







这一章没空整理啦,盗用一个很喜欢的整理。链接放上:
传输层-Transport Layer(上):传输层的功能、三次握手与四次握手、最大-最小公平、AIMD加法递增乘法递减 - 猫猫子 - 博客园 (cnblogs.com)
6.1传输层概述
6.1.1 传输层概述
在网络层,我们使用VC和Datagram实现了链路上的通信;而传输层把传输服务扩展到了存在于两台计算机的进程上(provides end-to-end delivering),并强调提供一种可靠的跨网络传输方法。传输层的任务主要是:1.接收应用层的数据(并有可能需要切分成小段);2.发送数据段segment;3.区分属于不同进程的segment
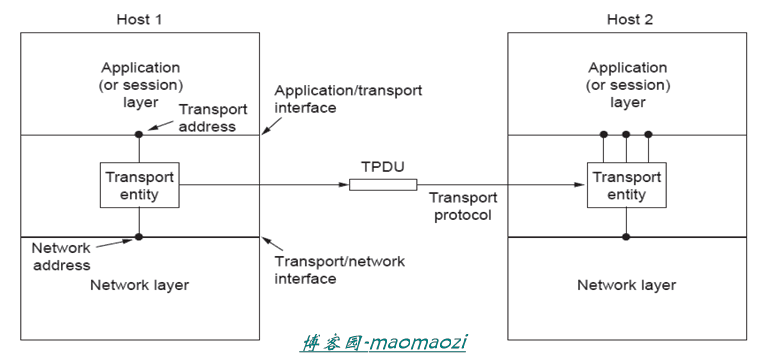
同时,传输层还决定了究竟提供哪种类型的服务。如果应用层不需要一种可靠的数据流(比如斗鱼一类的视频直播,就算有几帧帧画面的数据发生了错误也无伤大雅),那么传输层向网络层发送的数据就不会设计过多的差错控制及确认机制以节省资源;而反过来,如果应用层需要一种可靠的无错信道(虽然现实中不可能完全不出错),那么传输层发送给网络层的段就会包含序列号以保证顺序、ACK机制以应对丢包发生...此外,传输层还需要继续考虑拥塞控制的问题,因为仅仅凭借网络层是无法彻底解决网络拥塞的。
6.1.2 传输层提供给上层的服务
- 提供了面向连接的服务(如TCP)与无连接(如UDP)的服务。
6.1.3 传输服务原语
6.2 传输协议的要素
这部分将描述一些传输协议的要素(比如传输层如何寻址或者进行流量控制),为后面介绍TCP、UDP做好铺垫。但是这些要素并不是全部出现在传输层的所有协议之中。比如UDP协议就没有连接建立的过程。
6.2.1 寻址
传输服务的访问点:端口(port)
相对应的,网络层服务的访问点可以理解成:IP地址
6.2.2 传输建立(连接建立)
连接建立的过程是一个很经典的三次握手的过程。如下。
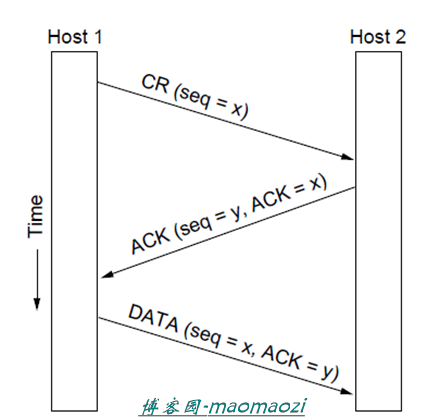
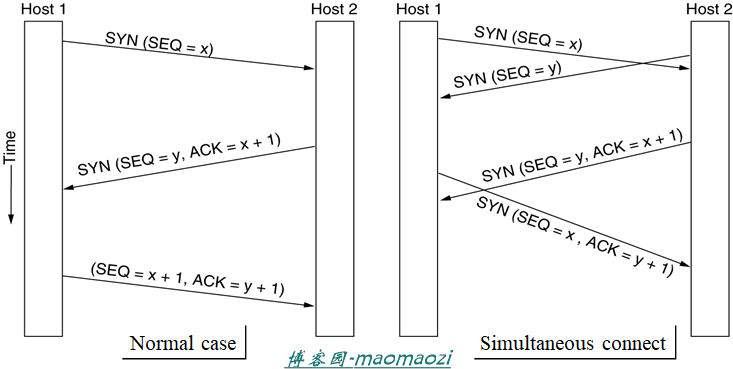
