









sql笔记
目录
文章目录
数据库基本概念
数据库是一个按照某种有组织的方式存储的数据集合。
数据库软件
数据库软件指的是数据库管理系统(DBMS)。通过这个软件可以对数据库进行操作。
表
表,是一种结构化的文件,可以用来存储某种特定类型的数据。可以想象是一个Excel表格,有行,有列。
例如这样的表:
| 学号 | 姓名 | 年龄 |
|---|---|---|
| 0001 | A | 19 |
| 0002 | B | 19 |
在数据库中,列可以叫做一个表中的字段。而行可以叫做一条记录。
很好理解,例如这个表里面记录地有学号信息、那么它就是有一个学号字段。每一行是一个人的信息,也可以称作是一条记录。
模式
存储在数据库中的表具有一些其他的特征,例如数据在表中如何存储,存储什么样的数据等信息,这些信息叫做模式。模式可以用来描述数据库中特定的表,也可以用来描述数据库。
主键
表中的每一行(每一条记录)都应该有一列(或几列的数据可以唯一标识自己),这样的列叫做主键。
例如在记录学生信息的标志中,学号就是唯一标识一个学生的主键。
表中的任何列都可以成为主键,只要它满足一下条件:
- 任意两行的主键值不同。
- 每一行必须有主键,主键不能为空。
- 主键的值不允许修改或更新。
- 主键值不能重用。
sql
sql(Structured Query Language)结构化查询语言。是一种住纳闷用来与数据库沟通交流的语言。
不同的DBMS厂商可能会对sql做扩展,这些扩展只针对个别DBMS,并不通用。标准的sql是ANSI sql。
关于标准化组织见上一篇《TCP/IP协议族–其他协议》
学习sql的最好办法就是自己动手实践。
关于例子
数据库bookstore 主要有表book、user、admin。
检索数据(查询)
select语句用于查询,从哪儿查、查哪些?
检索单个列
select bookname
from book;
--这是注释
--从book表中,查找bookname字段(这一列)的数据。
检索多个列
select bookname,sellerid
from book;
--查询多个列,列名之间要用逗号隔开。
检索所有列
select *
from book;
--*(通配符)代表查询bookstore中的所有数据。
不要重复值
select dinstinct sellerid
from book;
--原本表中每一行的sellerid有重复值,加上dinstinct之后不会显示重复值。
限制结果
只要前5行
select bookname
from book
limit 5;
-- MySQL、MariaDB、PostgreSQL或者 SQLite适用。
select bookname
from book
WHERE ROWNUM <=5;
--oracle适用。
SELECT TOP 5 bookname
FROM book;
-- SQL Server和 Access适用。
SELECT prod_name
FROM Products
LIMIT 5 OFFSET 4;
--从第4行开始5个(行数从0开始计数)
--可以简写为,MySQL和MariaDB支持 LIMIT 4 OFFSET 3 简写为 LIMIT 3,4
SELECT prod_name
FROM Products
LIMIT 4,5;
注释
--标准注释
#注释
/*多行
注释*/
一些注意
- 如果没有明确指出排序查询结果,则返回的结果顺序未知。(不一定是添加的顺序)
- 结束sql语句用分号;。多条sql语句之间必须以分号分割。
- sql语句不区分大小写,关键字(保留字)写作大写可以使结构看起来清晰,到那时大写英文不容易一眼看出意思。
- sql中不考虑空格和换行(当然,两个‘单词’之间不能没有空格)上述写法一条sql语句占据多行。这样可以便于理解。
- 尽量避免使用通配符*。
- 上面说的“看起来清楚、便于理解”都是给人看的,对于机器来说,都一样。
排序检索数据
使用order by子句
select price
from book
order by price;
--按照价格排序,默认升序。
--按照price排序却不一定要检索price
select price
from book
order by price desc;
--降序
select price
from book
order by sellerid,price;
--两个排序条件,用逗号隔开,在前面的优先级高。
select price,sellerid
from book
order by 1,2;
--按相对位置排序,不建议使用。
--在指定一条 ORDER BY 子句时,应该保证它是 SELECT 语句中最后一
--条子句。
过滤数据
使用 WHERE 子句
过滤数据:只检索满足某些条件的数据。
select bookname,price
