







蓝桥云课笔记
一、认识Linux
1.快捷操作
- 输入 cd … 可以回到上一级目录,类似 Windows 的「向上」。
- cd - 表示回到上一次所在的目录,类似 Windows 的「后退」。
- cd ~ 表示回到当前用户的主目录,类似 Windows 的「回到桌面」。
- cd / 表示进入根目录,它是一切目录的父目录。
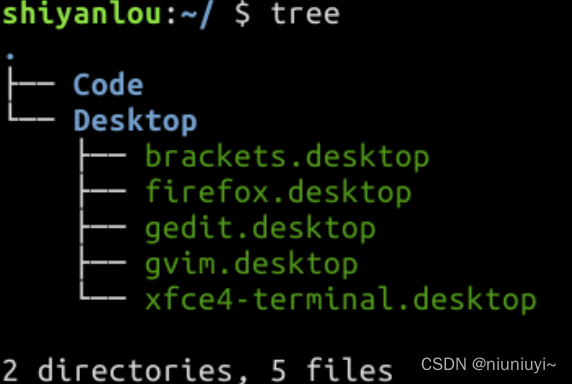
2.查看目录结构:tree
- 使用 tree 命令,可以列出一个文件夹下的所有子文件夹和文件(以树形结构来进行列出)。
3.绝对路径
Linux 进入目录的方式有绝对路径和相对路径两种。
之前我们都是用 相对路径 进入目录的,这相当于你在 Windows 系统下,在当前文件夹中点击下一个文件夹进入;
而 绝对路径 是一个以根目录 / 为起点的完整路径,如: /home/shiyanlou/Code,可以类比 Windows 上的 C:\Users\电脑用户名\Desktop。
使用 pwd 命令可以获取当前目录的绝对路径:

有了绝对路径后,不管你当前在哪个目录下,都可以通过指令进入指定目录:

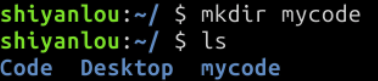
4.新建目录
使用 mkdir 命令可创建目录,mkdir mycode 的意思就是新建一个名为 mycode 的目录。
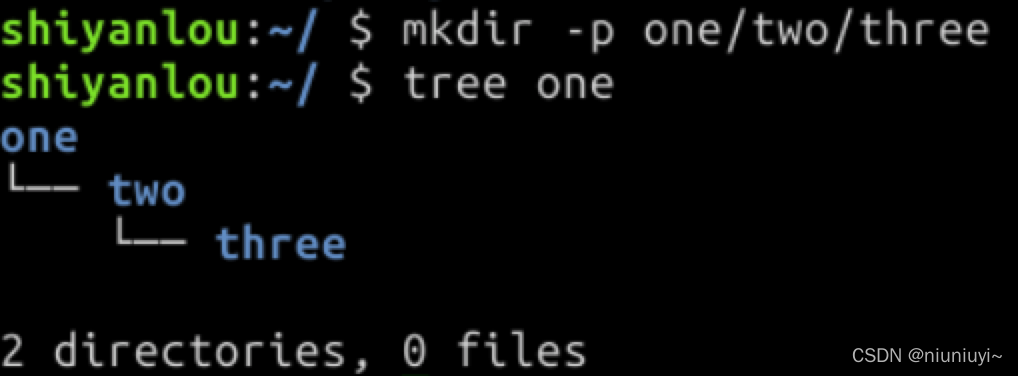
还可以在 mkdir 后加入 -p 参数,一次性创建多级目录,如:
二、Linux文件操作
下面是 Linux 中对文件的常用操作,包含新建、复制、删除等。
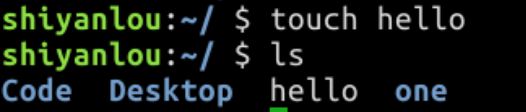
1.新建空白文件
使用 touch 命令可以新建文件,比如我想再新建一个名为 “hello” 的文件,可输入。“hello” 文件就被创建出来了,用 ls 命令查看一下:
2.复制
使用 cp 命令(Copy)复制文件到指定目录下,比如要把 hello 文件复制到 one/two 这个目录下:
cp hello one/two/
tree one
如果要复制目录,需要在 cp 后加上 -r ,然后接上 目录名 目标目录名:
mkdir test
cp -r test one/two
tree one
上面的操作中,我们先新建了一个 test 目录,然后把它复制进了 one/two 这个目录中,再通过tree one 直接查看 one 的目录结构。
3.删除
使用 rm 命令删除文件:
ls
rm hello
ls
删除目录要加上 -r 选项,类似 cp -r 拷贝目录,会删除目录和目录下的所有内容:
mkdir test
ls
rm -r test
ls
4.移动文件/目录与重命名
使用 mv 命令可以移动文件或目录。
首先,我们进入到 /home/shiyanlou 目录,使用 touch 创建空文件 test1:
cd ~
touch test1
然后,我们创建一个新目录 dir1,ls 查看一下
mkdir dir1
ls
使用 mv 命令 将 test1 移动到 dir1 目录,代码如下:
mv test1 dir1
然后进入 dir1 目录查看一下
cd dir1
ls
mv 命令还可以用来重命名,如 mv test1 test2, 会把 test1 重命名为 test2:
ls
mv test1 test2
ls
5.查看文件内容
使用 cat 命令,可以将文件中的内容打印到屏幕上,使用方法是 cat 文件路径。现在还没有文件,我们先从其他地方复制过来一个:
cp /etc/passwd passwd
ls
这样就把 passwd 文件从 /etc 目录拷贝到了当前目录中,然后我们用 cat passwd 显示文件中的内容:
cat passwd
使用 cat -n 可以带行号地打印文件内容:
cat -n passwd
三、python操作
1.特定年份日期处理
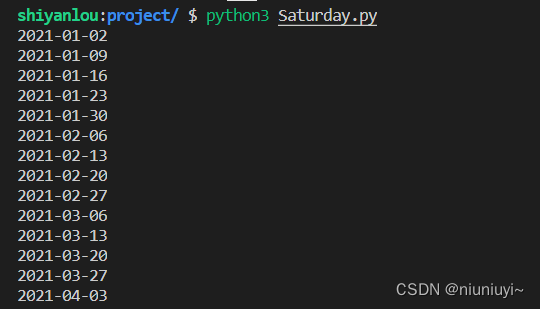
需要编写一个脚本程序,打印输出 2021 年所有周六的日期。
要求:
- 文件的路径为 /home/project/Saturday.py。
- 每行一个日期,打印输出的行数与2021 年周六的总个数相等。
- 最终效果图(部分截图)如下:
import datetime
dt=datetime.date(2021,1,1)
while dt<=datetime.date(2021,12,31):
if dt.weekday()==5:#0是星期一,1是星期二......
print(dt)
dt=dt+datetime.timedelta(1)
2.任意年份的日期处理
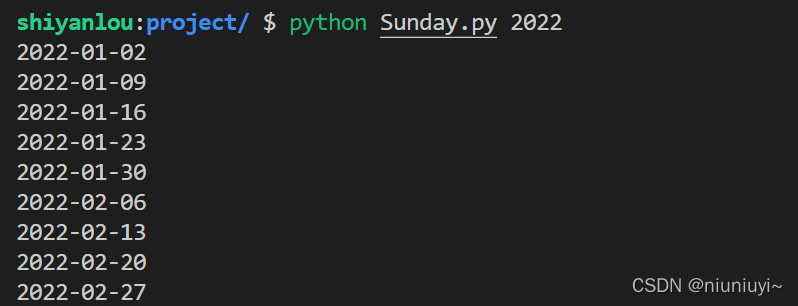
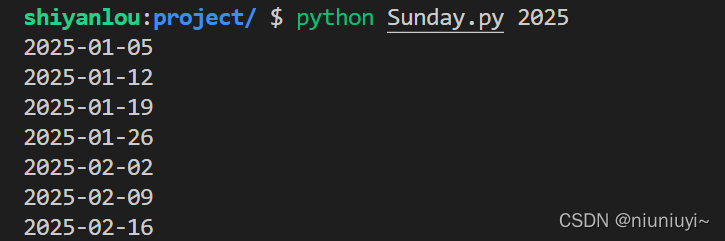
编写一个脚本程序,打印输出任意年份所有周日的日期。
要求:
- 文件的路径为 /home/project/Sunday.py。
- 每行一个日期,打印输出的行数与对应年份周日的总个数相等。
- 最终效果图(部分截图)如下:
3.统计学习数据
JSON(JavaScript Object Notation, /ˈdʒeɪsən/)是一种轻量级的数据交换格式,最初是作为 JavaScript 的子集被发明的,但目前已独立于编程语言之外,成为了通用的数据格式,绝大部分编程语言都有专门处理 JSON 数据的函数或工具。
本节挑战,我们需要编写脚本处理 JSON 数据。
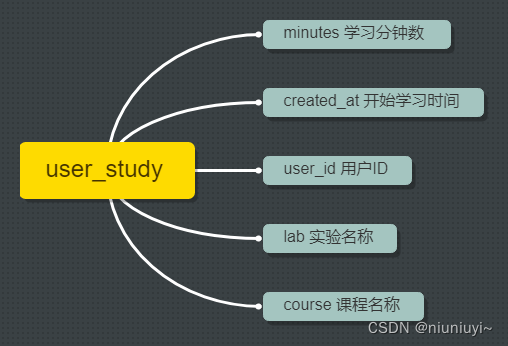
user_study.json 文件包含用户的学习数据,部分内容展示如下:
{
"minutes": 3,
"created_at": "2016-06-30 23:54:01",
"user_id": 220148,
"lab": "Vim快速入门",
"course": "Vim编辑器"
}
请编写脚本统计文件中一共有多少名用户,共有多少门课。
要求
脚本文件的路径为 /home/project/count.py
运行效果图如下:

代码:
import json
user,cour=set(),set()
with open('/home/project/user_study.json','r') as f:
date=json.load(f)
for dt in date:
user.add(dt['user_id'])
cour.add(dt['course'])
print('文件中包含%d名用户,%d门课。'%(len(user),len(cour)))
4.提取电影信息
实验环境中,/home/project 目录下有一个包含 100 部电影信息的 JSON 文件 movies.json,每个电影信息的结构如下:
{
"id": 1,
"name": "霸王别姬",
"alias": "Farewell My Concubine",
"categories": [
"剧情",
"爱情"
],
"published_at": "1993-07-26",
"minute": 171,
"score": 9.5,
"regions": [
"中国内地",
"中国香港"
]
}
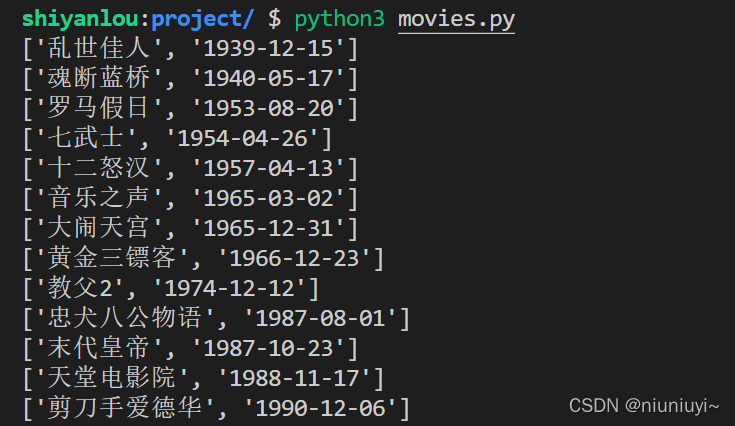
本节挑战,我们需要从 JSON 文件中提取出电影的名称和上映时间,然后按照电影上映日期升序打印输出(输出效果参考要求)。
要求
脚本文件路径为 /home/project/movies.py 。
脚本需要实现对 JSON 文件中数据的提取,按照日期升序输出。
输出共 100 行。
最终运行效果如下(部分截图):
代码:
import json
name=''
date=''
dict={}
with open('movies.json','r',encoding='utf8') as f:
data = json.load(f)
for i in data['results']:
name=i['name']
date=i['published_at']
dict[name]=date
order_dict=sorted(dict.items(),key=lambda x:x[1],reverse=False)
for i in order_dict:
list=[i[0],i[1]]
print(list)
5.提取用户输入信息
正则表达式(英文为 Regular Expression,常简写为regex、regexp 或 RE),也叫规则表达式、正规表达式,是计算机科学的一个概念。
所谓“正则”,可以理解为正式的规则或者正确的规则。在正则表达式中,这些规则通常都是单个的字符串,我们通过对这些规则的排列组合就可以实现对一类字符串的匹配。
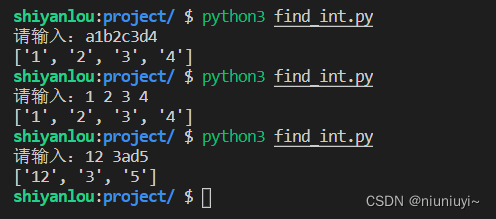
实现一个脚本程序,接收用户输入的一个字符串,然后从中提取整数。0-9 之外的一切字符都作为分隔符。
要求
代码需要写在 /home/project/find_int.py。
脚本文件中不能出现数字。
最终运行效果如下:
代码:
import re
a=input('请输入:')
pattern='\d+'
b=re.findall(pattern, a)
print(b)
正则表达式中,group()用来提出分组截获的字符串,()用来分组
6.从参数中提取信息
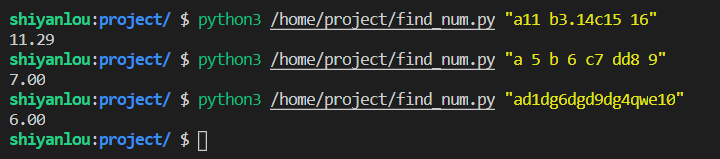