简单的三次握手其实包含了很多考量,如在连接建立时发送的序列号(是为了防止早先发送的数据包超时到达导致重复接受),以及设置的计时器,等等。主机发送一个连接建立请求(CR),接收方收到后返回一个ACK表示已经收到,并返回一个自己的起始需要y(Host2的后续数据包将从y开始发送),最后主机一把对于这一消息的确认夹带在需要发送的数据中。下面我们考虑几种特殊的情况(其实在实际的操作过程中是很容易发生的)
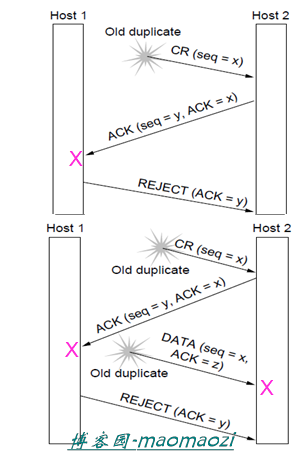
首先考虑上图的情况。主机1在很久之前向主机2发送了一个连接请求,而当这个请求真正到达的时候H1已经不再需要这个连接了。在这种情况下,尽管主机2并不知道到达的这个请求是否是真心实意的需要建立,H2仍旧可以通过确认机制实现对于数据包的判断(如,H1已经不需要这个连接,就会向H2发送拒绝的数据)
在下图这种情况中,H1所发送的超时CR和超时DATA同时存在于网络中。当H2收到一个请求后,照常发出一个ACK等待H1开始发送数据(此时H2并不知道这是一个已经过期的请求)。而下一刻,当超时的DATA数据包也到达H2,H2经过判断发现这个数据包的ACK和自己发送的确认序列号不符(y和z),所以判断出这是一个超时的数据包,继续等待H1的回复。
总而言之,在传输层,三次握手的存在使得老的段的任何组合都不会让协议失败,主机间也不会出人意料的建立一个连接。
6.2.3 连接释放(2)
连接释放的问题相对复杂。一个典型的例子是两军对垒问题(感兴趣的同学可以搜索一下,这里不再花费大量篇幅展开)。总之,不存在一种两方都完全确认并做好准备的释放连接。现在的释放连接方法分成两种,对称释放与非对称释放
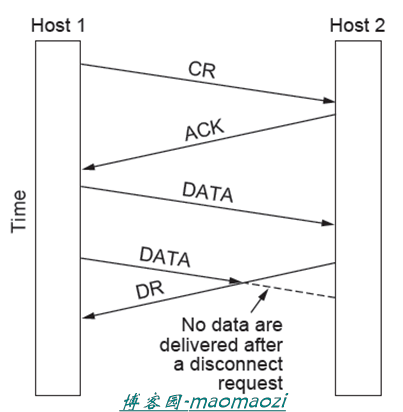
非对称释放
例如电话,在一方挂机之后连接直接断开
对称释放
将一个连接看成是两个单向的连接,需要分别单独释放。
6.2.3 差错控制&流量控制
在之前的内容里,我们已经讨论过链路层和网络层的流量控制。
差错控制:确保数据传输具备可靠性(所有的数据被无差错的传输至目的地)
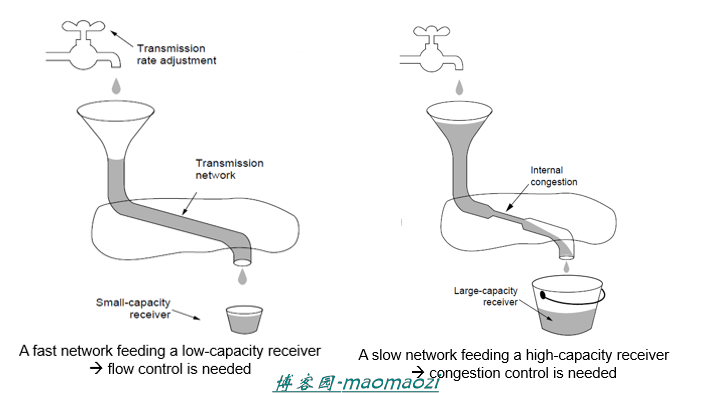
流量控制:防止快速发送端淹没慢速接收端
这两个问题已经在链路层考察过,而在传输层,我们采用了和链路层基本一致的解决方案,即:
- 帧中携带一个验错码(如CRC或者checksum),在接收端检测信息是否正确。
- 使用自动重复请求(ARQ)
- 使用停-等式协议
- 使用滑动窗口
6.2.4 多路复用(可以解决地址匮乏问题!!!!)
