






命令行创建Scrapy框架
scrapy startproject project_name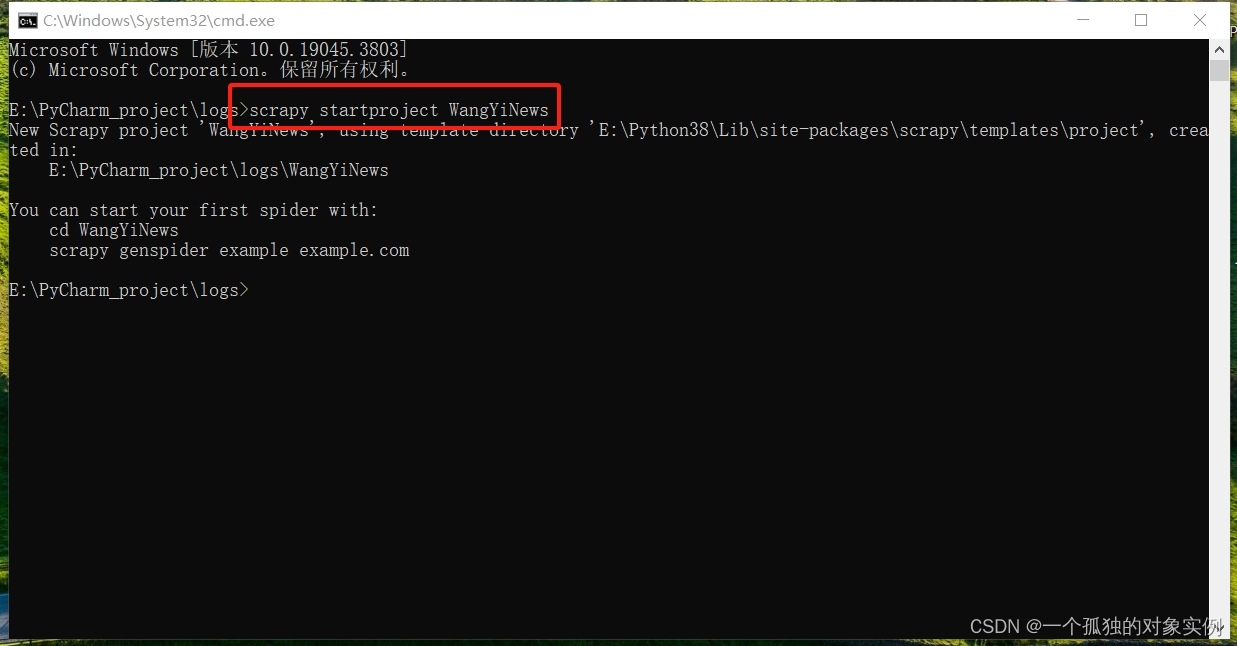
scrapy genspider spider_name request_url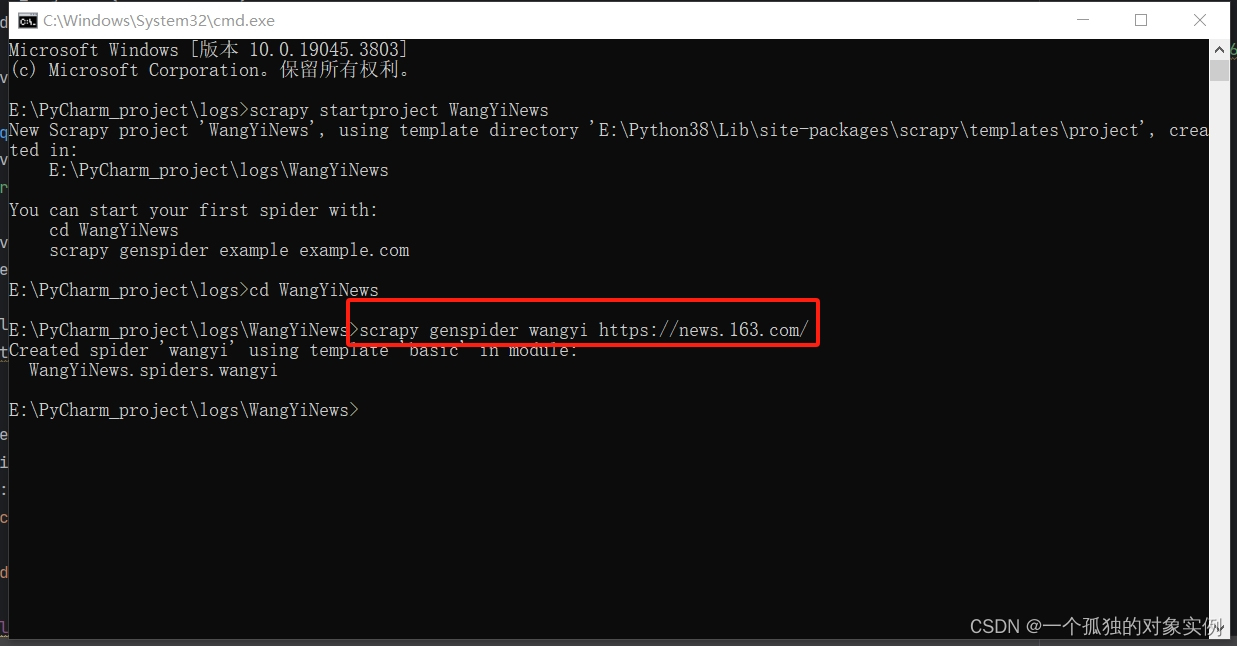
经过上述命令后,会自动搭建如下图所示的框架:
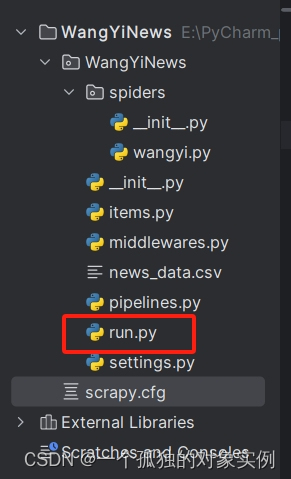
搭建的框架中不包括news_data.csv,run.py文件,其中run.py用于调试scrapy框架临时建立的文件,代码如下:
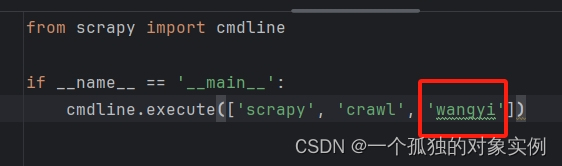
其中红色框内指的是在spiders文件夹中要运行的wangyi.py文件
Spider
wangyi.py源码
from typing import Iterable
import scrapy
from scrapy import Request
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class WangyiSpider(scrapy.Spider):
name = "wangyi"
allowed_domains = ["news.163.com"]
start_urls = ["https://news.163.com/"]
def __init__(self):
option = webdriver.ChromeOptions()
option.add_argument('--headless')
option.add_argument('user-agent='
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36')
self.driver = webdriver.Chrome(option)
def start_requests(self) -> Iterable[Request]:
self.driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get:()=>undefined})'
})
self.driver.get(self.start_urls[0])
wait = WebDriverWait(self.driver, 5)
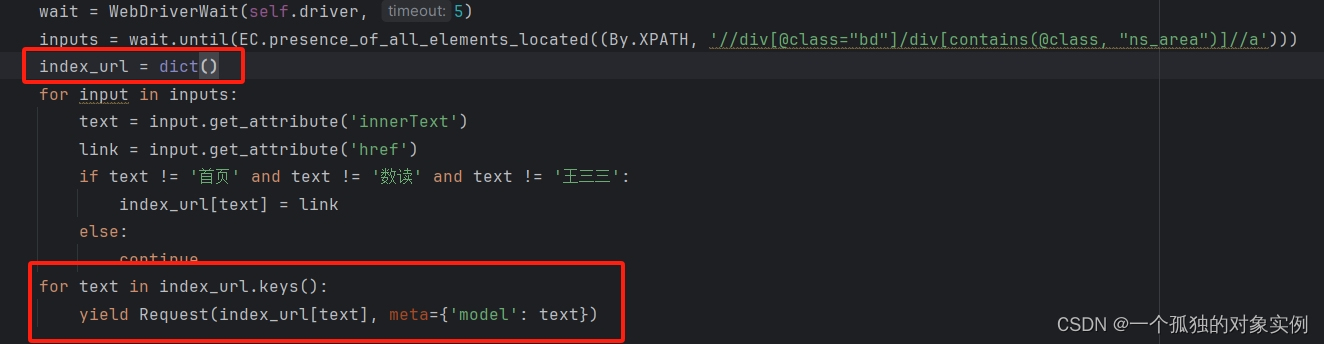
inputs = wait.until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="bd"]/div[contains(@class, "ns_area")]//a')))
index_url = dict()
for input in inputs:
text = input.get_attribute('innerText')
link = input.get_attribute('href')
if text != '首页' and text != '数读' and text != '王三三':
index_url[text] = link
else:
continue
for text in index_url.keys():
yield Request(index_url[text], meta={'model': text})
def parse(self, response):
pass防止检测程序检测到selenium爬虫,导致屏蔽,使用CDP(Chrome Devtools Protocol,Chrome开发工具协议)可以解决这个问题

start_requests函数用于获取如下所有的跳转链接URL

注意获取指定节点元素的跳转链接URL时,因为HTML节点元素设置了过期时间,所以要先缓存至数据结构列表或字典,然后迭代返回列表或字典的URL。如果直接迭代返回节点元素的URL,那么在迭代过程中会因为超过过期时间,出现节点元素不存在的异常。
Item
items.py源码
import scrapy
class WangyinewsItem(scrapy.Item):
# define the fields for your item here like:
model = scrapy.Field() #新闻模块
title = scrapy.Field() #标题
comments_num = scrapy.Field() #评论数
title_link = scrapy.Field() #标题链接
img_link = scrapy.Field() #图片链接
comments_link = scrapy.Field() #评论链接定义新闻数据的模块、标题、标题链接、图片链接、评论数、评论链接
中间件
middlewares.py
import time
from selenium.webdriver.common.by import By
from scrapy.http import HtmlResponse
from items import WangyinewsItem
from lxml import etree
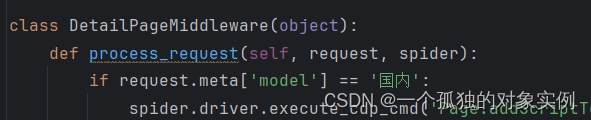
class DetailPageMiddleware(object):
def process_request(self, request, spider):
if request.meta['model'] == '国内':
spider.driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get:()=>undefined})'
})
