







我的机器学习笔记(一)
一、概述;
二、机器学习的类型;
三、机器学习的常见应用;
四、机器学习的工具;
五、机器学习的开发应用。
一、概述
三个概念:
- 人工智能(Artificial Intelligence, AI)
- 机器学习(Machine Learning, ML)
- 深度学习(Deep Learning, DL)
- 机器学习(Machine Learning, ML)
1.1 人工智能 – AI
描述一个模仿人脑认知功能的概念或系统,可以从经验中学习,可以通过使用知识来执行任务、推理和做出决策。
包括:机器学习、自然语言处理、语音合成、计算机视觉、机器人学、传感器分析、优化和模拟。
类型:专家系统、神经网络和模糊逻辑等。
1.2 机器学习 – ML
人工智能技术的一个子集,它使计算机系统能够基于过往经验(及数据观察)学习,并改善其在特定任务中的行为。
包括:支持向量机、决策树、贝叶斯学习、K - means聚类、关联规则学习、回归和神经网络等。
1.3 深度学习 – DL
使用神经网络的机器学习的一个子集。人工神经网络是受人脑结构启发而设计出来的计算模型。特别流行!
典型框架:深度神经网络(DNNs)、卷积神经网络(CNNs)、循环神经网络(RNNs)和生成对抗网络(GAN)等。
使用任务:如对象识别、语音识别和翻译。
二、机器学习的类型
三大类型:
- 监督学习
- 无监督学习
- 强化学习
2.1 监督学习
最常见的机器学习类型
首先有一个要预测的目标、值或类,模型将根据历史数据进行训练,并使用该训练结果来预测未来的收入。例如根据不同的输入(星期几、广告、促销)预测商家的收入。那么该模型是有监督的,因为它知道要学习什么。
-
监督学习的数据
- 数据被分成两部分,训练集和测试集。
- 训练集用于训练模型,测试集用于评估模型的准确性。
-
监督学习的流程
