







一、equals底层方法
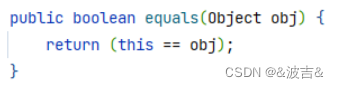
Object类中的equals方法,底层是通过==来进行比较,所以比较的是对象的内存地址
二、hashcode底层方法
public native int hashCode();
Java中的hashCode方法就是根据一定的规则与对象相关信息(例如对象的存储地址,对象的字段等)映射成一个数组,这个数值就被称为散列值
三、hash算法
就是将hashcode的得到的随机数(散列值),映射成固定长度的值
Java中规定:
(1)如果两个对象通过equals方法比较是相等的,那么它们的hashCode方法结果值也是相等的。
(2)如果两个对象通过equals方法比较是不相等的,那么它们的hashCode方法结果值不一定不相等。
很多情况下,我们比较对象并不需要比较对象的地址,而是只要是同一个类的不同对象,成员属性值相同,我们就认为是同一个对象
四、重写equals方法
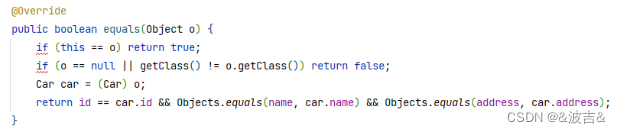
重写完之后,两个对象,成员属性值相同即可
五、为什么重写hashCode方法
尽管重写equals方法,已经能够判断,但是会出现以下问题
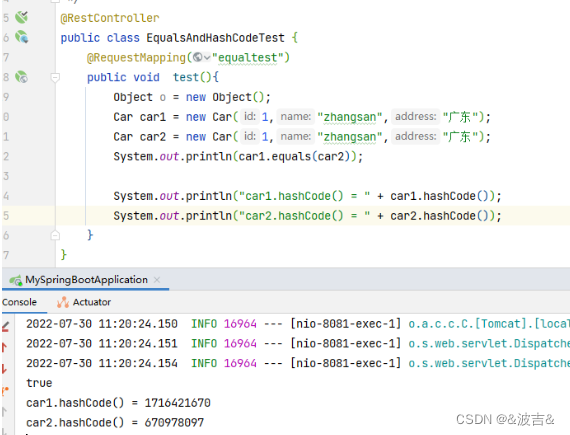
两个对象的hashCode值不同
当我们将equals方法重写后有必要将hashCode方法也重写,这样做才能保证不违背hashCode方法中“相同对象必须有相同哈希值”的约定。
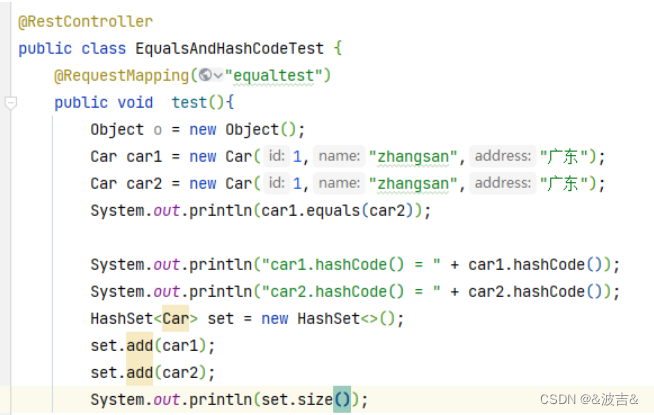
set.size为2
HashSet有一个特性就是不能允许相同的值的存在,我们car1和car2对于我们来说就是同一个对象(同类型,同值),那么为什么会存在这个问题呢?String类中对equals方法进行重写扩充了,但是如果此时我们不将hashCode方法也进行重写,那么String类调用的就是来自顶级父类Obejct类中的hashCode方法。即,对于两个字符串对象,使用它们各自的地址值映射为哈希值。
也就是会出现如下情形:也就是说,被String类中的equals方法认定为相等的两个对象拥有两个不同的哈希值——因为它们的地址值不同。
为什么重写equals方法就得重写hashCode方法?——
因为必须保证重写后的equals方法认定相同的两个对象拥有相同的哈希值。同时我们也得出了——hashCode方法的重写原则就是保证equals方法认定为相同的两个对象拥有相同的哈希值。equals里一般比较的比较全面比较复杂,这样效率就比较低,而利用hashCode进行对比,则只要生成一个hash值进行比较就可以了,效率很高,那么既然hashCode效率这么高为什么还要使用equals进行比较呢?
