






生信碱移
单细胞基础模型: 局限性
来自微软研究院的研究者在不进行任何微调的前提下对Geneformer和scGPT进行了系统性评估,发现这些单细胞大语言模型在零样本情况下的性能表现甚至不如简单方法。
基于目前积累的大量单细胞数据,多项单细胞大语言模型被陆续提出。大部分研究者希望借助如scGPT和Geneformer这类预训练大模型,实现细胞类型注释、基因表达预测等多种分析的“自动化”。另外,因为这些大模型都在跨物种/细胞类型上训练,所以被认为能够处理跨批次数据。简单来讲,大语言模型能够从原始表达矩阵中生成具有生物学意义的细胞嵌入向量,用于替代传统的PCA主成分。
需要强调的是,基础模型最强悍的能力之一在于:即使没有任何微调,它们也能基于预训练单细胞数据中获得的信息完成新的任务。尽管如此,在零样本(zero-shot)的情况下,这些模型真的能胜任多种单细胞分析任务吗?零样本是一个常用深度学习术语,即模型只能依赖它在预训练阶段学到的通用知识,而不能借助任务特定的数据或标签进行优化(这也是我们分析的时候常常面临的分析场景)。
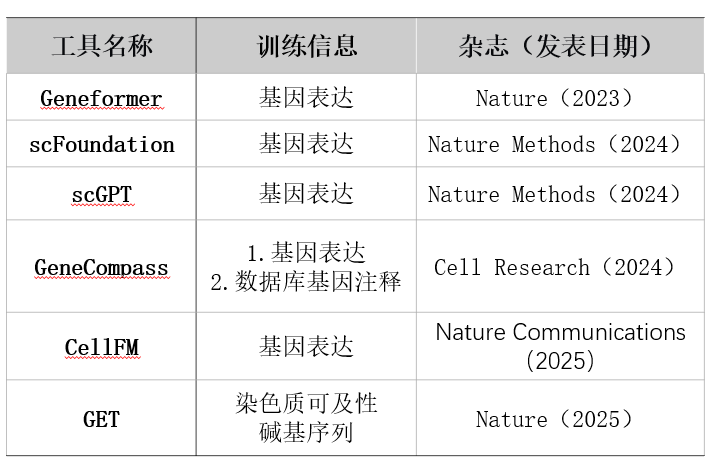
图:目前发表的部分单细胞大语言模型。
为了分析这种情况,来自微软研究院的研究者在不进行任何微调的前提下,对Geneformer和scGPT进行了系统性评估,并将它们的表现与经典方法如scVI、Harmony以及高变基因筛选(传统流程)进行了比较。这项研究于2025年4月18号在Genome Biology[IF:9.4]发表,最终的研究结论是单细胞大语言模型在零样本情况下的性能表现甚至不如简单方法。