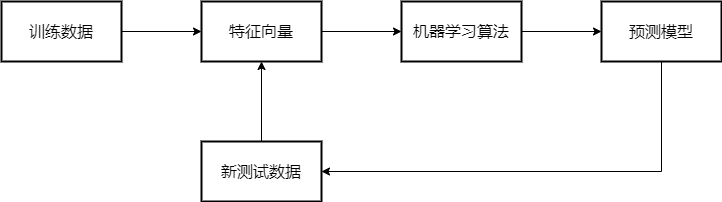
-
监督学习的原则
-
第一,训练数据集包含输入数据(预测变量)和预测的值(可以是数字也可以不是);
-
第二,该模型将使用训练数据来学习输入和输出之间的联系。
-
基本思想:训练数据可以泛化,并且模型可以以一定的准确性用于新数据。
-
-
监督学习的算法
-
线性和逻辑回归
-
支持向量机
-
朴素贝叶斯
-
神经网络
-
梯度提升
-
分类树
-
随机森林
-
-
监督学习的应用
- 通常用于图像识别、语音识别、预测和某种特定业务领域(目标、财务分析等)中的专家系统。
2.2 无监督学习
如果是未标记的数据,冰箱要在这些数据中查找模式和组。例如跟还有客户订购的产品类型、购买产品的频率等要素进行聚类,无监督学习将自动区分不同的客户。
- 无监督学习着重于发现数据本身的分布特点、数据中的结构
- 不需要对数据进行标记
- 可用于查找数据中的组、集群或识别数据中的异常
无监督学习的算法
- 聚类算法 – 试图区分和分离不同组中的观察结果
- K - means
- 层次聚类
- 混合模型
- 降维算法 – (大部分是无监督的)比较少的维度找到数据的最佳表示
- PCA
- ICA
- 自动编码器
- 异常检测 – 用来发现数据中的异常值,即不遵循数据集的记录
无监督学习的应用
- 查找相似客户群
2.3 强化学习
如果想达到一个目标,例如型找到指定规则下赢得某游戏的最佳策略,一旦指定了这些规则,强化学习将多次玩此游戏以找到最佳策略。
- 寻找可以最大化奖励的最佳行动或决策
- 寻找问题的最佳解决方案
- 最优解取决于奖励函数
强化学习的流程
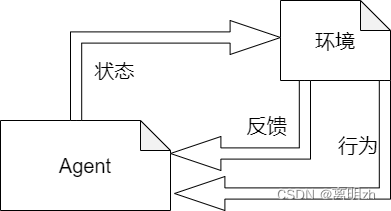
强化学习可用于优化不同类型的问题。可用于优化非线性函数或查找网络中的最短路径。
