






 本文是Neo4j基础学习笔记,主要介绍了Cypher查询语言的基本用法,包括创建、读取操作,如创建节点、设置标签和属性、查询节点和关系等,帮助理解 Neo4j 的图数据库概念和操作方式。
本文是Neo4j基础学习笔记,主要介绍了Cypher查询语言的基本用法,包括创建、读取操作,如创建节点、设置标签和属性、查询节点和关系等,帮助理解 Neo4j 的图数据库概念和操作方式。
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注。
1、什么是Cypher
Cypher是一种声明式图查询语言,表达高效查询和更新图数据库。Cypher是相对简单的查询语法,它让我们更关注业务领域问题。
2、写
Create:
创建单个节点(注意有个空格):create (节点名)
创建带标签的节点(ID:n,label:Person):
create (别名:标签名{属性名:属性})
create (n:Person{name:”张三”})

创建带两个标签的节点:create (别名:标签1:标签2{属性名:属性})
create (n:Person:student{name:"李四"})

创建带标签、属性的节点:
create (n:Person{name:"王五",age:17})

创建关系(两个节点之间的关系):
match (a:Person),(b:Person) where a.name="张三" and b.name="李四"
create (a)-[r:RELTYPE]->(b) return r

创建关系的同时设置属性:
match (a:Person),(b:Person) where a.name="zhangs" and b.name="lisi"
create (a)-[r:RELTYPE {name:a.name +"<->" + b.name}]->(b) return r

完整创建:三个节点两个关系
create p=(an {name:"an"})-[:WORKS_AT]->(neo)<-[:WORKS_AT]-(mach {name:"mach"}) return p;

Merge(语法类似于create):
与create的区别:对不存在的节点创建,存在的节点返回。
merge (robert:Critic) return robert,labels(robert);

单个属性节点:
merge (charlie {name:"Charlie",age:10}) return charlie;

带标签和属性的单个节点:
merge (michel:Person {name:"michelDoug"}) return michel;

如果要创建节点就设置属性:merge on create
merge (keanu:Person {name:"Keanu"}) on create set keanu.created=timestamp() return keanu;

如果找到节点就设置属性:merge on match
merge (person:Person) on match set person.found=true return person;

