







一、大模型LLM理论简介
本系列笔记基于 llm-universe,旨在构建知识库,通过LangChain构建RAG应用。非常感谢datawhale 的开源组队学习。
1、大模型理论简介
大模型是大规模参数和复杂计算结构的模型,参数达到十亿乃至上千亿。当参数变多,模型就会出现涌现能力。
1.1总结常见LLM
1.1.1 GPT系列
GPT系列是OpenAI的大语言模型,采用Transformer模型的编码器,而BERT采用解码器。
编码器和解码器的作用
- 编码器:捕捉输入序列的语义信息,通过自注意力层和前馈神经网络层处理输入词汇,以捕捉词汇间的依赖关系和语义信息。
- 解码器:根据编码器的输出和之前的输出生成目标序列,通过自注意力层和前馈神经网络层进行多轮预测,生成新的输出序列。
所以,BERT和GPT使用不同部分的原因及优劣如下:
- BERT:使用编码器,因为其目标是学习上下文相关的词表示,通过双向语言模型预训练来理解词语的语义和上下文信息。
- GPT:使用解码器,因为其目标是生成连贯且适当的上下文文本,通过自回归语言模型预训练来学习生成连贯文本的能力。
- 优劣:
- BERT:在文本理解任务中表现出色,如问答、文本分类等,具有较强的上下文理解能力。
- GPT:在文本生成任务中表现较好,如对话生成、文本生成等,能够生成具有上下文连贯性和逻辑性的文本。
1.1.2 Gemini| 文心一言| 通义千问等10+模型及地址
| 名称 | 开发公司 | 访问地址 | 是否开源 |
|---|---|---|---|
| Gemini | 谷歌 | https://gemini.google.com/ | |
| 文心一言 | 百度 | https://yiyan.baidu.com/ | 是 |
| 通义千问 | 阿里巴巴 | https://tongyi.aliyun.com/ | 是 |
| 星火 | 科大讯飞 | https://xinghuo.xfyun.cn/desk | |
| 豆包 | 字节跳动 | https://www.doubao.com/ | |
| 智谱GLM | 清华大学&智谱 | https://www.zhipuai.cn/ | 是 |
| 盘古 | 华为 | https://pangu.huaweicloud.com/ | |
| 百川 | 百川智能 | https://www.baichuan-ai.com/chat | 是https://github.com/baichuan-inc |
| 元宝 | 腾讯 | https://yuanbao.tencent.com/chat | |
| 商量 | 商汤 | https://platform.sensenova.cn/home#/home | |
| kimi | 月之暗面 | https://kimi.moonshot.cn/ | 是 |
| LLAMA | xxx | xxx | 是 |
1.2 LLM的能力
- 涌现能力
- 上下文学习
- 指令微调
- 逐步推理
- 作为基座模型支持多元应用的能力
- 对话统一入口
1.3 LLM特点
- 大规模参数
- 预训练和微调
- 多场景多模态的应用
2.搜索增强RAG简介
2.1 是什么?为什么?
RAG 是Retrieval-Augmented Generation的简称,是通过搜索知识库辅助大模型生成答案的方法。
由于LLM的幻觉、知识滞后、专业知识欠缺等问题,需要通过RAG来提高生成结果的准确性和专业性。
2.2 工作流程
- 文档加载与分割:从各种来源加载大量文档数据作为知识库,用于后续的信息检索。文档数据会被分割成块,以便进行后续处理。
- 编码与向量化:使用编码模型将这些文档块嵌入到向量中,这样可以将文本数据转换成机器可以处理的数值形式。使得文本数据可以被高效地存储和检索。
- 索引构建:将所有这些向量放入索引中,以便在需要时能够快速检索到与用户查询相关的信息。可以是图数据库、向量数据库等
- 用户查询处理:当用户提出查询时,RAG会使用相同的编码器模型对用户的查询矢量化,然后针对索引执行该查询向量的搜索,找到最相关的结果。
- 结果增强与输出:从数据库中检索相应的文本块,并将它们作为上下文输入到LLM(大型语言模型)提示中,以生成更准确和相关的回答。
2.3 RAG vs FT微调
搜索外部知识库+prompt技术 vs 特定领域知识调参
RAG的成本更低,实时性更好,可解释性更强,适用于多任务场景。
RAG的应用场景:问答系统、文档生成和自动摘要、智能助手和虚拟代理、信息检索、知识图谱填充等。
微调的应用场景:特定任务的数据集较小、模型能力的定制、模型幻觉的降低、可解释性的需求、低延迟的场景、智能设备的场景等。
3. Langchain简介
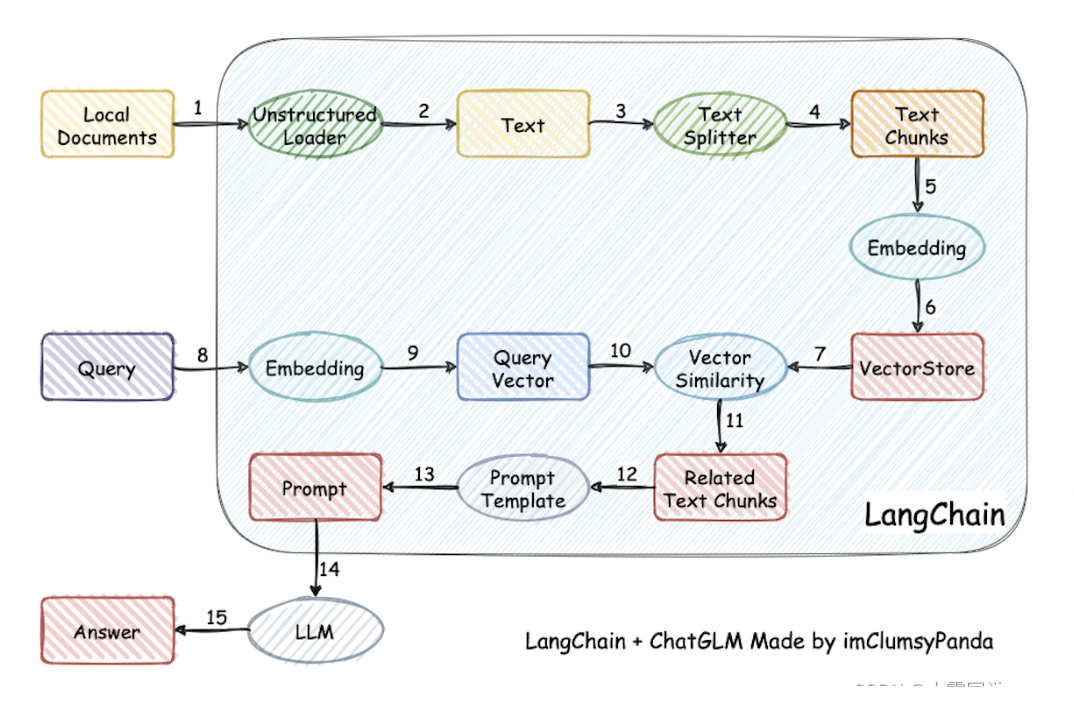
LangChain框架是一个开源工具,能够实现模型与数据来源的连接,允许与环境的交互。上图就是利用LangChain构建RAG,椭圆是模块,方框是数据状态。
作为一个LLM的开发框架,将LLM模型、向量数据库、交互层prompt、外部知识和代理整合在一起,主要组件有6个:
- 模型输入输出接口
- 数据接口
- 链:连接各组件
- 记忆:用于链之间
- 代理 agent: 拓展推理能力
- 回调 callback: 扩展推理能力
4 开发llm应用流程
开发LLM应用,是利用LLM的理解能力和生成能力,作为调用工具,对特殊的数据和业务逻辑进行处理的应用。所以不需要考虑模型的优化以及内部如何运行,只把它当做工具去用。
LLM开发与传统的AI开发在整体思路和评估思路上有很大的不同。
整体思路
- 传统AI:将复杂的业务逻辑拆解成子任务,对每个子任务设计模型,通过训练集训练,对每个子任务在验证集上优化,最后通过完整的模型链来实现业务逻辑。
- LLM开发:通过prompt工程来实现子任务模型的优化,通过prompt链路实现业务逻辑。通过一个基座大模型+若干prompt调优来实现。
评估思路
- 传统AI:设计训练集训练、验证集调优、测试集评估
- LLM开发:从实际业务需求中构造小批量验证集,设计合理的prompt。然后从实际业务中选择bad case 加入到验证集中针对性的优化prompt,以实现泛华效果。
所以,LLM开发流程图如下:

5. 配置环境
5.1 通用环境配置
conda create -n llm-universe python=3.10 #创建虚拟环境
conda activate llm-universe #激活
#进入到想要复制的个人目录 cd /hpc2hdd/home/gbian883
git clone git@github.com:datawhalechina/llm-universe.git #克隆
cd llm-universe #进入目录
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple #安装包
# conda info --envs 查看当前虚拟环境的路径
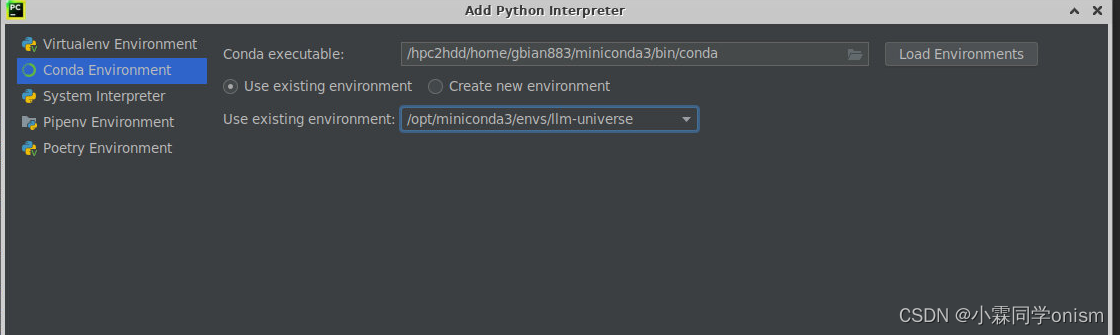
在pycharm中选择这个环境
5.2 nltk库下载
NLTK(Natural Language Toolkit)是一个强大的Python库,用于处理人类语言数据的编程。它提供了简单易用的接口,可以用来进行文本的分词、词性标注、命名实体识别、语义分析等自然语言处理任务。NLTK拥有丰富的模块和大量的语料库,支持多种语言,是自然语言处理领域的标准库之一。通过NLTK,开发者可以轻松实现对文本数据的深度挖掘和分析,为各种应用场景提供支持,如情感分析、机器翻译、智能客服等。
使用方法:
分词:使用 word_tokenize()函数进行分词
词性标注:使用 pos_tag()函数进行词性标注
命名实体识别:使用 ne_chunk()函数进行命名实体识别
句法解析:使用 RegexpParser()或 RecursiveDescentParser()进行句法解析
# cd /root 变成cd /hpc2hdd/home/gbian883
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./ #将packages文件夹中的所有文件和子文件夹移动到当前目录(.表示当前目录)
cd tokenizers
unzip punkt.zip
cd ../taggers #返回到上一级目录,再进入taggers子目录
unzip averaged_perceptron_tagger.zip



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