强化学习是一种无须人工干预即可训练模型的方式,模型从环境中交互学习。当模型获得事件或对象时,它会尝试预测我们想要的结果。如果结果正确,那么模型就会获得奖励;如果结果错误,那么模型就会受到惩罚。
三、机器学习的常见应用
七个方面
- 降维(Dimensionality Reduction, DR)
- 自然语言处理(Natural Language Processing, NLP)
- 计算机视觉(Computer Vision, CV)
- 异常检测(Anomaly Detection)
- 时间序列(Time Series)
- 分析(Analysis)
- 推荐系统(Recommender System)
3.1 降维 – DR
-
内容
- 减少数据维度
- 保留最相关信息
-
应用
- 图像和音频压缩
- 机器学习模型创建过程中的特征工程
3.2 自然语言处理 – NLP
广泛的领域,渐渐成为一门独立的学科。
- 应用
- 主题建模
- 文本分类
- 情感分析
- 机器翻译
- 自然语言生成
- 语音识别
- 文本到语音
- 文本分析
- 摘要
- 实体识别
- 关键词提取
3.3 计算机视觉 – CV
- 应用
- 图像分类
- 图像分割
- 对象检测
3.4 异常检测 – Anomaly Detection
- 目的
- 识别数据中意外的、非典型的东西,对不匹配预期模式或数据集中其他项目的项目、事件或观察值的识别。
- 分类
- 新颖性检测
- 异常值检测
- 欺诈检测等
- 应用
- 银行欺诈
- 结构缺陷
- 医疗问题
- 文本错误 …
- 异常也被称为
- 离群值
- 新奇
- 噪声
- 偏差
- 例外
3.5 时间序列 – Time Series
- 定义
- 将同一统计指标的数值按其发生的时间先后顺序排列而成的数列。
- 举例
- 证券交易所价格
- 天气数据
- 物联网传感器数据
- 应用
