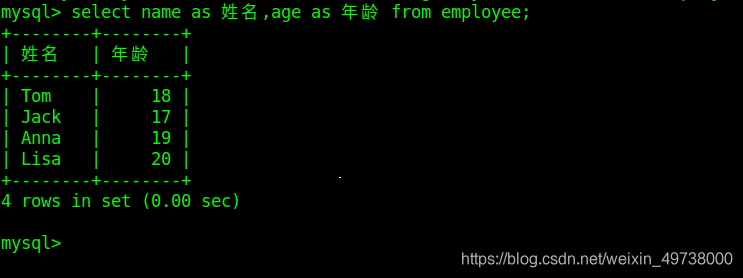
在sql语句中as用于给字段或者表重命名
select name as 姓名,age as 年龄 from class_1;
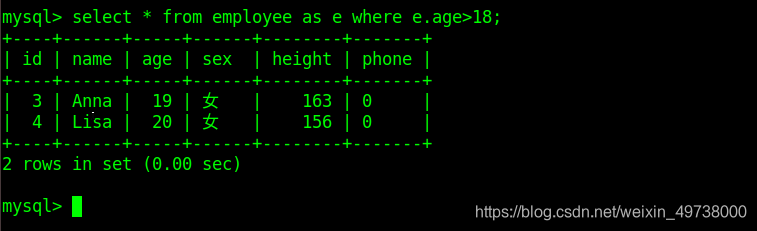
select * from class_1 as c where c.age > 17;
排序
ORDER BY 子句来设定你想按哪个字段哪种方式来进行排序,再返回搜索结果。
使用 ORDER BY 子句将查询数据排序后再返回数据:
SELECT field1, field2,...fieldN from table_name1 where field1
ORDER BY field1 [ASC [DESC]]
默认情况ASC表示升序,DESC表示降序
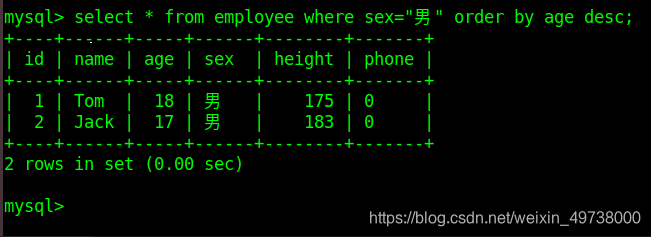
select * from class_1 where sex='m' order by age desc;
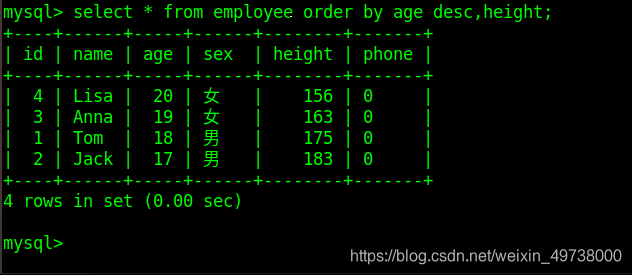
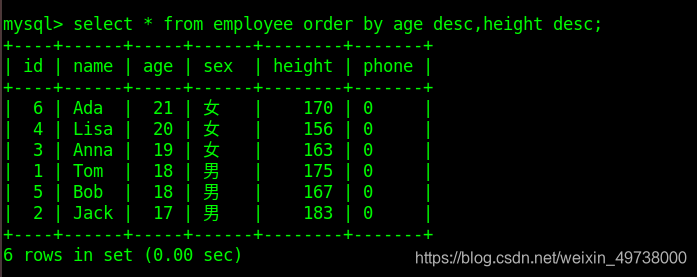
复合排序:对多个字段排序,即当第一排序项相同时按照第二排序项排序
select * from class_1 order by score desc,age;
复合排序1
复合排序2
- 限制
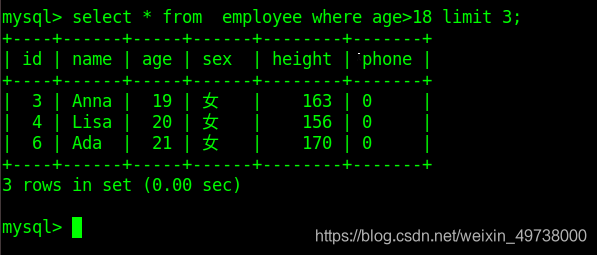
LIMIT 子句用于限制由 SELECT 语句返回的数据数量 或者 UPDATE,DELETE语句的操作数量
带有 LIMIT 子句的 SELECT 语句的基本语法如下:
SELECT column1, column2, columnN
FROM table_name
WHERE field
LIMIT [num]
- 联合查询
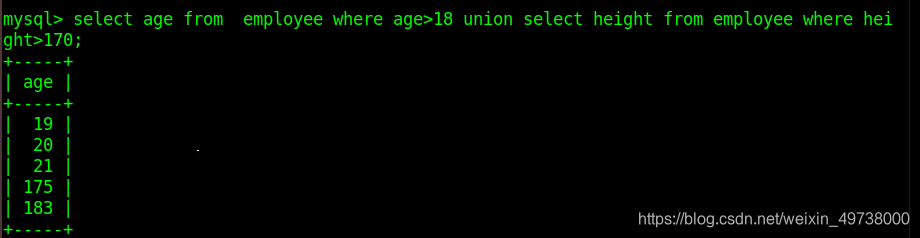
UNION 操作符用于连接两个以上的 SELECT 语句的结果组合到一个结果集合中。多个 SELECT 语句会删除重复的数据。
UNION 操作符语法格式:
SELECT expression1, expression2, ... expression_n
FROM tables
[WHERE conditions]
UNION [ALL | DISTINCT]
SELECT expression1, expression2, ... expression_n