from book
where price<=30
order by price;
--order by位于最后。
seselect bookname,price
from book
where price between 5 and 10;
建议直接在检索时过滤数据,而不是检索出所有的数据再交由客户端(相对的客户端,或开发语言)处理结果。原因:数据量达,影响性能;占用网络带宽;不仅有伸缩性。

一些注意
当我们过滤调价是字符串时,要用单引号将字符串内容限定起来。
select bookname,price,sellerid
from book
where bookname='sql';
空值NULL(null)。
不同于未知(unknown)不知道是否匹配
不同于空字符串""
select bookname,price
from book
where author is null;
高级数据过滤
组合 WHERE 子句
select bookname,price
from book
where sellerid=1 and price<30;
操作符
and 用来指示需要满足and连接的所有条件的行。
or 用来知名满足or连接的任意一个条件的行。
and优先级比or高,可以用括号来提高优先级。
select bookanme,price
from book
where (sellerid = 1 or sellerid = 2)
and price<=30;
IN 操作符
in操作符指明范围。
select bookname,price
from book
where sellerid in (1,2,3)
NOT 操作符
not操作符否定其后面所跟的条件。
select bookname,price
from book
where not sellerid = 1;
用通配符进行过滤
like通配符
通配符不只有*。通配符指的是用来匹配值的一部分的特殊字符。
搜索模式;由字面量、通配符或两者结合构成的搜索条件。
谓词:操作符何时不是操作符?答案是,它作为谓词时。从技术上说, LIKE 是谓词而不是操作符。虽然最终的结果是相同的。
%通配符
%表示任何字符主线任意次数(0次、1次、多次)
select bookname
from book
where bookname like 'ja%';
--在字符串的匹配中是区分大小写的,也就是说java会被匹配但Java不会被匹配。
下划线(_)通配符
_表示任意单个字符。
方括号([])通配符
例如[ab]可以匹配a或b。
只有微软的 Access 和 SQL Server 支持集合。
[^ab]匹配处理ab之外的。
Microsoft Access用[!ab]
一些注意
不要过度使用通配符。
计算字段
我们可以直接得到数据库中的数据经过转换、计算或格式化之后的数据。而不是检索出原始数据再由客户端格式化。
计算字段是在运行select语句内创建的。
拼接字段
Access和 SQL Server使用 + 号。DB2、Oracle、PostgreSQL、SQLite和
Open Office Base 使用 ||。MySQL则使用 Concat() 函数来实现。
select concat(bookname,'(',author,')')
from book;

RTrim():删除数据右侧多余的空格。
LTrim():删除数据左侧多余的空格。
别名
按照上述方式得到的列名很长,可以这个得到的新列起一个别名。

select concat(bookname,'(',author,')') as name_author
from book;

别名可以使一个单词也可以是一个字符串,如果是字符串,应该括在括号里,但是不建议用字符串。
执行算术计算
select price*number as allprice
from book;
+、-、*、/运算都可以。
select本身可以执行运算
select 2*3;
--不需要from,得到6。
使用函数处理数据
函数
例如之前提到的concat()、RTrim()就是函数。
不同的DBMS支持的函数语法不同,函数是不可移植的。
可移植(portable)所编写的代码可以在多个系统上运行。
文本处理函数
select upper(bookname) as up_name
from book;
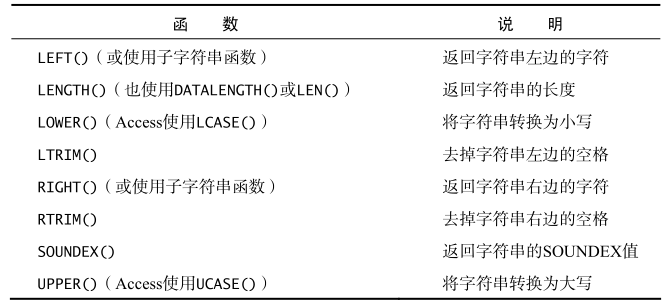
soundex函数
匹配发音相似的数据。
Microsoft Access 和 PostgreSQL 不支持 SOUNDEX()
select bookname
from book
where soundex(bookname)=soundex('jave');
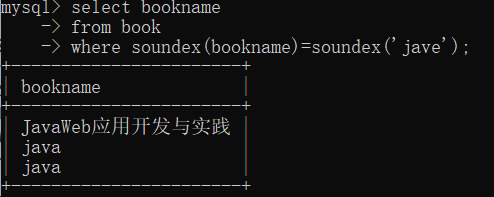