spider.driver.get(request.url)
time.sleep(3)
spider.driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(3)
spider.driver.find_element(By.XPATH, '//a[@class="load_more_btn"]').click()
time.sleep(3)
html = spider.driver.page_source
elif request.meta['model'] == '国际' or request.meta['model'] == '军事' or request.meta['model'] == '航空':
spider.driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get:()=>undefined})'
})
spider.driver.get(request.url)
time.sleep(3)
spider.driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(3)
html = spider.driver.page_source
elif request.meta['model'] == '传媒科技研究院' or request.meta['model'] == '政务':
spider.driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get:()=>undefined})'
})
spider.driver.get(request.url)
for i in range(4):
time.sleep(3)
spider.driver.find_element(By.XPATH,
'//div[@class="middle_part"]/a[contains(@class, "load_more_btn")]').click()
html = spider.driver.page_source
elif request.meta['model'] == '公益':
spider.driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get:()=>undefined})'
})
spider.driver.get(request.url)
for i in range(3):
time.sleep(3)
spider.driver.find_element(By.XPATH,
'//div[@class="middle_part"]//a[contains(@class, "load_more_btn")]').click()
html = spider.driver.page_source
elif request.meta['model'] == '媒体':
spider.driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get:()=>undefined})'
})
spider.driver.get(request.url)
for i in range(3):
time.sleep(3)
spider.driver.find_element(By.XPATH,
'//div[@class="content-left"]/div[@class="getMoreBox"]').click()
html = spider.driver.page_source
return HtmlResponse(url = request.url, body = html, request = request, encoding='utf-8')
class IndexPageMiddleware(object):
def process_spider_output(self, response, result, spider):
item = WangyinewsItem()
if response.meta['model'] == '国内' or response.meta['model'] == '国际':
title = response.xpath('//div[@class="ndi_main"]//div[@class="news_title"]//a/text()').extract()
title_link = response.xpath('//div[@class="ndi_main"]//div[@class="news_title"]//a/@href').extract()
img_link = response.xpath('//div[@class="ndi_main"]//img/@src').extract()
comments_num = response.xpath('//div[@class="ndi_main"]//div[contains(@class, "share-join")]//'
'span[contains(@class, "post_recommend_tie_icon")]/text()').extract()
comments_link = response.xpath('//div[@class="ndi_main"]//div[contains(@class, "share-join")]/'
'a/@href').extract()
for i in range(len(title)):
item['model'] = response.meta['model']
item['title'] = title[i]
item['title_link'] = title_link[i]
