




 新加坡科研团队提出RecXi框架,通过语音信号的解耦处理,无需文本标签即可提高说话人识别准确性。该方法利用Gaussianinference和自监督学习策略,在VoxCeleb和SITW数据集上展示了有效性。
新加坡科研团队提出RecXi框架,通过语音信号的解耦处理,无需文本标签即可提高说话人识别准确性。该方法利用Gaussianinference和自监督学习策略,在VoxCeleb和SITW数据集上展示了有效性。

 论文链接:
论文链接:
https://arxiv.org/abs/2310.01128
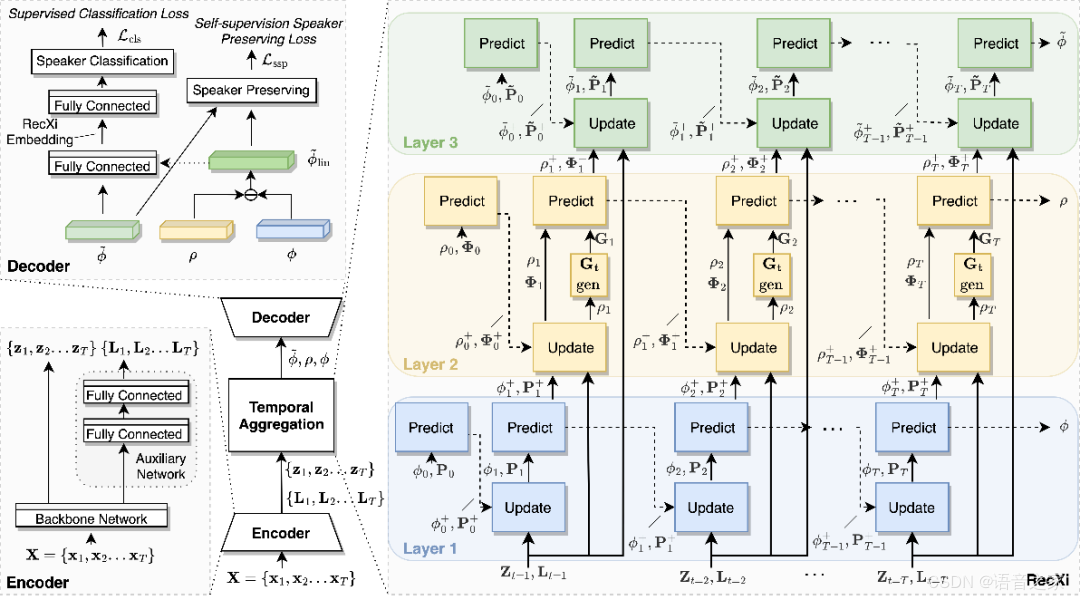
该研究由新加坡国家科技局(A⋆STAR)、新加坡国立大学、香港理工大学和香港中文大学(深圳)的研究人员共同完成。该项工作已被NeurIPS 2023(main track)接收。
对于说话人识别/验证(speaker recognition/verification)任务而言,提取准确的说话人表征(speaker representation)是非常困难的,因为语音信息中同时包含了说话人特征信息和语音内容信息[1]。
为了减少内容信息变化带来的影响,很多现有的工作使用phonetic信息作为特征提取的辅助信息[2-4]。而这种方法往往需要比说话人识别模型大很多的语音识别(ASR)模型[2],或者需要训练数据中包含文本信息的标签[3,4]。以说话人识别广泛使用的VoxCeleb数据集[5]为例,准确地标注超过百万条语音的文本标签是成本极高的。
为了解决上述问题,在这篇论文中,研究人员提出了一个新的解耦框架(disentanglement framework)。该框架可在只使用说话人标签,而文本标签缺失的情况下训练,完成对语音信号中说话人特
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









