







 文章详细介绍了SQL中的日期转换函数To_date和To_char,以及Select查询语句的各种用法,包括投影查询、别名、去重。还讲解了Where子句的基本应用、模糊查询、区间查询、值列表查询和空值查询。此外,还讨论了Order_by子句的排序功能和From子句在多表查询中的作用,如内连接、外连接。最后提到了Group_by子句和Having子句在分组和过滤聚合结果时的应用。
文章详细介绍了SQL中的日期转换函数To_date和To_char,以及Select查询语句的各种用法,包括投影查询、别名、去重。还讲解了Where子句的基本应用、模糊查询、区间查询、值列表查询和空值查询。此外,还讨论了Order_by子句的排序功能和From子句在多表查询中的作用,如内连接、外连接。最后提到了Group_by子句和Having子句在分组和过滤聚合结果时的应用。
- 两个日期函数
To_date(字符串值,日期模式); ---- 将字符串转成日期类型数据。多用与 insert 语句中。
insert into order_no5(order_id,order_price,order_date)
values (seq01.nextval,100,to_date('2023-3-2','YYYY-MM-DD'));
To_char(日期值,日期格式); ---- 将日期类型转换为字符串类型。多用于 select 语句中。
select to_char(order_date,'YYYY-MM-DD hh24:mi:ss') from order_no5;
- Select 语句
select 语句的完整子句:
- Select ---- 查什么,显示什么。
- From ---- 从哪里查,从哪些表中查询数据。多表查询
- Where ---- 条件,过滤记录(行)。满足条件的记录才会被查询出来。
- Group by ---- 分组,进行数据统计时,经常使用到分组操作。
- Having ---- 条件,过滤记录(行)。对分组过后的汇总统计结果进行过滤。
- Order by ---- 排序,对查询结果进行排序。
select 子句-查询所有:
Select 子句是对列的过滤。只有在 select 子句后面出现的列名。才是我们需要查询的列。
select * from 表;
--例:
select * from order_no5;
select 子句-投影查询:
投影查询:就是指定一些字段进行查询显示。
Select 列名,列名 from 表;
select goods_name,goods_price from goods_no5;
select 子句-别名:
别名。可以为每一个列创建一个新的别名。
Select 字段 [as] 别名 , 表达式 as 别名 from 表 别名
select o1.order_id "编号",to_char(o1.order_date,'YYYY-MM-DD')
as "日期" from order_no5;
select 子句-去重:
因为 select 子句的查询支持投影查询的方式。
select distinct goods_name from goods_no5;
where 子句-基本应用:
在基本应用中,比较基础的判断表达式。
比较运算符。
Where 字段 = 值
Where 年龄 > 20
Where 字段 != 值
逻辑运算符:and or not
Where 字段 = 值 and 字段 > 值
Where not 字段 = 值
where 子句-模糊查询 like:
Like 关键字是在 Where 子句中的模糊查询。
模糊查询就是一个像什么样的一个查询。
模糊查询只适用于字符串类型。
在使用模糊查询时,必须使用到二个 通配符。
1. % 表示任意多个字符。
2. _ 表示任意一个字符。
使用方法:Where 字段 like ‘通配符字符串’。
查询所有刘姓的同学:
select * from 表 where name like '刘%';
还有一种方式表示查询在任意位置出现:
where 字段 like '%abc%'
--表示任意位置出现abc
where 子句-区间查询 between…and :
Between…and 是区间查询,用来在二个取值的范围之间查询。
区间查询只能应用到数值类型和日期类型
使用方法:
Where 字段 between A and B;
表示字段的取值范围在 A-B 之间。 [A,B]
等价于 where 字段 >=A and 字段 <=B
select * from student_no5 where stu_score between 90 and 100;
--90 到 100 分的学员信息
where 子句-值列表查询 in:
in 关键字叫值列表查询,是将多个值,作为一个列表。字段与其中任意一个值相等就表示True。