--我用的mysql8.0.0支持中文,但有些时候不太灵。
select bookname
from book
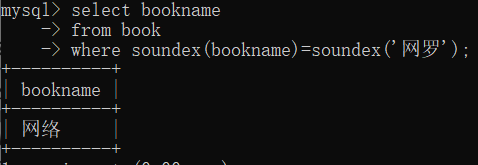
where soundex(bookname)=soundex('网罗');
select bookname
from book
where soundex(bookname)=soundex('火者');
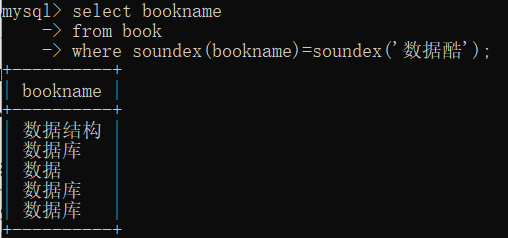
日期和时间处理函数
不同数据库差别较大。
mysql中的时间处理函数
now() 函数获取当前时间。
year() , month(),dayofmonth() 分别从一个日期或者时间中提取出年 ,月 ,日。
monthname() 函数输出个月份的英文单词。
timestampdiff() 函数比较两个日期间的差值。
to_days()将日期转换成天数。
date_add 和 date_sub是根据一个日期 ,计算出另一个日期。
其他数据库中的时间处理函数
SELECT order_num
FROM Orders
WHERE DATEPART('yyyy', order_date) = 2012;
SQL Server和Sybase版本以及Access版本)使用了 DATEPART()函数
数值处理函数

分组函数
group by 子句和having 子句。
汇总数据
select count(*) as num_book
from book;
--检索出表中数据总数
创建分组
select sellerid,count(*) as num_seller_book
from book
group by sellerid;
--将数据以sellerid分组,sellerid相同的为一组。
--GROUP BY 子句必须出现在 WHERE 子句之后, ORDER BY 子句之前。
过滤分组
当过滤分组时不能使用where进行过滤。使用having。
之前提到的where的语法都适用于having知识有一些关键字不同。
select sellerid,count(*) as num_seller_book
from book
group by sellerid
having count(*)>=2;
where在数据分组前进行过滤,而having在数据分组之后过滤。
select sellerid,count(*) as num_seller_book
from book
where price<=30
group by sellerid
having count(*)>=2;
select sellerid,count(*) as num_seller_book
from book
where price<=30
group by sellerid
having count(*)>=2
order by sellerid;
--完全体
--其中可以看出select中各个子句的顺序
select中各个子句的顺序

使用子查询
子查询就是嵌套在其他查询中的查询。
利用子查询进行过滤
select bookname,price
from book
where sellerid in (select id
from user
where name='ycy');
--查询user中ycy对应的id,并用这个查询结果作为查找书籍信息的条件。
--作为子查询的select语句只能查询单个列。
子查询总是由内向外进行的。
作为计算字段使用子查询
select name,(select count(*)
from book
where user.id=book.sellerid) as num_book
from user;
--查询每个用户的正在出售书籍数量
--user.id和book.sellerid是完全限定名。
--为了防止对多个表进行查询时列名冲突。(例如大多数的表都有id列)
联结表
连接表是sql最强大的功能之一。联结是逻辑上存在的而不是物理实体。
一般来说,我们为了避免数据冗余,会将数据分贝存储在多个表中。例如存储书籍信息时如果对于每一行数据,都存储出售者的详细信息,而每个出售者大多都不会只有一本书籍要出售。因此我们将用户信息单独摘除,存储在一个user表,通过book中的sellerid找到对应的出售者。
将数据分解为多个表存储,能够更有效地存储、更方便地处理、伸缩性更好。
可伸缩(scale)能够适应不断增加的工作量而不失败。设计良好的数据库或应用程序称为可伸缩性好(scale well)。
如果数据存储在多个表中,通过联结可以实现一条 SELECT 语句就检索出数据。
select bookname,price,sellerid
from book,user
where book.sellerid=user.id;
--多个表之间用逗号隔开