item['img_link'] = img_link[i]
item['comments_num'] = comments_num[i]
item['comments_link'] = comments_link[i]
yield item
elif response.meta['model'] == '军事' or response.meta['model'] == '航空':
title_links = response.xpath('//div[@class="ndi_main"]/div[contains(@class, "data_row")]//div[@class="news_title"]//a/@href').extract()
for i in range(len(title_links)):
spider.driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get:()=>undefined})'
})
spider.driver.get(title_links[i])
time.sleep(3)
html = spider.driver.page_source
html = etree.HTML(html)
title = html.xpath('//h1[@class="post_title"]/text()')
if not title:
continue
title_link = title_links[i]
img_link = html.xpath('//div[@class="post_body"]//img/@src')
comments_num = html.xpath(
'//div[@class="post_top"]//a[contains(@class, "post_top_tie_count")]/text()')
comments_link = html.xpath(
'//div[@class="post_top"]//a[contains(@class, "post_top_tie_count")]/@href')
item['model'] = response.meta['model']
item['title'] = title[0]
item['title_link'] = title_link
if img_link:
item['img_link'] = img_link[0]
else:
item['img_link'] = 'zero'
item['comments_num'] = comments_num[0]
item['comments_link'] = comments_link[0]
yield item
elif response.meta['model'] == '传媒科技研究院' or response.meta['model'] == '政务' or response.meta['model'] == '公益':