使用方法:
where 字段 in (值,值,值)
select * from emp where job in ('SALESMAN','MANAGER');
--所有'SALESMAN'和'MANAGER'的emp信息。
where 子句-空值查询 is null:
is null 是用来判断是不是为 null。
使用方法:
Where 字段 is null ;
select * from emp where comm is null;
--查emp表中comm为空的所有信息
查空是 is null
查非空是 is Not null
select * from emp where comm is not null;
select * from emp where not comm is null;
--两种方式都可
Order by 子句-排序:
Order by 做为 select 语句的最后一个子句。它的作用也是最后产生的。
是对查询结果的排序。
asc 表示升序。也是默认排序。
desc 表示降序。
使用方法:
Order by 字段1 [asc|desc] [, 字段2 [asc|desc] ]
主排序规则为字段1,字段2只有在字段1相同的记录上起作用。
select * from emp where comm is not null order by sal desc,empno;
- from 子句-多表查询
在多表查询中,哪一种是按 SQL92 标准的写法。
在 Oracle 数据库中,将多表查询进行优化。同时也提供一种新的写法。
多表查询:
因为我们按三范式的要求,将表进行拆分,以减少数据冗余。
拆分开的表,其实在数据上是有关系的。我们在创建数据表时为了维护这个关系使用了主外键约束。
很多时候,在进行查询时,我们是希望同时查询到二张表的数据。
查询商品表时,也希望能将商品关联的类型信息也一次性查询出来。
多表查询的种类:
多表连接查询一共分二大类:
- 内连接查询 inner join … on
- 外连接查询
2.1 左外连接查询 left [outer] join … on
2.2 右外连接查询 right [outer] join … on
2.3 完全外连接查询 full [outer] join … on
内连接查询 :
使用方法:
From A inner join B on A_B_ID = B_ID;
内连接只要满足连接条件的记录:
select * from A inner join B on a_b_id = b_id;
查询方式:用 A 表中的所有记录与 B 表中的所有记录进行一一匹配。
左外连接查询:
From A left join B on A_B_ID = B_ID;
左连接要满足连接条件的记录,同时还要左表中的所有记录。使用 null 值来补右表中不满足条件的字段值。
右外连接查询:
From A right join B on A_B_ID = B_ID;
右连接要满足连接条件的记录 ,同时还要右表中所有记录。使用 null 值来补左表中不满足条件的字段值。
完全外连接查询:
From A full join B on a_b_id = b_id ;
完全连接要满足连接条件的记录,同时还要左表和右表中的所有记录。使用 null 值来补全不满足条件的字段值。
Oracle 数据库中对多表查询的扩展:
- 内连
select * from A,B where a_b_id=b_id;
- 左连接
select * from A,B where a_b_id=b_id(+);
- 右连接
select * from A,B where a_b_id(+)=b_id;
- 自连接
自连接:一种数据表结构。
自连接:自己连接自己的数据表结构。
自连接:自己表中的外键字段,引用自己表中的主键字段的数据表结构。
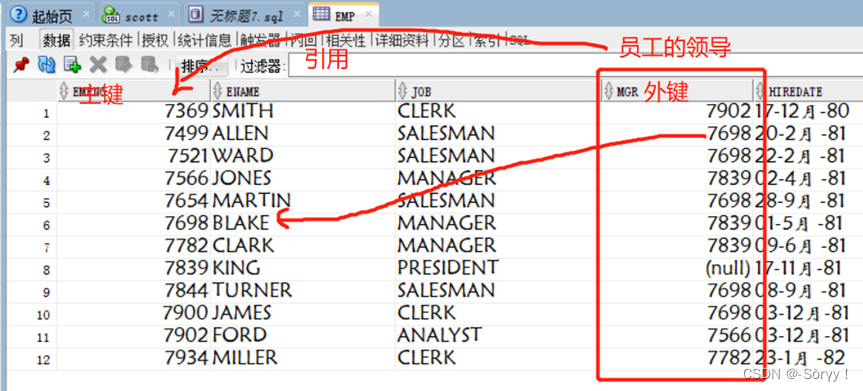
为什么使用自连接方式?
举例说明:
在此表中,如果分级发生变化,只用在类型 id 添加记录即可,无须再修改表的结构。例如:小米手机,父类id:1。

商品表:商品 id,商品名称,商品价格,类型 id
自连接:
下图中可以看出,本表中的外键引用了本表中的主键约束。
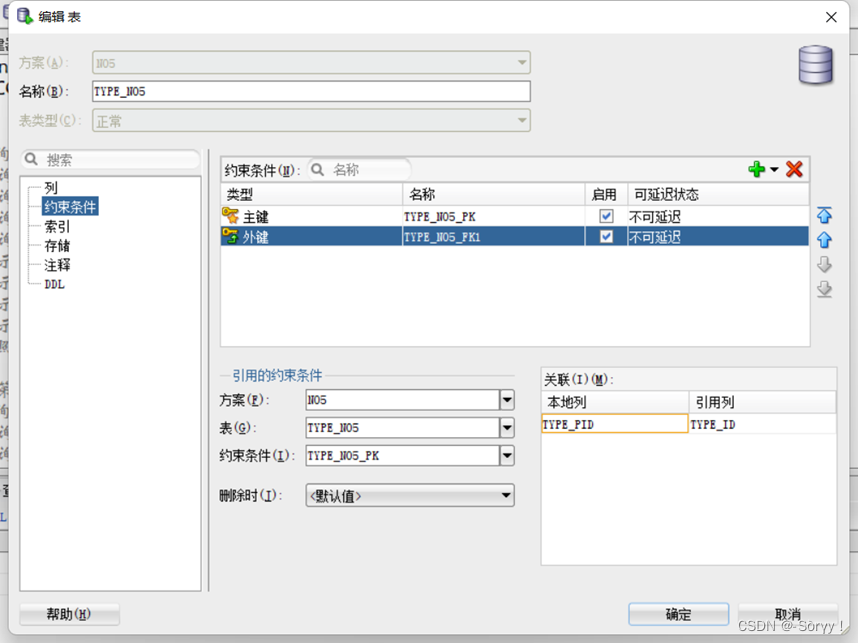
自连接的查询:
示例:
select e1.empno,e1.ename,e1.mgr,e2.ename
from emp e1 left join emp e2
on e1.mgr=e2.empno;
一定要为两张相同的表创建不同的别名。
扩展类型表:
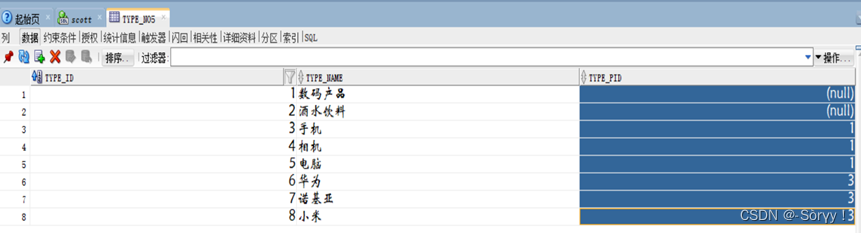
有一个商品是属于类型编号8的商品。
要求按类型编号1(数码产品)查询所有的商品应该怎么查?