--检索出book表中的sellerid和user表中的id一样的数据。换言之如果某个书籍的出售者id在user表中找不到(一般不会有这种情况)或者某个用户没有对应的出售书籍,那么这些信息不会出现在检索结果中。
select bookname,price,sellerid
from book,user;
创建联结时,实际上做的是将第一个表中的每一行与第二个表中的每一行做配对并且通过where条件进行过滤。保证所有的联结都有where子句。(联结实际上指的是在from中列出两个表,而不是where中的条件)
如果不过滤得到的是笛卡尔积。
笛卡尔积的个数是第一个表中的行数乘以第二个表中的行数。
上面这种联结也叫内联结。
内联结的另一种语句
select bookname,price,sellerid
from book inner join user
on book.sellerid=user.id;
--ANSI SQL
--这样能更好地看出联结的真实含义。
高级联结
表别名
处理可以给计算出来的字段起别名外,我们还可以给表起一个别名,甚至可以给一个表起两个别名,当做两个表来用。
select bookname,price
from book as b,user as u
where b.sellerid=u.id
and b.price<=30;
--与列别名不同的是,表别名只在搜索时存在,用户用表别名在检索结果处无差别
--(如果使用列别名则结果的列名会变)。
Oracle 中没有 AS
其他联结
处理上面的内联结(或等值联结)外还有三种其他联结:
- 自联结
- 自然联结
- 外联结
自联结
例如:从book表中找出与《java》这本书的sellerid相同的全部书籍信息。
select b1.bookname,b2.price,b2.sellerid
from book as b1,book as b2
where b1.sellerid=b2.sellerid
and b1.bookname='java';
--用两个不同的名字标识表book,
--注意要用b2.bookname,如果用b1.bookname则只会得到'java',如果只用
--bookname则会出问题,因为不知道你要的是哪一个bookname。
--当然,这种平旷也可以用子查询先找出'java'的sellerid然后用这个sellerid去
--找到所有的书籍。但是联结处理要比子查询快得多。
自然联结
对于任何表进行联结,至少应该有不止一列出现在一个表中(被联结的列)。标准的连接返回所有的数据,以至于相同的列返回多次。自然联结排除多次出现,使得每一列只返回一次。
实现:一般只对一个列使用通配符(select *)而对其他列使用明确的子集。
SELECT b.*, u.name
FROM book as b,user as u
WHERE b.sellerid=u.id
AND bookname = 'java';
事实上,我们迄今为止建立的每个内联结都是自然联结,很可能永远都不会用到不是自然联结的内联结。
外联结
许多联结将一个表中的行与另一个表中的行相关联,但有些时候需要包含哪些没有关联行的那些行。
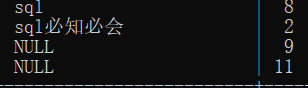
例如:当我们将book表与user表联结时(通过book.sellerid=user.id过滤条件),如果用户a没有要出售的书籍(在“联结表”这一部分的例子中提到),那么则结果包括这个数据。使用外联结可以检索出没有出售书籍的用户在内的所有用户。
select book.bookname,user.id
from user left outer join book
on user.id=book.sellerid;
--left值得是outer join左边的表,同理 如果是right则指的是outer join右边的表。
--上面两种成为左外联结和右外联结,总是有这两种基本的外联结。
--left outer join 表示从from子句左边的表(user表)中选择所有的列。
--看查询结果,出现了9号和11号用户,他们没有要出售的书籍。
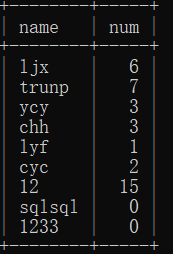
使用带聚集函数的联结
select user.name,count(book.bookname) as num
from user left outer join book
on user.id=book.sellerid
group by user.id;
--建立外联结后,以user的id分组,得出每个用户所出售的书籍的数量。
组合查询
sql允许执行多个查询,并将结果作为一个查询结果集返回。(并查询或复合查询)
适用情况:
- 在一个查询中从不同的表返回结果
- 对一个表执行多个查询,按照一个查询返回结果