title_links = response.xpath('//div[@class="datalist"]/div[contains(@class, "data_row")]//div[@class="news_title"]//a/@href').extract()
for i in range(len(title_links)):
spider.driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get:()=>undefined})'
})
spider.driver.get(title_links[i])
time.sleep(3)
html = spider.driver.page_source
html = etree.HTML(html)
title = html.xpath('//h1[@class="post_title"]/text()')
if not title:
continue
title_link = title_links[i]
img_link = html.xpath('//div[@class="post_body"]//img/@src')
comments_num = html.xpath(
'//div[@class="post_top_tie"]/a[contains(@class, "post_top_tie_count")]/text()')
comments_link = html.xpath(
'//div[@class="post_top_tie"]/a[contains(@class, "post_top_tie_count")]/@href')
item['model'] = response.meta['model']
item['title'] = title[0]
item['title_link'] = title_link
if img_link:
item['img_link'] = img_link[0]
else:
item['img_link'] = 'zero'
item['comments_num'] = comments_num[0]
item['comments_link'] = comments_link[0]
yield item
elif response.meta['model'] == '媒体':
title_links = response.xpath('//div[@class="list_message"]//div[contains(@class, "news_one")]//div[@class="describe"]/h2/a/@href').extract()
for i in range(len(title_links)):