除了在网络层讲到了的三种解决方案之外,在传输层还有一个方法可以用于缓解地址匮乏问题,那就是多路复用(multiplexing)。
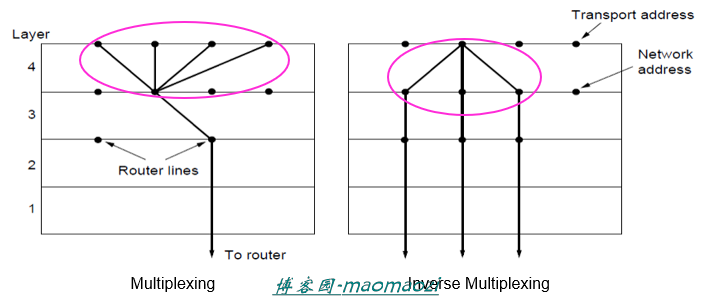
上图中左图使用的方法就是多路复用。同一个地址上到达的端,分给不同的进程(前面已经讲过传输层和网络层接入点的问题)。相对应的,另一种方法称为逆向多路复用,即把一个连接的流量分给多条路径。通过逆向多路复用,传输层可以合并多条低速链路,把他们当作一条高速链路来使用。
6.3 传输层拥塞控制
如果读者还能想起来,在网络层中,我们说到拥塞控制需要网络层与传输层的共同努力。下面的内容将解释传输层如何进行拥塞控制
拥塞控制的唯一途径就是减少传输层向下发送数据包的速度。
6.3.1 最大-最小公平
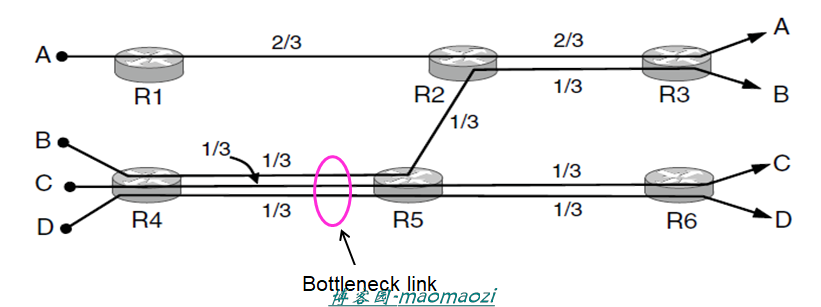
上图很形象的阐述了最大最小公平的原则:如果分配给一个流的带宽,在不减少分配给另一个流带宽的前提下,无法得到进一步增长,那么就不分配给这个流更多带宽。
这个定义绕来绕去不好理解,我们还是用图片来阐释。上图中存在6个路由器、一个工字形的链路以及ABCD四条数据流。我们假设每一段链路的最大上限都是1。