多个where子句的select语句也可以看做是一个组合查询。
使用 UNION
在多条select语句中间放上关键词union。
select bookname,price
from book
where price <=20
union
select bookname,price
from book
where bookname like '计算%';
--返回满足price<=20和满足名字以'计算'开头的数据的相加(不包括重复)
--相当于使用or连接两个条件。
UNION 规则
- n条select语句之间用(n-1)个union连接。
- union中的每个查询必须包含相同的列、表达式或聚类函数(列顺序可以不同)。
- 对列的数据类型必须兼容。
包含或取消重复的行
如果把上面那个例子中的union换成 union all,则结果中有全部的匹配行(包括重复行),where子句无法实现。
select bookname,price
from book
where price <=20
union all
select bookname,price
from book
where bookname like '计算%';
对组合查询结果排序
在使用union后只能用一条order by语句,且order by语句必须放在最后一条select语句中。实际上它是对整个结果进行排序。
插入数据
使用insert语句插入数据。
插入完整的行
insert into user
values(null, --id设置的有默认子自增1,所以这里置为空即可
'newuser', --用户名
'12345678',
'12345',
'aabb@163.com',
''); --插入的是空字符串
insert into user(id,
name,
phone,
password,
contact,
picture)
values(null,
'newuser',
'12345678',
'12345',
'aabb@163.com',
'');
--这种写法与上面那种一样,但是推荐这样写,因为上面那种写法会归于依赖列之间
--的位置关系。这种办法,即使表结构改变,这条insert鱼护依然能正常工作。
也可以对部分行插入
insert into user(name,
password)
values('abcc',
'123');
--注意省略的列需要允许设为空值或有默认值。
插入检索出的数据
insert into user(name,
password)
select admin_name,admin_password
from admin;
--从admin表中获取出name和password并将它们插入到user中。
--select的列名与insert插入的列名通过语句中的相对位置对应。
从一个表复制到另一个表
SELECT INTO语句将一个表的内容复制到一个全新的表中(创建并复制)。
CREATE TABLE newuser
LIKE user;
select *
into uservupy
from user;
--这两个先后用是mysql的语法。
--有的数据库只需要
select *
into uservupy
from user;
--就可以。
更新和删除数据
使用update语句更新
更新数据需要响应的权限。
update user
set phone='123456789'
where id=9;
--将user表中id为9的行的phone值更新(修改)为'123456789'。
update user
set phone='123456789',
contact='aabb@163.com'
where id=9;
--同时更新多个列的值。
update语句中可以使用子查询,使得用select语句检索出来的数据更新列数据。
使用delete语句删除数据
删除数据也需要相应的权限。
delete from user
where id=11;
在添加有外键时,DBMS通常可以防止删除某个关系需要用到的列。
--删除所有的行(但不删除表本身,delete也不能删除表本身)用
truncate newuser;
--它比delete快。
更新和删除的指导原则
- 除非确实打算更新或删除每一行,否则绝对不适用不带where的更新或删除语句。
- 尽可能多使用主键.
- 在更新或删除语句使用where子句前,应该先用select进行测试,保证它过滤的是正确的记录。
- 如果可以、数据库管理员采用约束,防止不带where子句的更新和删除语句。
- 使用强制实施引用完整性的数据库。
创建和操纵表
使用create table创建表
create table orders
(
orderid integer(10) not null,
bookid integer(10) not null,
buyerid integer(10) not null,