实现一个脚本程序,提取文本中的数字(包括整数和浮点数),然后计算平均数,结果保留两位小数。文本作为脚本的参数进行传递(可参考 要求 中的运行效果。)。
最终只需要输出计算出的平均数。
要求
代码需要写在 /home/project/find_num.py。
文本作为脚本的参数传入。
不要将最终输出结果写在脚本文件中。
最终运行效果如下:
注意:题目举例输入的参数有文件路径哦!要从后面读取参数
sys.argv[0]接收的是文件名(如果运行文件和运行终端不在同一路径下会接收其的路径及文件名)
sys.argv[1] 接收的的在终端传入的第一个参数
sys.argv[2]接收的的在终端传入的第二个参数
代码:
import sys
import re
import math
from numpy import *
def find_num(a):
pattern ='\d+\.\d+|\d+' #或者 '\d+\.?\d*'
b = re.findall(pattern,a)
c = []
for i in b: c.append(float(i))
print('%.2f' % mean(c))
if __name__=="__main__":
a = sys.argv[1]
find_num(a)
四、正则表达式
1.限定符
- a* (a出现0次或多次)
- a+ (a出现1次或多次)
- a? (a出现0次或1次)
- a{6} (a出现6次)
- a{2-6} (a出现2-6次)
- a{2,} (a出现两次以上)
2.或运算符
- (a|b) (匹配a或者b)
- (ab)|(cd) (匹配ab或者cd)
3.字符类
- [abc] (匹配a或者b或者c)
- [a-c] (匹配a或者b或者c,同上)
- [a-fA-F0-9] 匹配小写大写英文字符以及数字
- [^0-9]匹配非数字字符
4.元字符
- \d (匹配数字字符)
- \D (匹配非数字字符)
- \w (匹配单词字符:英文、数字、下划线)
- \W (匹配非单词字符)
- \s (匹配空白符:包含换行符、Tab)
- \S (匹配非空白字符)
- . (匹配任意字符,除换行符外)
- \bword\b (\b标注字符的边界,全字匹配)
- ^ (匹配行首)
- $ (匹配行尾)
5.贪婪/懒惰匹配
- <.+> (默认贪婪匹配"任意字符")
- <.+?> (懒惰匹配"任意字符")
Python正则表达式
前面的一个 r 表示字符串为非转义的原始字符串,让编译器忽略反斜杠,也就是忽略转义字符
菜鸟-python正则表达式
re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
re.sub
检索和替换
Python 的 re 模块提供了re.sub用于替换字符串中的匹配项。
re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
re.split
split 方法按照能够匹配的子串将字符串分割后返回列表


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