spider.driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get:()=>undefined})'
})
spider.driver.get(title_links[i])
time.sleep(3)
html = spider.driver.page_source
html = etree.HTML(html)
title = html.xpath('//h1[@class="post_title"]/text()')
if not title:
continue
title_link = title_links[i]
img_link = html.xpath('//div[@class="post_body"]//img/@src')
comments_num = html.xpath(
'//div[@class="post_top_tie"]/a[contains(@class, "post_top_tie_count")]/text()')
comments_link = html.xpath(
'//div[@class="post_top_tie"]/a[contains(@class, "post_top_tie_count")]/@href')
item['model'] = response.meta['model']
item['title'] = title[0]
item['title_link'] = title_link
if img_link:
item['img_link'] = img_link[0]
else:
item['img_link'] = 'zero'
item['comments_num'] = comments_num[0]
item['comments_link'] = comments_link[0]
yield item下载器中间件
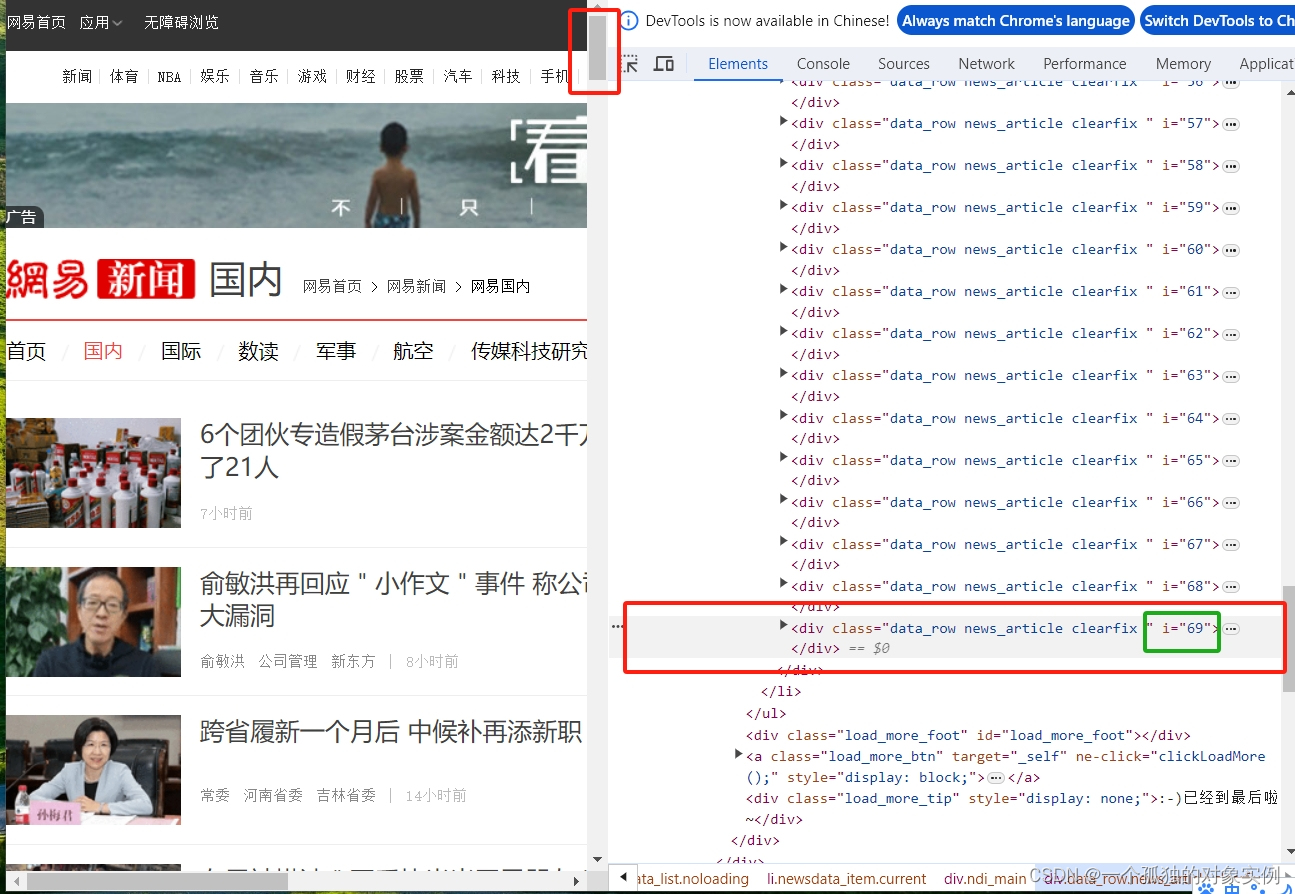
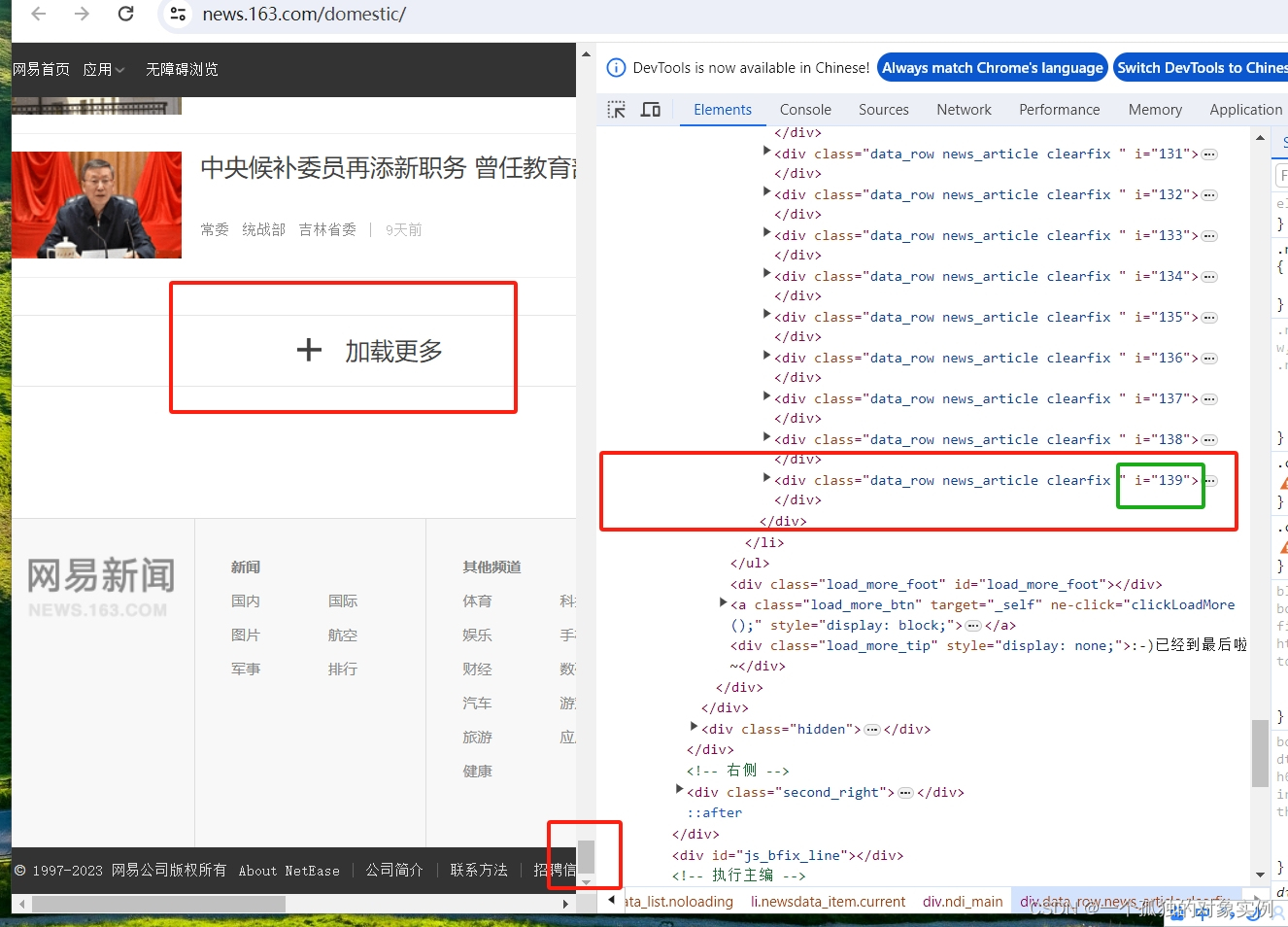
process_request函数负责加载request的页面源代码,以‘国内’模块为例,网易新闻是通过JavaScript渲染的动态页面,所以需要使用selenium工具滑动竖向滑块,点击‘加载更多’,在页面源代码处显示加载好的数据,最后返回响应体。
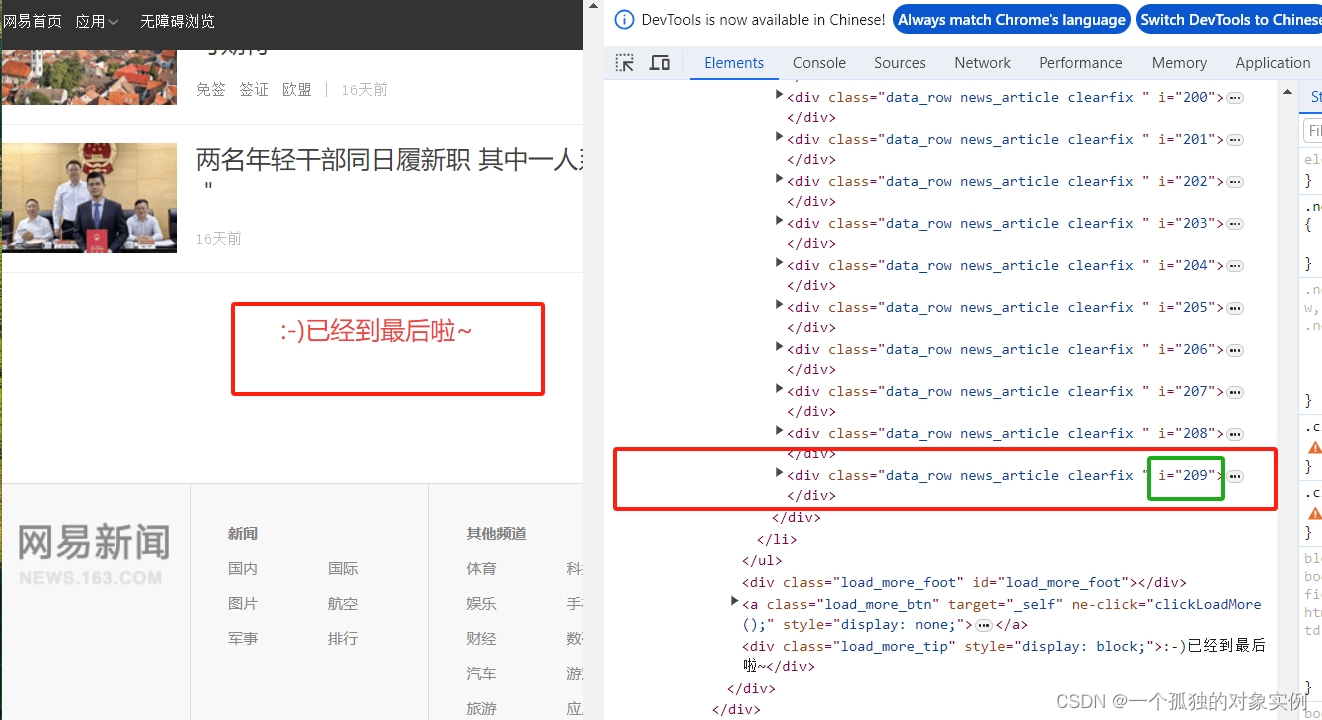
爬虫中间件

process_spider_output函数负责解析下载器中间件返回的响应体,抓取新闻数据。
项目管道
pipelines.py
import csv
class WangyinewsPipeline:
def __init__(self):
self.f = open('news_data.csv', 'a', encoding='utf-8')
