







 本文详细介绍了树数据结构,包括树的定义、类型如满二叉树和完全二叉树,以及字典树的概念。此外,还探讨了树的公式、存储方法、遍历策略,并举例说明了如何通过树实现优先队列。最后,提供了C++源码示例来展示树的应用。
本文详细介绍了树数据结构,包括树的定义、类型如满二叉树和完全二叉树,以及字典树的概念。此外,还探讨了树的公式、存储方法、遍历策略,并举例说明了如何通过树实现优先队列。最后,提供了C++源码示例来展示树的应用。
文章目录
1、树的定义
2、树的类型
3、树形结构内的公式
4、使用树的方法
5、树的应用
一、树的定义
树,是一种突破链形的数据结构。像之前学的数组,栈,队列等都属于链形结构。二维数组也是链形的,就是由几条横线和竖线组成的矩形。
把它叫做树,是因为它像一棵倒着的树。而在中国,它应该叫“族谱”。其实,在树中的节点就是叫“父节点”这样的词(好像扯得太远了)。
树中最上的节点叫做“根”,除根以外的元素也构成了树,它们叫做子树。
子树的子节点个数,叫做这个节点的度。
度为0的节点,叫做叶子节点(没有儿子的节点)。
树的度,是最大的节点的度数(有几个儿子)。
树的深度,是树中最多子孙的深度。
x叉树:树中最多有几度。

二、树的类型
一、满二叉树:
定义:除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。
重要公式:
1、满二叉树层数为k,则总节点个数为(2^k)-1。
2、满二叉树第i层上的结点数为2^(i-1)。
3、满二叉树的叶子结点个数为(2^k)-1。
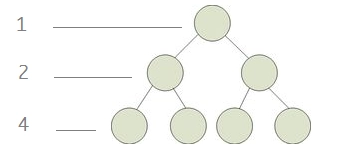
二、完全二叉树:
定义:
满二叉树是完全二叉树的特殊形态, 即如果一棵二叉树是满二叉树, 则它必定是完全二叉树。
重要公式:
一、具有n个结点的完全二叉树的深度为:*trunc(log2k)+1。
二、令1节点为i,则左儿子为2i,右儿子为2i+1。
注:trunc的意思是去小数点取整。
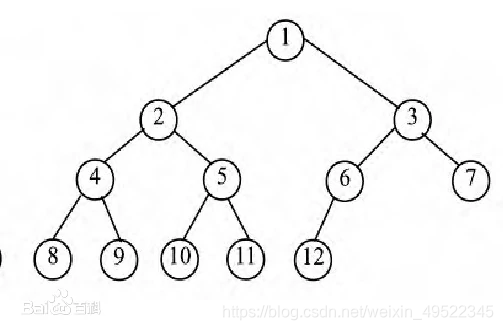
三、字典树
定义:它又叫做单词查找树(像哈希表,只不过比哈希表省时间)
举个例子:查询单词younger后,再查找young,就不用查到底了。但哈希查younger要先查一次,查young时还要再查一次,就比字典树浪费时间。
三、树形结构的公式
引用https://www.cnblogs.com/stemon/p/4775247.html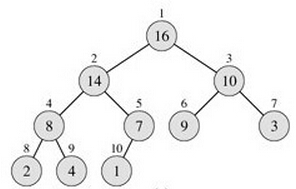
对于一棵二叉树,设叶子节点个数为n0,度为1的节点个数为n1,度为2的节点个数为n2。
则:n0+n1+n2=n
又由于除了根节点以外,每一个结点都占有一个边,
所以:n-1=2*n2+n1
综合上面的两个公式得到:
叶子结点和二度结点数目关系:n0=n2+1,n2=n0-1。
n个节点的二叉树一共有:(2n)! / n! * (n+1)!
注:’/'是除以的意思,!是阶乘的意思(123*4…n)。
一个完全二叉树的节点为n,则该二叉树的叶子节点为:1/2*n
四、使用树的方法
一:存储
(1):使用struct(不管是不是完全二叉树)
struct node {
char data;
int left;
int right;
}tree[10011];//创建树节点,左右儿子节点
......
for (.../*分题目情况*/)
cin >> tree[i].data >> tree[i].left >> tree[i].right;
(2):使用数组
如果是完全二叉树(直接存储):
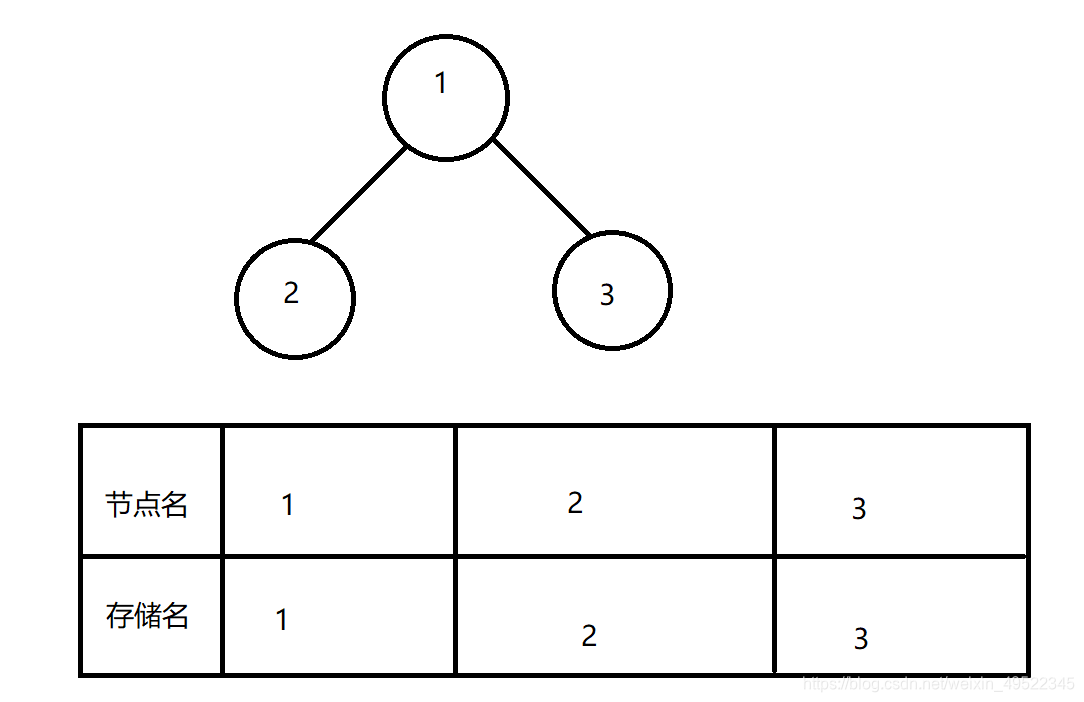
自己画的哈(太丑请谅解)
如果不是完全二叉树(把空的地方用’#'表示):
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