FROM tables
[WHERE conditions];
默认UNION后卫 DISTINCT表示删除结果集中重复的数据。如果使用ALL则返回所有结果集, 包含重复数据。
select * from class_1 where sex='m' UNION ALL select * from class_1 where age > 9;
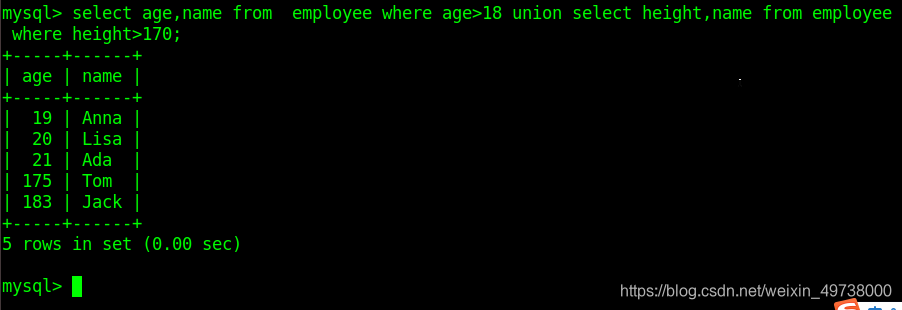
-
子查询
- 定义 : 当一个select语句中包含另一个select 查询语句,则称之为有子查询的语句
- 子查询出现的位置:
- from 之后 ,此时子查询的内容作为一个新的表内容,再进行外层select查询
select name from (select * from class_1 where sex='m') as s where s.score > 90;
注意: 需要将子查询结果集重命名一下,方便where子句中的引用操作
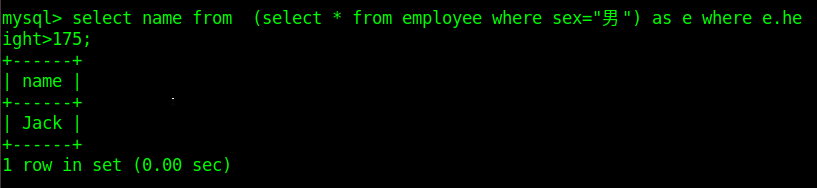
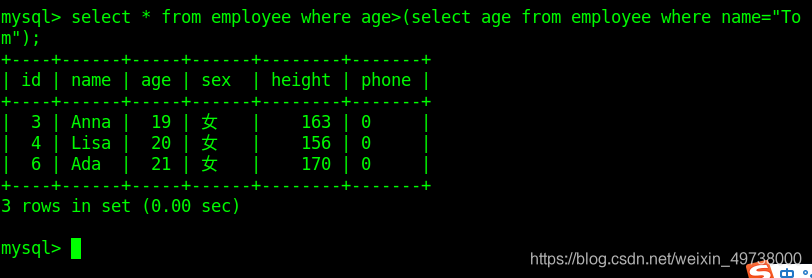
- where字句中,此时select查询到的内容作为外层查询的条件值
select * from class_1 where age = (select age from class_1 where name='Tom');
注意:
子句结果作为一个值使用时,返回的结果需要一个明确值,不能是多行或者多列。
如果子句结果作为一个集合使用,即where子句中是in操作,则结果可以是一个字段的多个记录。
- 查询过程
通过之前的学习看到,一个完整的select语句内容是很丰富的。下面看一下select的执行过程:
(5)SELECT DISTINCT <select_list>
(1)FROM <left_table> <join_type> JOIN <right_table> ON <on_predicate>
(2)WHERE <where_predicate>
(3)GROUP BY <group_by_specification>
(4)HAVING <having_predicate>
(6)ORDER BY <order_by_list>
(7)LIMIT <limit_number>


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