- 我们可以根据已有的历史数据对未来进行预测,可以计算时间序列来预测可能的未来值。
3.6 分析 – Analysis
- 定义
- 探索数据性质和模式的经典领域。
- 包括
- 预测分析 — 预测未来或未见数据可能发生的事情
- 当前状态分析 — 我们可以从当前数据获得哪些见解,而无须构建预测模型
- 优化问题 — 如探索如何从以消耗最少资源从A点到B点
3.7 推荐系统 – Recommender System
-
内容
- 解决信息过载问题,能够根据用户的兴趣和爱好将相关内容推荐给用户。
-
包含
- 各种ML推荐技术,利用用户和内容项的已知数据,实现个性化服务。
四、机器学习的工具
4.1 Python特点
-
方便调试的解释性语言
-
跨平台作业
-
广泛的应用程序接口(大量的第三方程序库)
4.2 Python工具举例
-
机器学习框架
- Scikit - learn
- PyTorch
- TensorFlow
- Keras
-
辅助框架
- Pandas
- Numpy
- Matplotlib
- Seaborn
- OpenCV
-
编程语言
- Python
- R
- C++
五、机器学习的开发应用
- 机器学习应用路线图
- 机器学习的开发流程
5.1 机器学习的开发流程
- 传统编程开发流程与机器学习开发流程的比较
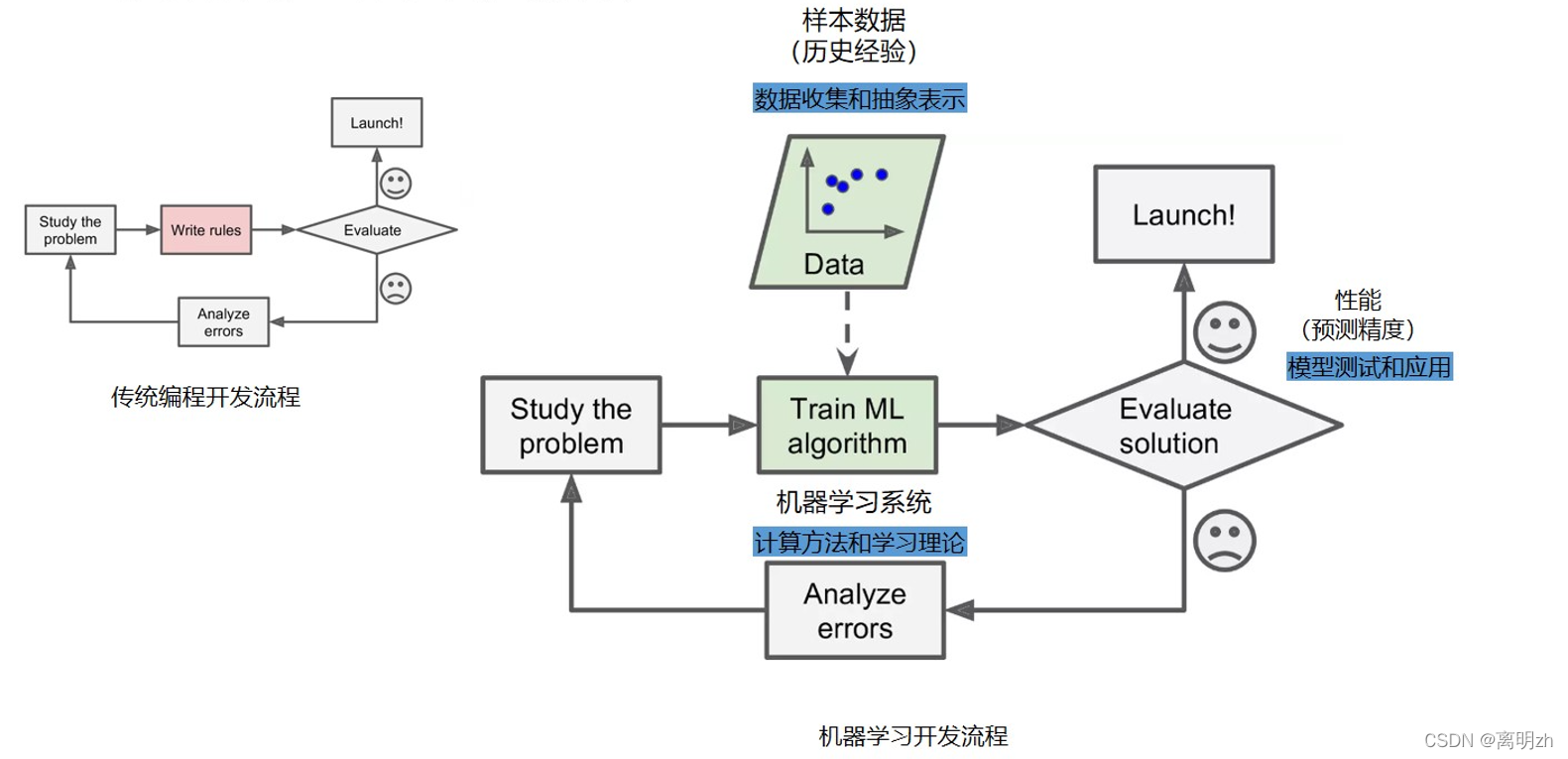
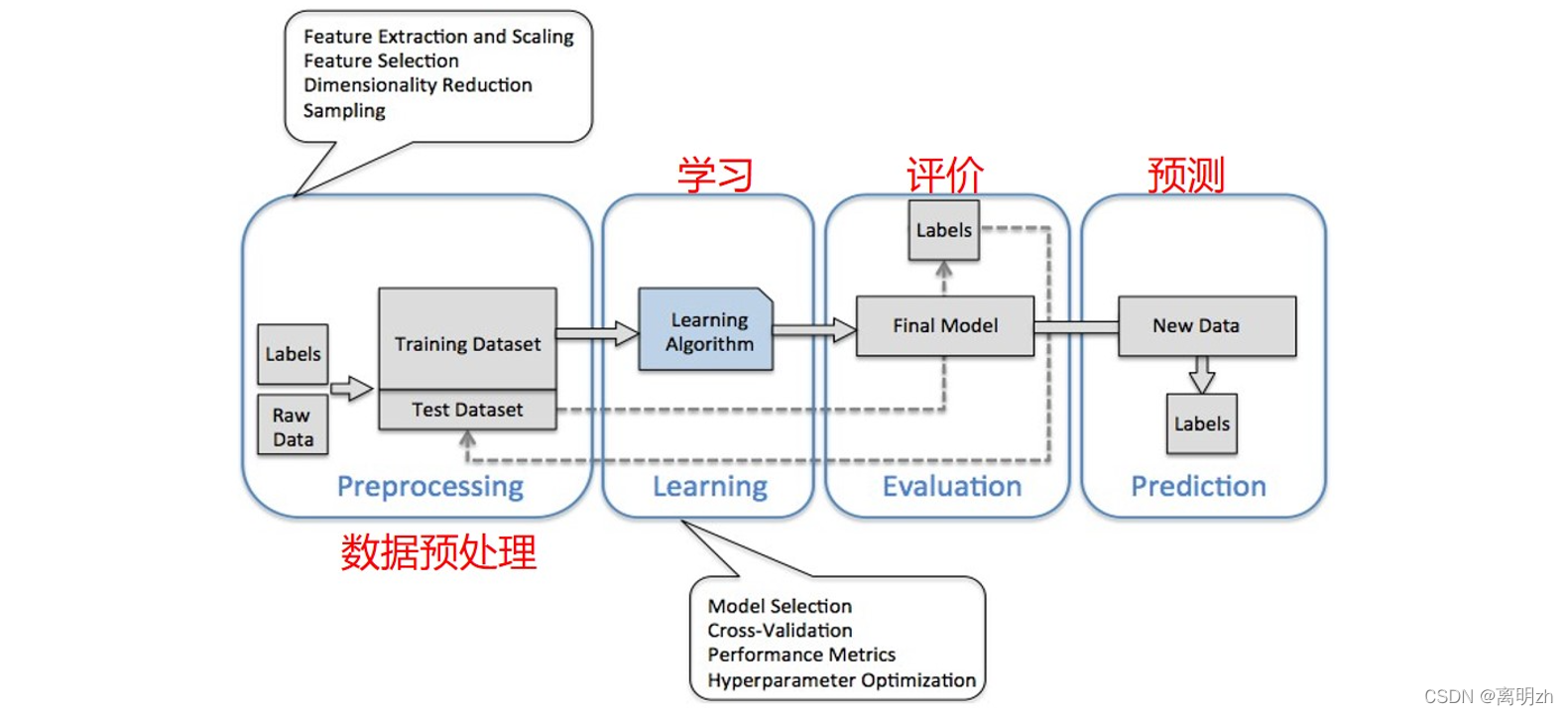
5.2 机器学习的应用路线
- 机器学习的应用路线
- 数据预处理 — Preprocessing
- 学习 — Learning
- 评价 — Evaluation
- 预测 — Presiction


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









