



前言
研究生小白 记录音频分类漫长之路
之前跑过一段时间代码,发现只跑别人的代码容易出现很多不理解的地方,并且很多地方自己不会写,所以决定自己学着写一下
一、思路
1- download dataset 2- create data loader 3- build model 4- train 5- save trained model
二、使用步骤
1.引入库
代码如下(示例):
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor2.完整代码
train.py
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
# 1- download dataset
# 2- create data loader
# 3- build model
# 4- train
# 5- save trained model
BATCH_SIZE = 128
Epochs = 10
LEARNING_RATE = 0.001
# 5 创建模型
class FeedForwardNet(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.dense_layers = nn.Sequential( # 允许把多个层打包在一起,并且一层接着一层的运行
nn.Linear(28*28, 256), # 输入和输出,相当于dense() 数据集中的像素是28*28
nn.ReLU(),
nn.Linear(256, 10), # 共有10类
)
self.softmax = nn.Softmax(dim=1)
# 如何处理data
def forward(self, input_data):
flattened_data = self.flatten(input_data)
logits = self.dense_layers(flattened_data)
predictions = self.softmax(logits)
return predictions
def download_minist_datasets():
train_data = datasets.MNIST(
root="data", # 创建存储的目录
download=True, # 如果目录中没有数据集的话就自动下载数据集
train=True,
transform=ToTensor() # 读入我们自己定义的数据预处理操作
)
validation_data = datasets.MNIST( # 验证数据集
root="data",
download=True,
train=False,
transform=ToTensor()
)
return train_data, validation_data
def train_one_epoch(model, data_loader, loss_fn, optimiser, device):
for inputs, targets in data_loader:
inputs, targets = inputs.to(device), targets.to(device)
# calculate loss #每一个batch计算loss
# 使用当前模型获得预测
predictions = model(inputs)
loss = loss_fn(predictions, targets)
# backpropagate loss and update weights
optimiser.zero_grad() # 在每个batch中让梯度重新为0
loss.backward() # 反向传播
optimiser.step()
print(f"Loss: {loss.item()}") # 打印最后的batch的loss
def train(model, data_loader, loss_fn, optimiser, device, epochs):
for i in range(epochs):
print(f"Epoch {i+1}")
train_one_epoch(model, data_loader, loss_fn, optimiser, device)
print("---------------------")
print("Training is down.")
if __name__=="__main__":
# download MNIST dataset
train_data, _ = download_minist_datasets()
print("MNIST dataset downloaded")
# creat a data loader for the train set
train_data_loader = DataLoader(train_data,
batch_size=BATCH_SIZE,
shuffle=True)
# build model
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
print(f"Using {device} device")
feed_forward_net = FeedForwardNet().to(device)
# instantiate loss function + opptimiser
loss_fn = nn.CrossEntropyLoss()
optimiser = torch.optim.Adam(feed_forward_net.parameters(),
lr=LEARNING_RATE)
# train model
train(feed_forward_net, train_data_loader, loss_fn, optimiser, device, Epochs)
# 存储模型
torch.save(feed_forward_net.state_dict(), "feedforwardnet.pth")
print("Model trained and stored at feedforwardnet.pth")输出结果
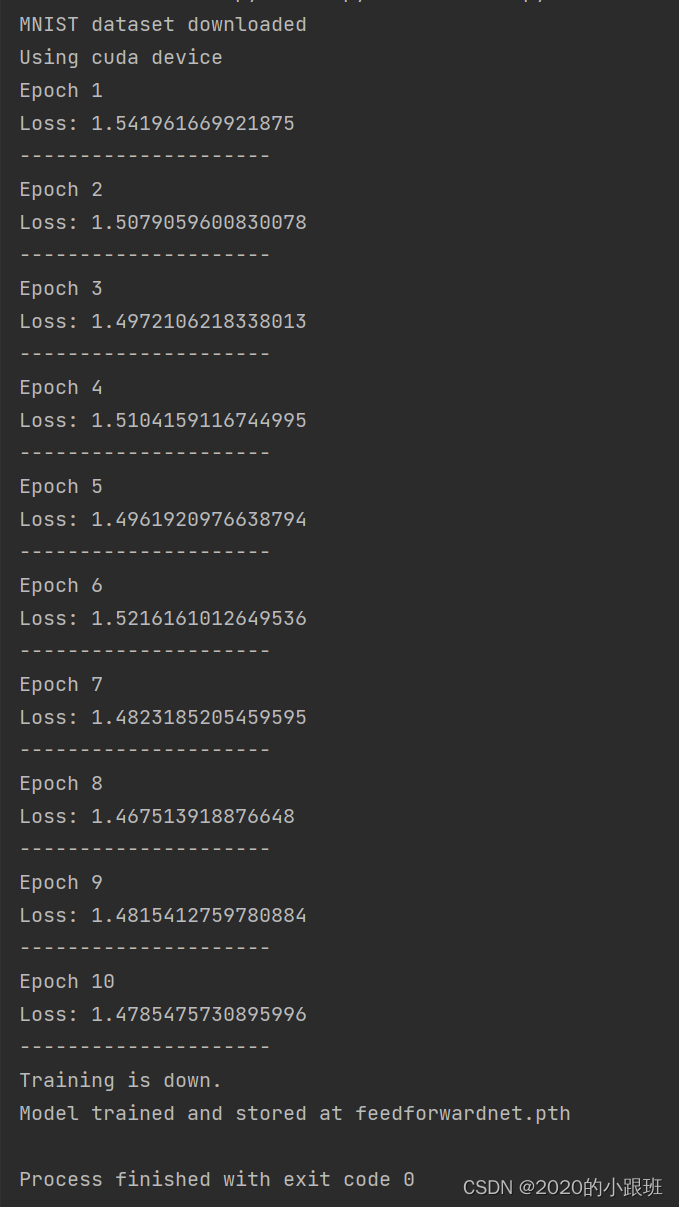
二. 对测试数据进行 测试
inference.py
import torch
from train import FeedForwardNet, download_minist_datasets
class_mapping =[
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9"
]
def predict(model, input, target, class_mapping):
model.eval()
with torch.no_grad():
predictions = model(input)
# Tensor (1, 10) ->[[0.1, 0.01, ... ,0.6]] #概率最大的即为所选
predicted_index = predictions[0].argmax(0)
predicted = class_mapping[predicted_index]
expected = class_mapping[target]
return predicted, expected
if __name__ == "__main__":
# load back the model
feed_forward_net = FeedForwardNet()
state_dict = torch.load("feedforwardnet.pth")
feed_forward_net.load_state_dict(state_dict)
# load MNIST validation dataset
_, validation_data = download_minist_datasets()
# get a sample from the validation dataset for inference
input, target = validation_data[0][0], validation_data[0][1]
# make an inference
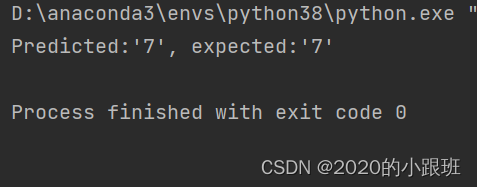
predicted, expected = predict(feed_forward_net, input, target, class_mapping)
print(f"Predicted:'{predicted}', expected:'{expected}'")结果
总结
学会如何调用cuda 跑代码并且学会进行模型训练的基本步骤,但其中并未涉及如何将测试集加入模型进行测试。

















 2701
2701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