在类型表中加入一些重要字段。
Type_level 表示级别
Type_path 表示路径
在自连接表结构中,针对第一级(顶级)和其他子类的操作一定是不相同的。
- 第一级(顶级)
type_pid=null , type_level = 1 , type_path = ‘|自己的ID|’ - 其他子类
先确定是哪一个节点的子级。(例如:为4节点增加一个子级—卡片机)
type_pid = 4 , type_level = 3(父节点level+1 ) , type_path = ‘|1|4|9|’ (父节点path|自己的ID|)
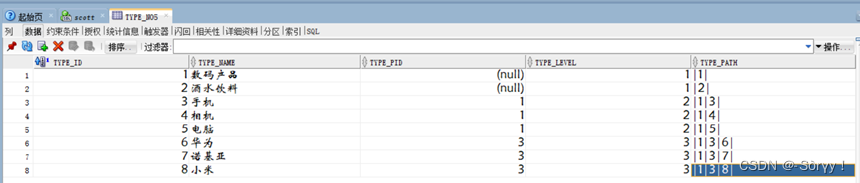
此时就可以通过模糊查询的方式来确定所有的数码产品及其子产品。
然后使用子查询来查询商品中是数码产品的商品。
查询语句如下所示:
select * from goods_no5 where goods_type_id
in(
select type_id from type_no5 where type_path like '%|1|%'
);
- group by 子句-分组查询
分组:将数据按指定的字段,将相同的值分成一组。
select ?
from 表
group by 分组字段
在数据库中,分组之后,每一组的多条记录,就为当成一个整体。
每一组只能提供一个整体的数据。例如:每组的人数是多少,总分是多少。
因为每组只有能一个结果。分组之后。每一组只能是一行数据。
在使用select子句时,只能出现整体的数据(人数,总分,平均分,最大,最小)和分组字段。
- 分组字段
select deptno from emp group by deptno;
select job from emp group by job;
- 整体的数据
select dept.deptno,dept.dname,dept.loc
from emp left join dept on emp.deptno = dept.deptno
group by dept.deptno,dept.dname,dept.loc;
- 聚合函数
- Count(字段) 计数 统计非 null 的个数。
select count(*) from emp; --所有行数,因为主键是非空不唯一
select count(comm) from emp; --4.因为有8个null
- Sum(字段) 求和。
- Avg(字段) 平均值。
select count(comm) , sum(comm) , avg(comm) from emp;
- Min(字段) 最小值。
- Max(字段) 最大值。
聚合函数 一般都要配合分组一起使用。当一起使用时,表示每组进行单独的统计。
select deptno,count(*),sum(sal) from emp group by deptno;
- 分组过滤条件-having
Having 的过滤是在分组聚合之后,将分组聚合之后的数据进行记录的过滤。
举例如下:
- 显示各个部门经理(‘MANAGER’)的工资,并显示低于2500的记录
select deptno,sum(sal) from emp
where job = 'MANAGER'
group by deptno
having sum(sal) < 2500 ;
- 查出平均工资大于2000的部门
select deptno,avg(sal)
from emp
group by deptno
having avg(sal) > 2000 ;
- 查询出有3个以上下属的员工信息(分级查询-having)
select e2.empno,e2.ename,e2.job , count(*)
from emp e1 left join emp e2 on e1.mgr = e2.empno
group by e2.empno,e2.ename,e2.job
having count(*) > 3 ;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