因为hashCode并不是完全可靠,有时候不同的对象生成的hashcode也会一样(hash冲突),所以hashCode只能说是大部分时候可靠,并不是绝对可靠。
所以可以得出:equals相等的两个对象,它们的hashCode肯定相等,也就是用equals对比是绝对可靠的;
hashCode相等的两个对象,它们的equals不一定相等,也就是hashCode不是绝对可靠的;
所有对于需要大量并且快速的对比的话如果都用equals去做显然效率太低,解决方式是,每当需要对比的时候,
hashCode去对比,这就用到了哈希表,能够快速的地位到对象的存储位置,如果hashCode不一样,则表示这两个对象肯定不相等(也就是不必再用equals去再对比了),如果hashCode相同,此时再对比它们的
equals,如果equals也相同,则表示这两个对象是真的相同了。
所以这里也是我们需要重写HashCode方法的原因
五、重写hashCode方法
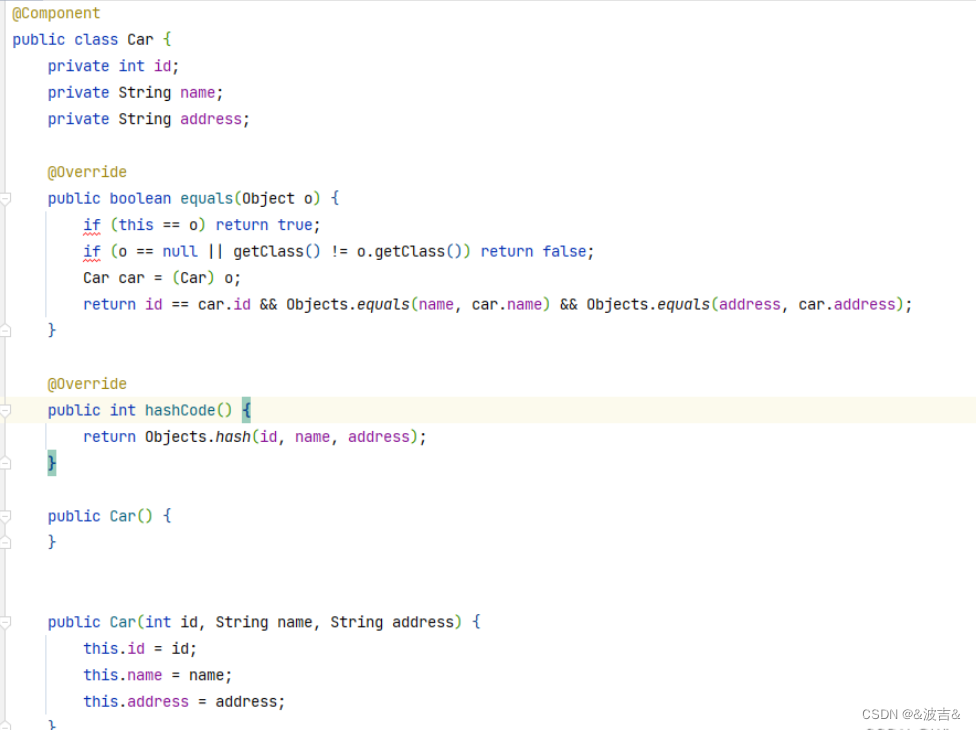
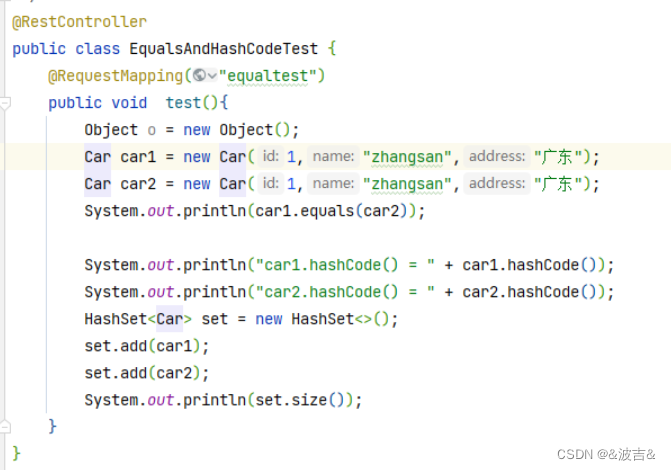
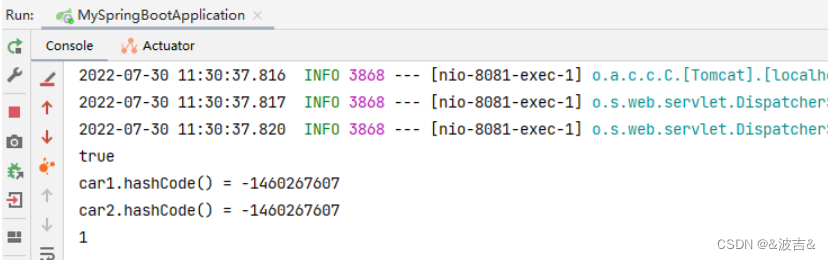
这里可以看到,重写HashCode方法之后,两个实例对象的hashcode的值也就是相同的,HashSet也就能起到了去重的效果
所以Java中规定,一般重写equals方法就要重写HashCode方法,也是为了保证在不同场景下使用不会出错

















 1701
1701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