DOI:10.1186/s13059-025-03574-x。
简单来讲,作者测试涵盖了五个来源不同、组织不同、技术平台各异的数据集,包括PBMC、胰腺、Tabula Sapiens等。他们衡量的核心指标包括细胞类型聚类质量(AvgBIO)和批次效应整合能力(Batch Mixing)。
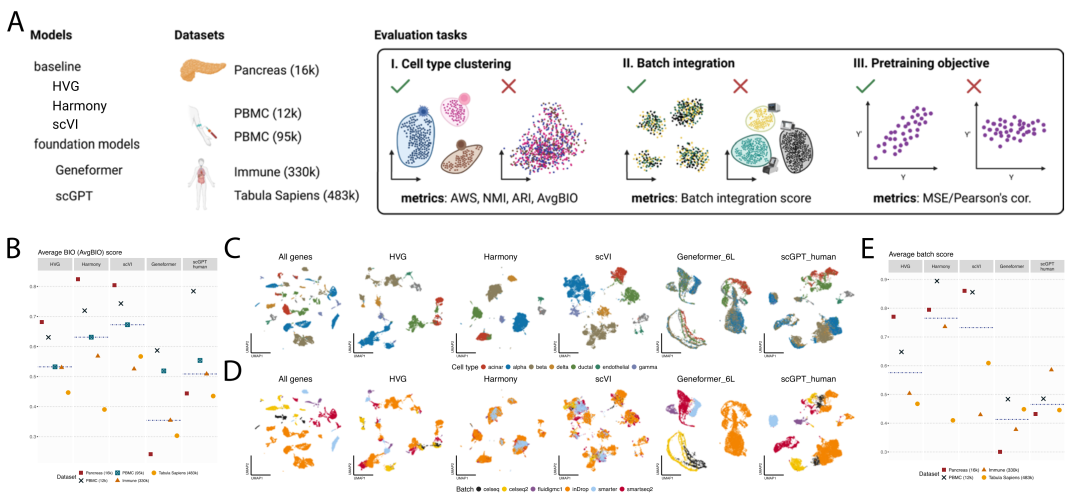
图:单细胞基础模型在零样本设定下的嵌入评估。A.零样本评估流程概览。比较Geneformer与scGPT在未微调情况下对不同单细胞数据集的嵌入效果,基线包括HVG、scVI与Harmony。B.不同方法在五个数据集上的平均生物保真度分数(AvgBIO)。结果显示,HVG、Harmony和scVI普遍优于Geneformer和scGPT。C–D.Pancreas数据集在不同嵌入空间中的UMAP投影,按细胞类型(C)和批次(D)上色。基础模型未能有效分离细胞类型或去除批次效应。E.各方法在五个数据集上的平均批次AvgBatch。HVG与传统方法在批次整合方面整体表现更优,Geneformer显著滞后。
总结一下作者的核心发现:
① 老方法更胜一筹
在细胞类型聚类任务中,scGPT和Geneformer在多个数据集上的表现不如HVG、scVI和Harmony。甚至在这些模型预训练时见过的数据集(例如Tabula Sapiens和Immune)上,它们也无法占据优势。尤其是Geneformer,在所有任务中几乎始终垫底。相比之下,HVG这个看似简单逻辑的特征筛选方法,在多个指标上取得了最佳表现。
进一步对批次整合能力进行评估,作者发现scGPT略有优势,尤其在复杂批次(如技术+生物来源)场景下超越了Harmony和scVI。但总体而言,它仍然难以有效消除实验技术带来的批次差异。而Geneformer在这项任务上几乎完全失效,降维图中主要结构反映的不是生物差异,而是批次效应。
② 模型训练任务可能存在缺陷
scGPT在预测掩码基因表达时几乎只是学习了"平均表达值",即便利用其生成的细胞嵌入进行条件预测,也只能带来微弱提升。对于Geneformer来说,其在重构基因表达排名上略有优势,但仍无法在复杂任务中展现可靠的泛化能力(见第三部分的图③)。
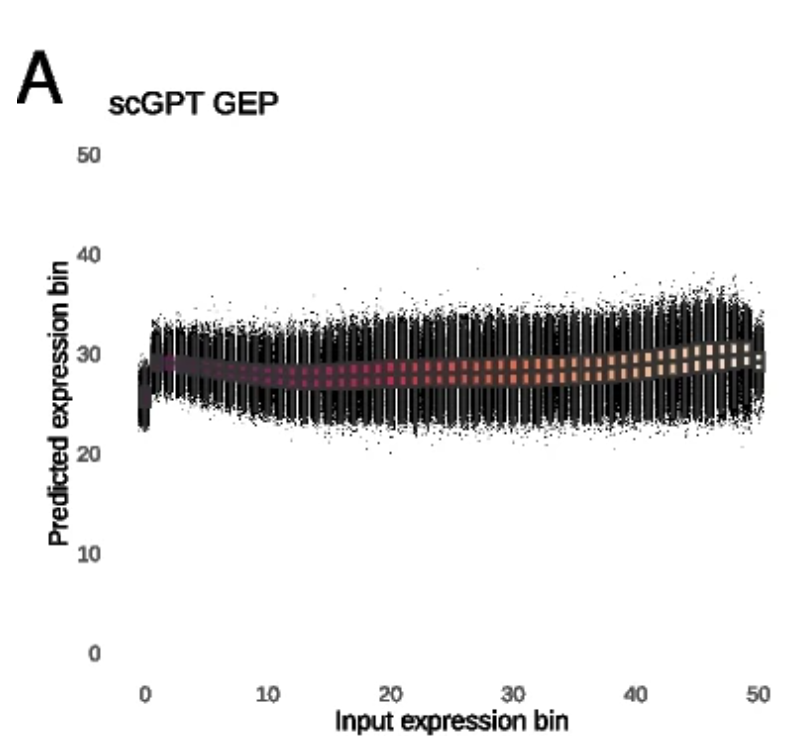
作者认为,基础模型的预训练任务本身可能存在问题,尤其是目前普遍采用的掩码语言建模(MLM)目标,可能无法充分学习细胞间的高阶表达规律。有待提升啊,现在进场发点小文章还是简单的。
③ 基础模型并不是越大越好
作者还评估了scGPT的不同版本,包括预训练于肾脏、血液、全人类非癌细胞的大模型。结果发现,更多的预训练数据和更大的模型尺寸,并不一定能带来更好的泛化能力。例如,scGPT-human(最大规模模型)在多个数据集上反而不如scGPT-blood。逻辑上也是合理的,数据太多,模型也是学习的眼花缭乱了。
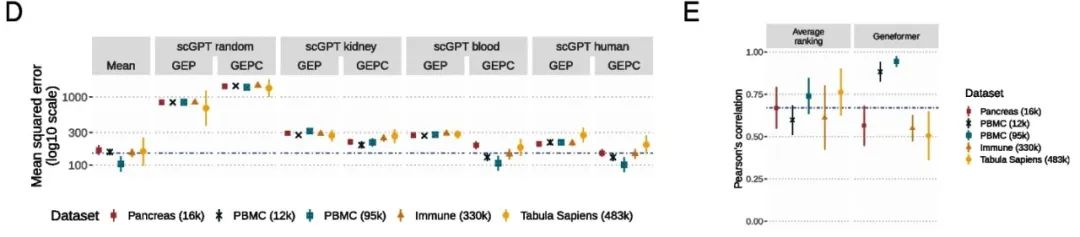
可以看到,当前的单细胞基础模型在不微调的前提下,难以胜过更轻量级、更传统的方法。这与它们在原始论文中宣称的强泛化能力形成了强烈反差。作者呼吁社区构建专用于评估的基准数据集,这些数据不应参与任何模型的预训练,就像自然语言处理领域已有的标准数据集一样。只有这样,研究者才能真正知道模型学到了什么、能做什么,又有哪些能力仍需开发。友情提醒,这种多任务的benchmark数据集估计已经在见刊的路上了。
大模型的训练资源蛮难搞
文章还是能整的
可能得奇思妙想一下了


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









