




 本文介绍了一种新的端到端自动语音识别(ASR)技术——LODR,它能够更好地融合外部语言模型,提高识别准确性。通过使用低阶2-gram模型近似内部语言模型(ILM),LODR在多种场景下展现出优秀的性能,尤其在解码效率上更具优势。
本文介绍了一种新的端到端自动语音识别(ASR)技术——LODR,它能够更好地融合外部语言模型,提高识别准确性。通过使用低阶2-gram模型近似内部语言模型(ILM),LODR在多种场景下展现出优秀的性能,尤其在解码效率上更具优势。
本文介绍清华大学语音处理与机器智能实验室(Speech Processing and Machine Learning Intelligence, SPMI)与美团的联合工作:为端到端ASR(Automatic Speech Recognition)提出一种性能更好、解码更轻量的语言模型融合方式——LODR。该工作已被语音领域的国际会议Interspeech 2022接收,论文的作者是郑华焕、安柯宇、欧智坚、黄辰、丁科、万广鲁。

端到端识别系统与语言模型融合
端到端ASR系统,是通过一个神经网络模型,直接将音频序列转换为对应文本序列的识别系统。相对于传统混合模型中声学模型、发音词典和语音模型模块化建模的方式,基于深度神经网络的端到端系统通过一个网络对整个识别过程进行封装,并对网络参数整体进行优化,在大量音频-文本配对数据下性能突出,近年来逐渐受到学术界和工业界的重视。
相对于音频-文本配对数据而言,实际生产中获取纯文本数据成本更低,且可获取的纯文本数据往往比音频-文本配对数据多几个甚至几十个数量级。此外在一些如领域迁移、专有名词和热词识别等场景中,利用好文本信息也尤为重要。如何利用好海量的纯文本数据,进一步提升识别准确率,是目前端到端ASR研究的重要问题,也是数据高效ASR的重要特征。
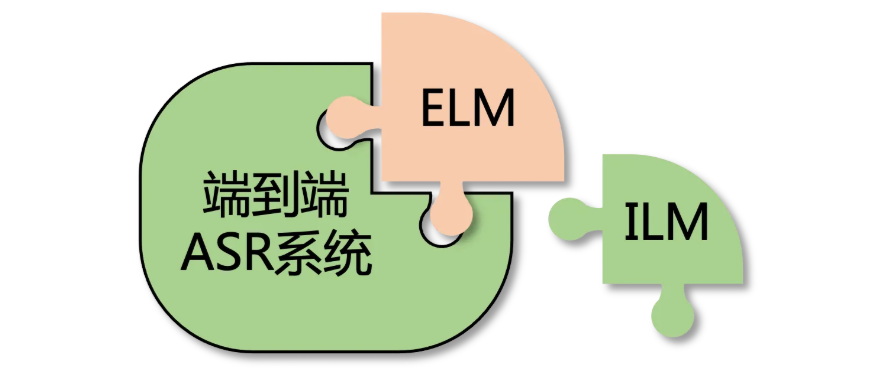
内部语言模型估计与解耦
目前,最为常用的在端到端ASR中利用文本的方式是,融合外部的语言模型(External Language Model, ELM),使用ELM学习文本信息,再与ASR系统融合。一个最常用的融合ELM的方式是,直接将ASR系统得分与ELM得分进行线性插值求和,即sh
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1625
1625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