quantity integer default 1
);
--not null指明这一列不能为空。
--default 1设置默认值为1。
--MySQL 用户指定 DEFAULT CURRENT_DATE()指定默认时间。
尽量是用default而不是null。
alter table更新表
因为更新表示表中可能已经有数据,而更新表的结构性质会引起与已有数据的冲突或不匹配,因此并非所有的更新操作都能实现。
给已有表增加列可能是所有 DBMS都支持的唯一操作。
alter table orders
add advice varchar(20);
--增加一列。
一下操作并非所有DBMS都支持。
alter table orders
drop column advice;
--删除一列。mysql支持。
--使用alter table要极为小心,应该在进行改动前做完整的备份。
drop table删除表
drop table orders;
--删除表没有确认,也不能撤销,执行这条语句将永久删除该表。
重命名表
DB2、MariaDB、MySQL、Oracle和 PostgreSQL用户使用 RENAME语句,SQL Server用户使用 sp_rename 存储过程,SQLite用户使用 ALTER TABLE 语句。
使用视图
视图是虚拟的表,视图只包含使用时动态检索的查询。
简单来说就是把一个插叙包装成一个虚拟表并给它一个名字。
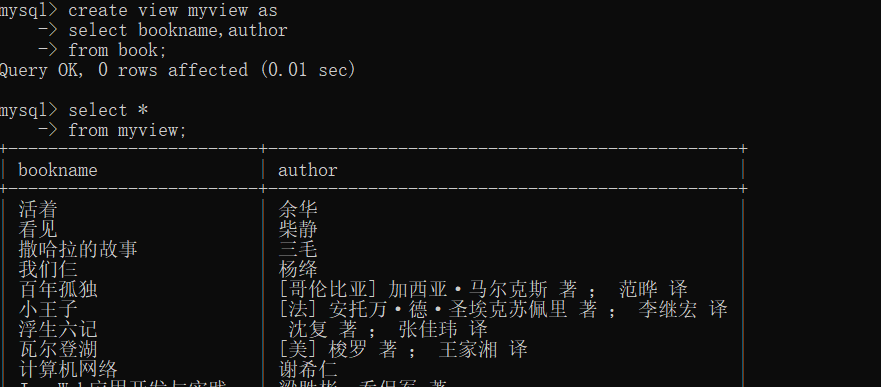
create view myview as
select bookname,author
from book;
--创建视图
select *
from myview;
--对视图进行查找。
mysql视图的定义在from关键字后面不能包含子查询,对于mysql修改了视图,对基表数据有影响,修改了基表,对视图也有影响。
使用视图的好处:
- 简化sql操作,相当于封装。
- 使用表的一部分而不是整个表。
- 保护数据。
- 更改数据格式与表示。
在添加或更改这些表中的数据时,视图将返回改变过的数据。
视图可以嵌套。
但是视图并不拥有像表一样全部的操作,视图的操作受限。
drop view myview;
视图的一个重要用途是重新格式化检索出的数据。
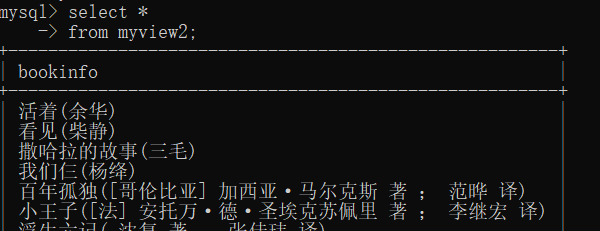
create view myview2 as
select concat(bookname,'(',author,')') as bookinfo
from book;
create view myview3 as
select concat(bookname,'(',author,')') as bookinfo
from book
where price<=20;
--用视图过滤不想要的数据。
create view myview4 as
select concat(bookname,'(',author,')') as bookinfo,
number*price as allprice
from book;
--使用视图与计算字段。
使用存储过程
存储过程指的是为了以后使用而保存的一条或多条sql语句。
为什么使用存储过程:
- 简化复杂的操作。
- 保证了数据的一致性。
- 简化对变动的管理。
- 存储过程通常以编译过的形式存储,所以 DBMS处理命令所需的工作量少,提高了性能。
- 存在一些只能用在单个请求中的 SQL元素和特性,存储过程可以使用它们来编写功能更强更灵活的代码。
简单、安全、高性能。
存储过程一般不可移植,不同的DBMS支持的语法不同。
存储过程各个数据库差异较大,这里只说概念,在之后的数据库相关的介绍中再具体到不同的数据库。
管理事务处理
事务处理指的是通过确保成批的sql操作要么都执行、要么都不执行,来维护数据库的完整性。(原子操作)
例如在购买书籍操作时,需要执行以下操作:
- 将原书籍数据从book表中删除。
- 在订单表中插入一列。
如果在执行完1之后发生问题而语句2并未执行,那么此时数据库处在一个错误的状态,有一本书的数据“丢了”。因此饿哦们需要这两个语句组成一个事物,要么都执行,要么都不执行。
事务:一组sql语句。
回退:撤销指定sql语句的过程。
提交:将未存储的sql语句结果写入数据库表。
保留点:事务处理中何止的临时占位符,可以对它发布回退。
回退不能回退select、create、drop。
管理事务的关键在于将 SQL语句组分解为逻辑块,并明确规定数据何时应该回退,何时不应该回退。
rollback命令用来回退(撤销)sql语句。
commit用来提交。
细节和操作再说。
游标
游标是一个存储在DBMS服务器上的数据库查询,(它不是select),而是被该语句检索出来的结果集。
游标常见特性:
- 能够标记游标为只读。