如果找到就设置属性,没找到创建节点并设置属性:merge on create on match
merge (keanu:Person {name:"Keanu"}) on create set keanu.created=timestamp() on match set keanu.lastSeen=timestamp() return keanu;
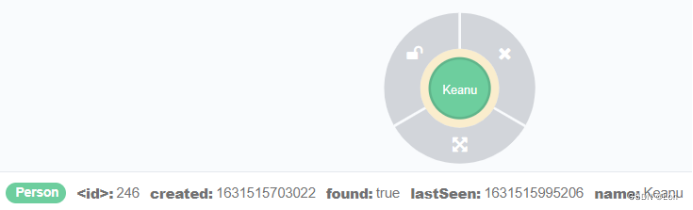
merge on match 多个属性,如果没有属性则创建:
merge (person:Person) on match set person.found=true,person.lastAccessed=timestamp() return person;
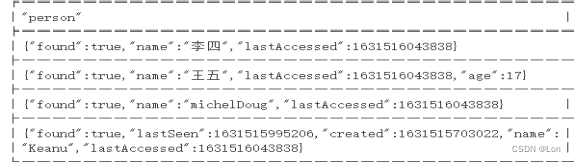
merge (创建或更新)关系:
match (charlie:Person {name:"Charlie"}),(wall:Movie {title:"Wall"})
merge (charlie)-[r:ACTED_AT]->(wall) return r;
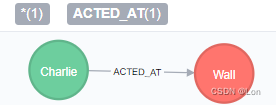
merge多重关系:
MATCH (oliver:Person { name:'Oliver Stone' }),(reiner:Person { name:'Rob Reiner' })
MERGE (oliver)-[:DIRECTED]->(movie:Movie)<-[:ACTED_IN]-(reiner) RETURN movie
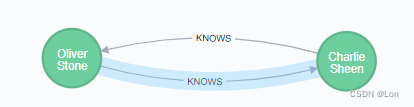
merge非直接关系:
MATCH (charlie:Person { name:'Charlie Sheen' }),(oliver:Person { name:'Oliver Stone' })
MERGE (charlie)-[r:KNOWS]-(oliver) RETURN r;
MATCH (charlie:Person { name:'Charlie Sheen' }),(oliver:Person { name:'Oliver Stone' })
MERGE (charlie)<-[r:KNOWS]-(oliver) RETURN r;
(neo4j默认是从前指向后)
merge 上使用唯一性约束(重复创建会报错):
CREATE CONSTRAINT ON (n:Person) ASSERT n.name IS UNIQUE;
CREATE CONSTRAINT ON (n:Person) ASSERT n.role IS UNIQUE;
MERGE (laurence:Person { name: 'Laurence Fishburne' }) RETURN laurence ;
Set:MATCH (别名{属性名:属性}) SET 别名.属性名=”” return 别名
用于更新一个节点和关系的标签或属性。
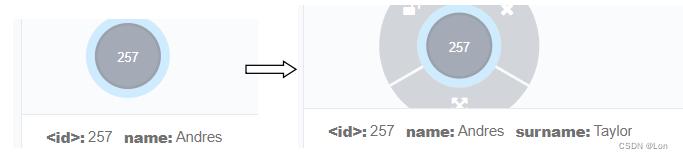
create (n { name: 'Andres' }) ;
MATCH (n { name: 'Andres' }) SET n.surname = 'Taylor' RETURN n;
修改关系名:
MATCH (m:标签名1)-[r:关系属性1]-(m:标签名2) WHERE id(m)=500 and id(n)=401
CREATE (n)-[新关系名:新关系属性]->(m)
DELETE r(原关系别名)
注:neo4j没有函数可以修改关系名,只能通过查询原关系的节点后为其创建一个新的关系,然后再删除原关系
删除属性(将属性修改为null值):
MATCH (n { name: 'Andres' }) SET n.name = NULL RETURN n
在节点和关系之间复制属性:
MATCH (at { name: 'Andres' }),(pn { name: 'Peter' }) SET at = pn RETURN at, pn;
(将at的name属性改为pn的name属性)
从map添加属性:
MATCH (n:peter { name: 'Peter' }) SET n += { hungry: TRUE , position: 'Entrepreneur' }
(为所有name属性为Peter的添加属性hungry和position)
设置多个属性:
MATCH (n { name: ‘Andres’ }) SET n.position = ‘Developer’, n.surname = ‘Taylor’
(可以进行原有的属性修改和新属性的添加)
在节点上加标签:
MATCH (n { name: 'Stefan' }) SET n :German RETURN n
MATCH (n { name: 'Emil' }) SET n :Swedish:Bossman RETURN n
(别名:标签1:标签2…)
DELETE:删除节点和关系
删除单个节点:
MATCH (n:标签名) DELETE n;
删除节点和连接它的关系:
MATCH (n { name: 'Andres' })-[r]-() DELETE n, r
(只删除了此节点和与此节点相连的关系,与此节点相连的节点无影响)
删除所有节点和关系:
MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r
(清空数据库)
REMOVE:删除标签和属性
删除属性:
MATCH (n { name: 属性 }) REMOVE n.属性名 RETURN n;
删除节点的标签:
MATCH (n { name: 属性}) REMOVE n:标签名 RETURN n;
删除多重标签:
MATCH (n { name: 'Peter' }) REMOVE n:标签名1:标签名2 RETURN n;
FOREACH:
为所有节点设置mark属性:
MATCH p =(begin)-[*]->(END )
WHERE begin.name='A' AND END .name='D'
