




ceph-2集群运行状态异常, 发生时间:2023.10.04 23:24:47,当前值为:HEALTH_ERR 1 scrub errors; Possible data damage: 1 pg inconsistentOSD_SCRUB_ERRORS 1 scrub errorsPG_DAMAGED Possible data damage: 1 pg inconsistent pg 1.d0f is active+clean+inconsistent, acting [221,41,134]
ceph health detail 获取出错的pg号,然后ceph pg repair pg号,暂时修复一下。
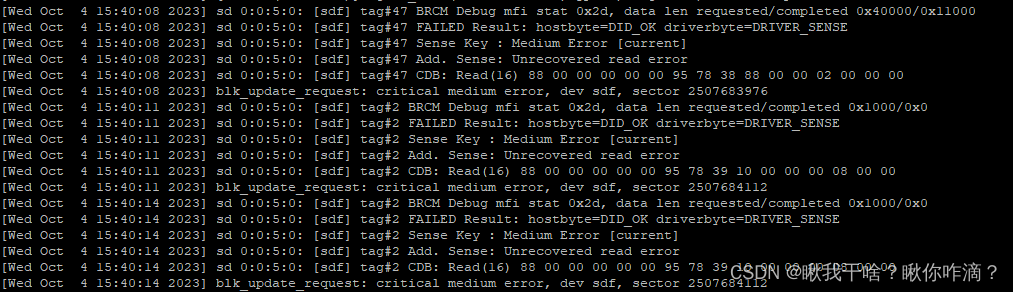
经排查,ceph-2集群报错是因为osd.221硬盘坏道导致数据读取错误,需要把osd.221踢出集群.

















 554
554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