headname = ['标题', '链接', '图像链接', '评论数', '评论链接', '新闻模块']
self.writer = csv.DictWriter(self.f, headname)
def process_item(self, item, spider):
print(item)
self.writer.writerow({'标题' : item['title'],
'链接' : item['title_link'],
'图像链接' : item['img_link'],
'评论数' : item['comments_num'],
'评论链接' : item['comments_link'],
'新闻模块' : item['model']})
return item
def open_spider(self, spider):
self.writer.writeheader()
def close_spider(self, spider):
self.f.close()初始化csv文件,将爬虫中间件抓取的数据以结构化的形式写入表格。
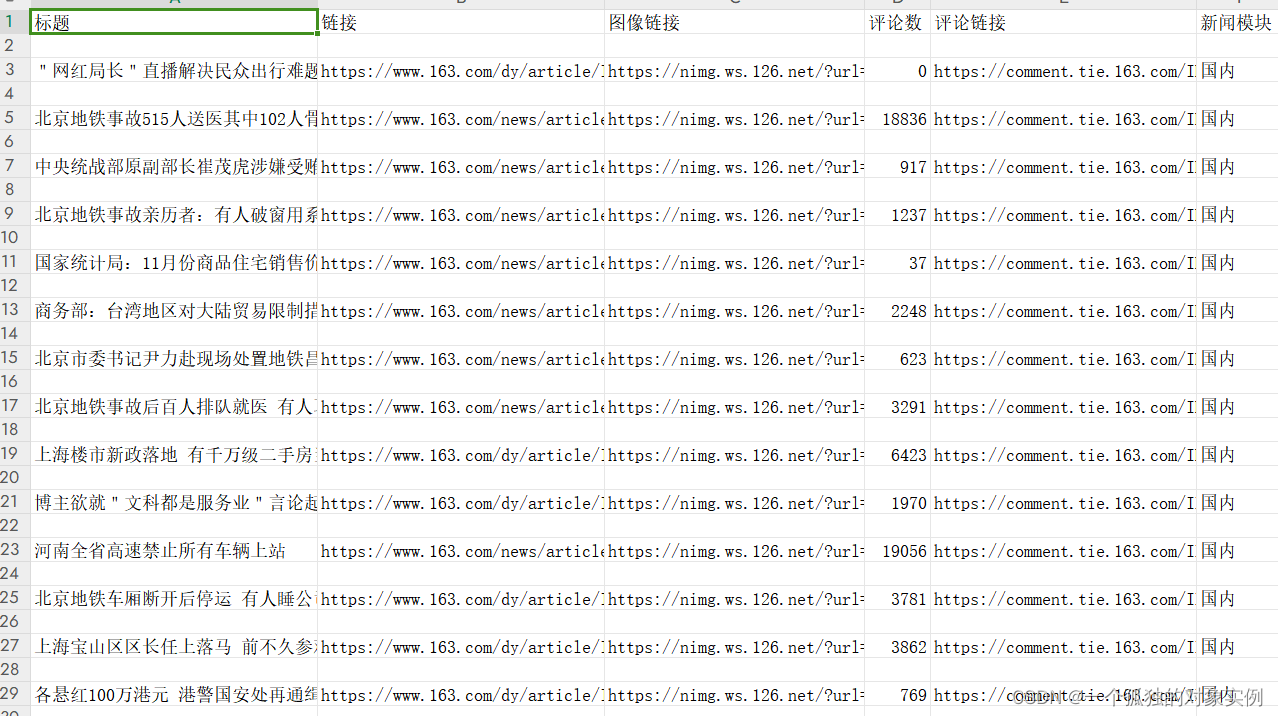
全局配置
settings.py
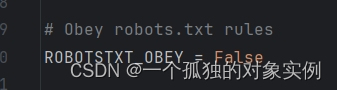
robots协议规定爬虫引擎允许爬取哪些页面,不允许爬取哪些页面。设置为False,表示爬虫程序不遵守该协议
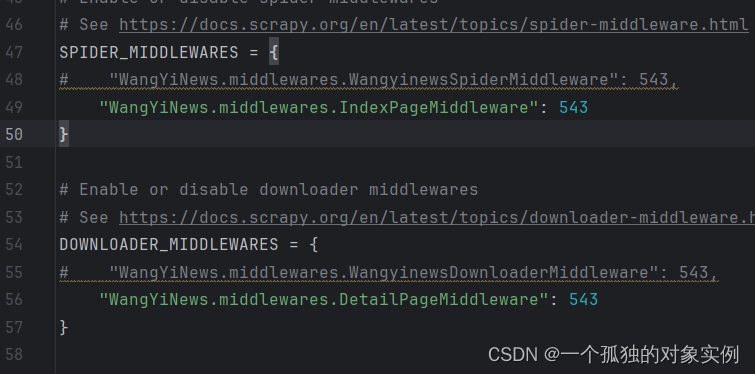
设置下载器、爬虫中间件优先级,启用该中间件
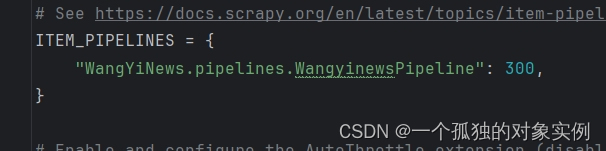
设置项目管道优先级,启用该项目
数据处理
data_process.py
import pandas as pd
writer = pd.ExcelWriter('data.xlsx')
all_data = pd.read_csv('news_data.csv', encoding='utf-8', index_col=0)
head = ['国内', '国际', '军事', '航空', '传媒科技研究院', '政务', '公益', '媒体']
for index in head:
data = all_data[all_data['新闻模块'] == index]
data.to_excel(writer, sheet_name=index)
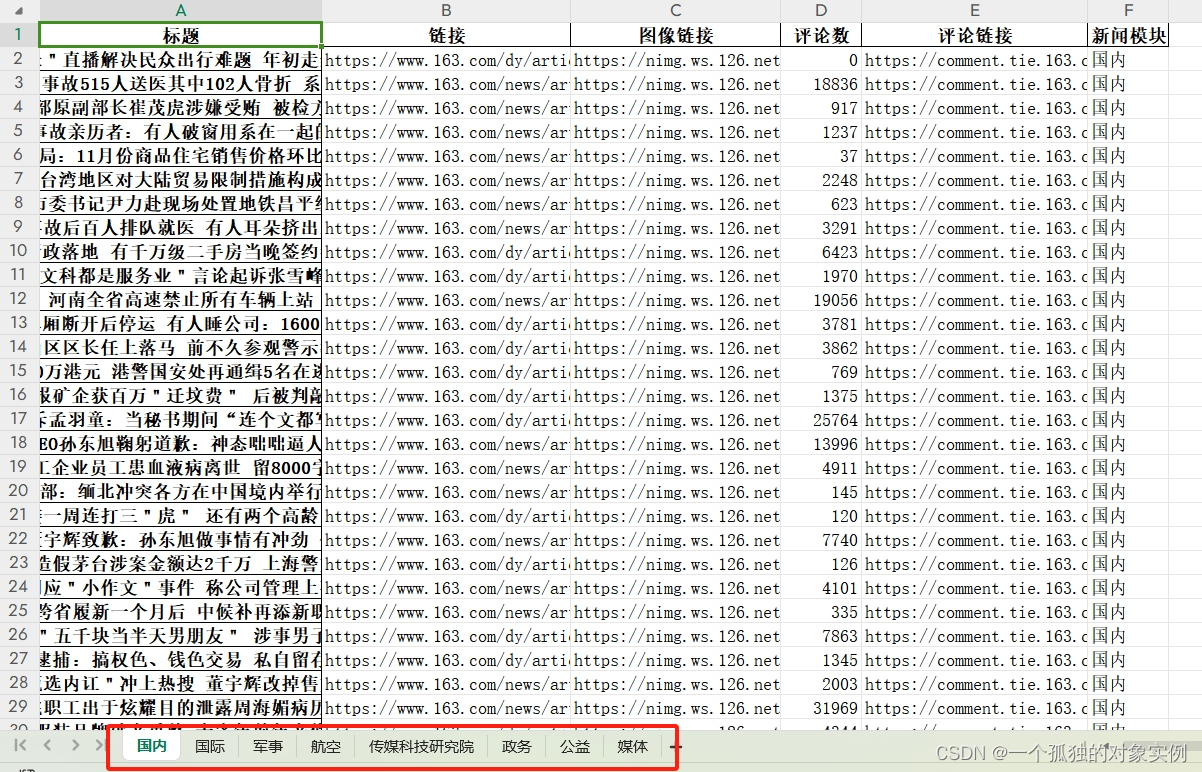
writer.close()抓取的数据中,新闻模块包含了国内、国际、军事、航空、传媒科技研究院、政务、公益、媒体,还需要按照模块分别写入多个sheet

















 1414
1414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