FOREACH (n IN nodes(p)| SET n.marked = TRUE );
(为查到的所有的A->D的关系的节点添加属性marked)
CREATE UNIQUE:创建唯一性节点:
MATCH (root { name: 'root' }) CREATE UNIQUE (root)-[:LOVES]-(someone) RETURN someone
3、读
MATCH:
查询所有节点:
MATCH (n) RETURN n;
查询指定标签的节点:
MATCH (movie:Movie) RETURN movie;
关联节点:
MATCH (n{ name:属性})--(标签名) RETURN 标签名.name
查询标签:
MATCH (charlie:Person { name:'Charlie Sheen' })--(movie:Movie) RETURN movie
关系查询:
MATCH (martin { name:'Martin Sheen' })-->(movie) RETURN movie.title
MATCH p=(Charlie { name:”Charlie”})-[r]->(Movie) RETURN p (查询关系)
通过关系类型查询:
MATCH (wallstreet{ title:'Wall' })<-[:ACTED_AT]-(Person) RETURN Person
OPTIONAL MATCH:与match类似,只是如果没有匹配上,则将使用null作为没有匹配上的模式。类似于SQL中的外连接。
匹配关系:
match (a:Movie {title:"Wall"}) optional match (a)<--(x) return x;
如果没有返回null。
有:
无: 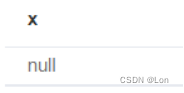
匹配属性:
match (a:Movie {title:"Wall Street"})
optional match (a)-->(x) return x,x.name
WHERE:
MATCH (n)
WHERE n.name = 'Peter' XOR (n.age < 30 AND n.name = "Tobias") OR NOT (n.name = "Tobias" OR n.name="Peter")
RETURN n;
XOR:异或,当两个值相同时,返回FALSE,当两个值不同时,返回TRUE。
过滤标签:
MATCH (n)
WHERE n:person
RETURN n;
过滤属性:
MATCH (n)
WHERE n.age < 30
RETURN n;
MATCH (n)
WHERE HAS (n.belt)
RETURN n;
(暂时没弄懂)
正则:
MATCH (n)
WHERE n.name =~ 'Charlie.*'
RETURN n;
(类似于like)
语法:=~ ”.要匹配的字段.”
在where中使用pattern(模式):
使用and:
MATCH (Charlie {name:'Charlie' }),(others)
WHERE others.name IN ['Andres','Peter'] AND (Charlie)<--(others)
RETURN others
使用not:
MATCH (persons),(peter { name: 'Peter' })
WHERE NOT (persons)-->(peter)
RETURN persons
使用属性:
MATCH (n)
WHERE (n)-[:KNOWS]-({ name:'Charlie' })
RETURN n
关系类型:
MATCH p=(n)-[r]->()
WHERE n.name='Charlie Sheen' AND type(r)=~ 'K.*'
RETURN p
使用IN:
MATCH (a)
WHERE a.name IN ["Peter", "Tobias"]
RETURN a
使用where:
MATCH (n)
WHERE n.name = 'Charlie'
RETURN n
使用or:
MATCH (n)
WHERE n.name = 'Charlie' OR n.name IS NULL RETURN n
ORDER BY n.name
过滤NULL:
MATCH (person)
WHERE person.name = 'Peter' AND person.position IS NULL
RETURN person
索引
创建索引:
CREATE INDEX ON:index_name()
CREATE INDEX ON :Person(name)
删除索引:
drop index on:index_name()
drop index on:person(name)
注:neo4j 4.0版本之后创建索引语法更改:
创建索引
在Neo4j 4.0及以后的版本中,可以使用 CREATE INDEX 命令创建索引:
CREATE INDEX [index_name] FOR (n:label) ON (n.property);
其中:
Index_name:可选,可以为索引指定一个名称。
label:需要创建索引的节点的标签。
property:需要创建索引的属性。
为标签为 Person 的节点的 name 属性创建一个索引:
CREATE INDEX PersonNameIndex FOR (p:Person) ON (p.name)
删除索引
可以使用 DROP INDEX 命令删除索引。语法如下:
DROP INDEX [name]
删除名为 PersonNameIndex 的索引:
DROP INDEX PersonNameIndex
修改索引
可以使用 REBUILD INDEX 命令重建索引。语法如下:
REBUILD INDEX [name]
要重新构建名为 PersonNameIndex 的索引:
REBUILD INDEX PersonNameIndex
显示索引
可以使用 SHOW INDEXES 命令查看所有已创建的索引。语法如下:
SHOW INDEXES

















 948
948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