- 能够控制可以执行的定向操作(向前、向后等)
- 能够标记某些列为可编辑,而某些列是不可编辑的。
- 可以规定范围。
- 知识DBMS对检索出的数据进行复制,是数据再游标打开和访问期间不变化。
高级 SQL 特性
约束
约束指的是管理如何插入或处理数据数据库数据的规则。
例如:
主键:用来确保一列(或一组列)数据中的值可以作为这一列的唯一标识,且不会改动。
外键:外键是表中的一列,其值必须列在另一表的主键中。也就是说某一列的值
orders(订单)表中书通过buyerid与user表中的特定用户相关联。user中的id是主键。
orders表中buyerid列的合法值为user表中用户的id。
create table orders2
(
orderid integer(10) not null primary key,
bookid integer(10) not null,
buyerid integer(10) not null references user(id)
);
--这个orders2表在buyerid列上定义了一个外键,标识该列智能接受user的主键值。
外键有助防止意外删除。
唯一约束:用来保证一列中的数据是唯一的。(不具有其他如不能为空、不能修修改、不能重用、定义外键、不能有多个这些主键的约束。)
检查约束用来保证一列(或一组列)中的数据满足一组指定的条件。
索引
索引用来排序数据以加快搜索和排序操作的速度。
排序虽然提高了搜索操作的性能,但是降低了数据插入更新删除的性能,在执行这些操作时,数据库需要动态地更新索引。
索引数据可能要占用大量的存储空间。
并非所有数据都适合做索引。
索引需要唯一命名。
触发器
触发器是特殊的存储过程,它在特定的数据库活动发生时自动执行。
触发器与单个的表相关联。
触发器内的代码具有这些数据的访问权:
- insert操作中的所有新数据;
- uodate操作中的所有新数据和旧数据;
- delete操作中删除的数据。
一般来说,约束的处理比触发器快,因此在可能的时候,应该尽量使用约束。
数据库安全
基础是用户授权和身份确认。
一般的保护操作有:
- 对数据库管理功能的访问。
- 对特定数据库或表的访问。
- 访问的类型(只读、对特定的列访问等)。
- 仅通过视图或存储过程访问。
- 创建多层安全措施,允许多种基于登录的访问和控制。
- 限制管理用户账号的能力。
安全性使用sql的grant和revoke语句。
约束指的是管理如何插入或处理数据数据库数据的规则。
例如:
主键:用来确保一列(或一组列)数据中的值可以作为这一列的唯一标识,且不会改动。
外键:外键是表中的一列,其值必须列在另一表的主键中。也就是说某一列的值
orders(订单)表中书通过buyerid与user表中的特定用户相关联。user中的id是主键。
orders表中buyerid列的合法值为user表中用户的id。
create table orders2
(
orderid integer(10) not null primary key,
bookid integer(10) not null,
buyerid integer(10) not null references user(id)
);
--这个orders2表在buyerid列上定义了一个外键,标识该列智能接受user的主键值。
外键有助防止意外删除。
唯一约束:用来保证一列中的数据是唯一的。(不具有其他如不能为空、不能修修改、不能重用、定义外键、不能有多个这些主键的约束。)
检查约束用来保证一列(或一组列)中的数据满足一组指定的条件。
索引
索引用来排序数据以加快搜索和排序操作的速度。
排序虽然提高了搜索操作的性能,但是降低了数据插入更新删除的性能,在执行这些操作时,数据库需要动态地更新索引。
索引数据可能要占用大量的存储空间。
并非所有数据都适合做索引。
索引需要唯一命名。
触发器
触发器是特殊的存储过程,它在特定的数据库活动发生时自动执行。
触发器与单个的表相关联。
触发器内的代码具有这些数据的访问权:
- insert操作中的所有新数据;
- uodate操作中的所有新数据和旧数据;
- delete操作中删除的数据。
一般来说,约束的处理比触发器快,因此在可能的时候,应该尽量使用约束。
数据库安全
基础是用户授权和身份确认。
一般的保护操作有:
- 对数据库管理功能的访问。
- 对特定数据库或表的访问。
- 访问的类型(只读、对特定的列访问等)。
- 仅通过视图或存储过程访问。
- 创建多层安全措施,允许多种基于登录的访问和控制。
- 限制管理用户账号的能力。
安全性使用sql的grant和revoke语句。
本文参考《sql必知必会》第四版

















 144
144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