任意拿一条流距离,分配给B流的带宽,在不减少其它流的前提下已经无法再进一步增长(比如再R4和R5之间已经达到了瓶颈,不能再增加了)。同理用A流举例来说,尽管在R1R2之间没有到达流量上限,但是A流在R2R3之间已经达到了上限(如果不减少流B就无法进一步增长),全部判断之后,我们可以说这种分配是符合最大-最小公平的。读者可以自行判断一下流C和流D。
6.3.2 调整发送速率
然而,单独依靠最大-最小公平仍旧不足以使每个流都公平的分配到最大带宽。下面介绍的内容将是传输层一个重点算法的基础。
在传输层,发送速率会受到两个因素的影响。分别是流量控制和拥塞控制。当接收端没有足够的缓冲区,据必须进行流量控制;而拥塞控制针对的是网络层容量不足的情况,如下图。
加法递增与乘法递减:AIMD-additive increase and multiplicative decrease
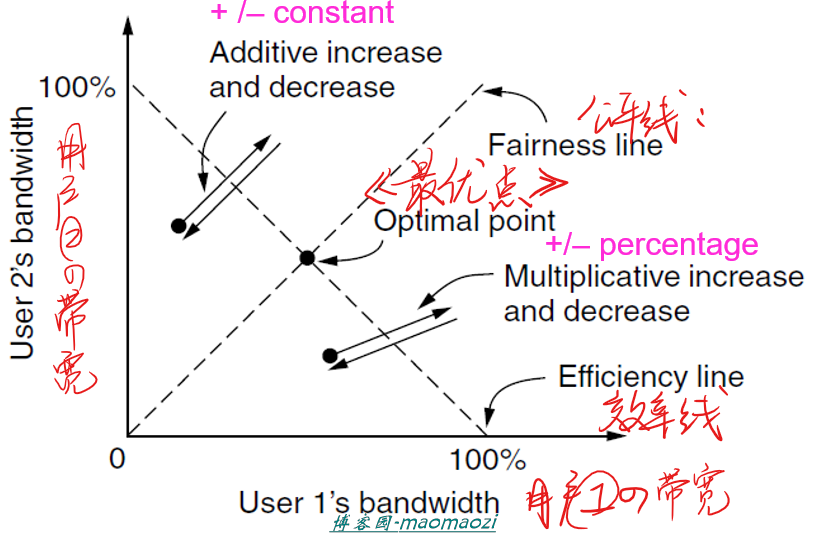
我们还是通过图片来理解。假设在某一条网络上存在两个用户(或着说,两个数据流)同时需要占用带宽。我们构建一个坐标系,横轴是用户1的实际带宽,纵轴是用户2的带宽,网络的总容量为C。由于两个用户处于一个网络下,易知对于任意的x,y,一定存在:
当x+y=c,这条网络的带宽被全部占满,我们称这条曲线位效率线。同时,对于x和y两个用户来说,为了维持收发速度的公平,两个用户应该能够获取相同大小的带宽,即:
这条线被称作公平线我们把这两条曲线表示在刚刚的坐标系中,他们的交点被称作最优点。这是每一个网络希望达到的理想状态。因此现在的问题是,网络应该采取何种策略,到达之前所说的公平点呢?我们给出的答案称作加法递增与乘法递减控制法。
所谓加法,指的是同时增加或减少用户1和用户2 的带宽;而所谓乘法,指的是按照比例改变用户1和用户2的带宽。可想而知,如果在图像上表示这两种更改方式,加法一定是一条斜率为1的直线,乘法一定是一条过原点的直线。
而之所以加法只用在增加,乘法只用在减少,是由于TCP拥塞控制中的稳定性观点:驱使网络拥堵非常容易,而想要使其恢复,则相对困难。因此,递增策略应相对温柔,递减策略应相对积极。
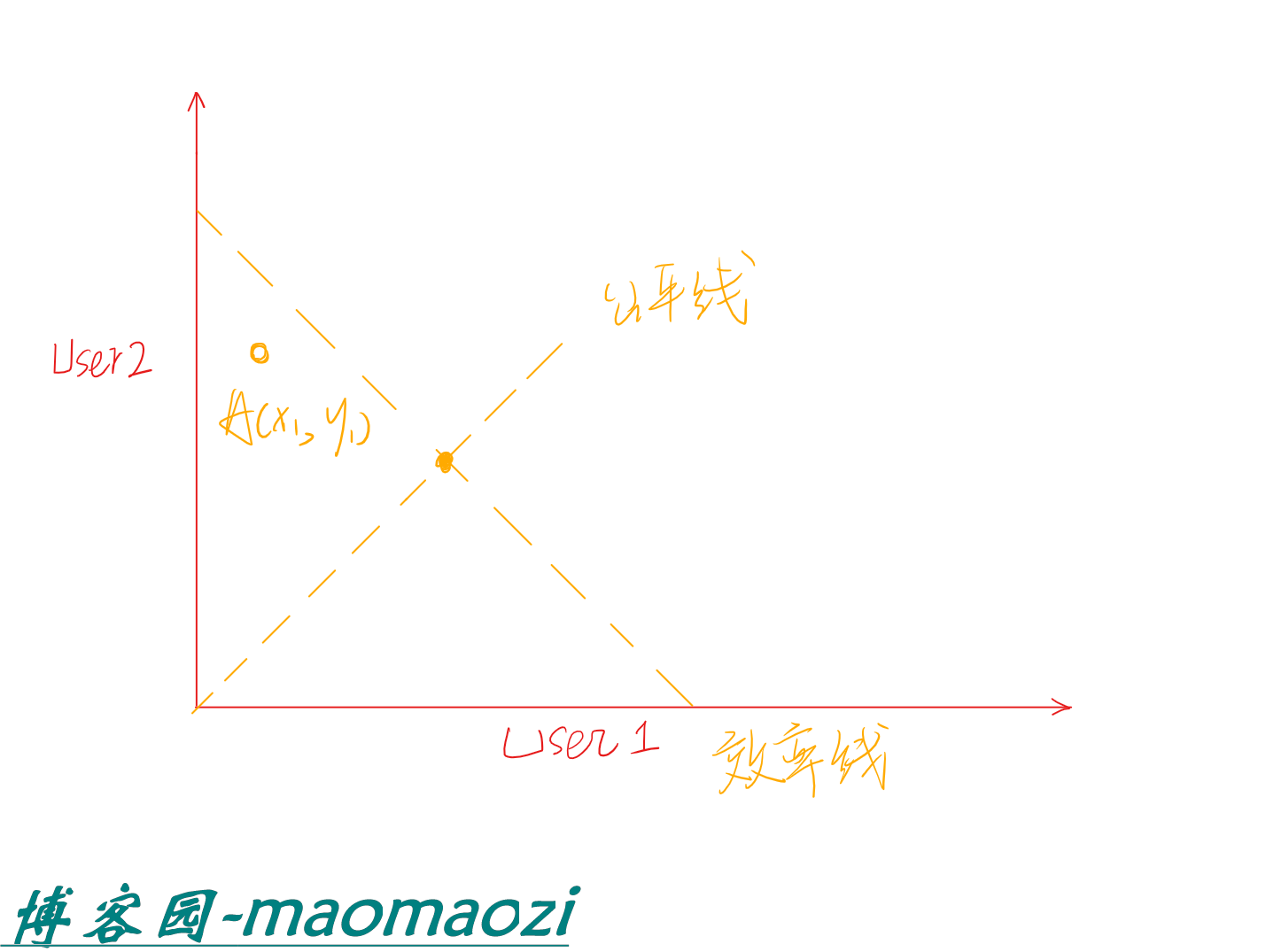
对于刚才的网络,我们假设当前网络的效率处在A点。(即用户1 的带宽位x1,用户2的带宽为x2)
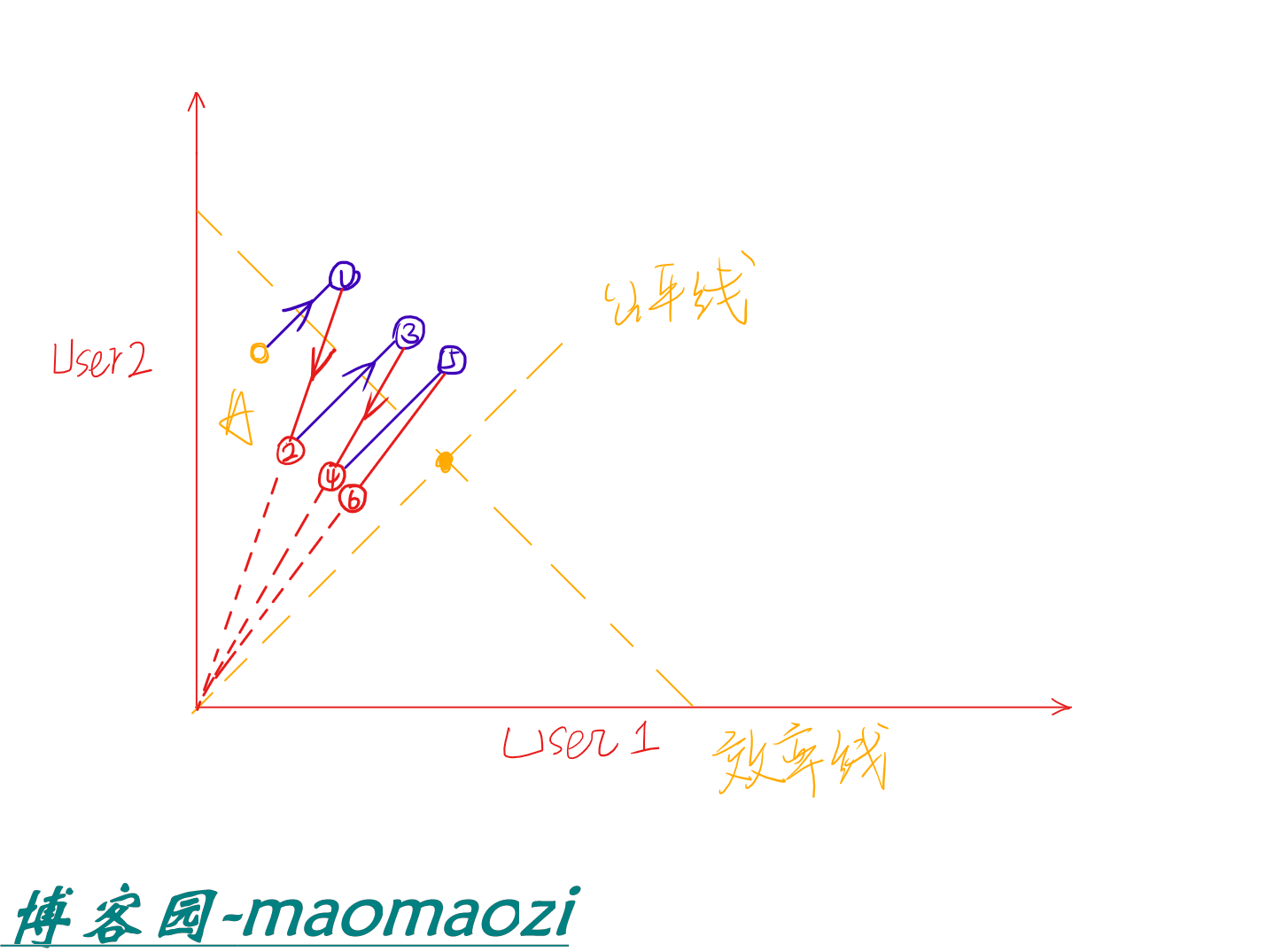
从A点开始,首先进行加法递增(蓝紫色实线)。当X+Y到达1号点,超出了网络的容量之后,网络层会向用户发送一个拥塞信号,这是各个用户开始使用乘法递减原则,共同减少自己占用的带宽,到达2号点(路径为途中红色实线)。反复执行这一流程多次后,系统会慢慢趋近最优点。
AIMD是TCP采用的拥塞控制法则。但这个法则不是完全的公平。因为TCP每次都要根据往返时间测量值来调整窗口的大小,所以接近主机的连接往往比距离远的连接要获得更多带宽(距离近则往返时间短)。
6.4 Internet传输协议:UDP/User Datagram Protocol
6.4.1UDP特点

上图是UDP的头。UDP的头很短,只包含源和目标端口号、长度和校验和四个项。
- UDP是一种无流控、无连接、不可靠的报文流(对比TCP)
- 目标端口号一共有16位长,用于区分不同进程
- UDP没有包括流量控制、拥塞控制或者是重传机制。所有的这些都需要用户进程自己完成。而UDP本身只是提供了一个与IP协议的接口。
- UDP伪头:是一个虚拟的数据结构,不是UDP头中的实际部分。伪头的存在主要是为了计算校验和,保证到达的UDP包确实是发送给自己的(因为UDP头中只含有端口信息,并没有IP地址)。这么做的原因详见6.7Faq。TCP和UDP都有伪头
下面介绍两个使用了UDP的经典协议。
6.4.2 远程过程调用:Remote Produce Call
- 允许一台计算机上的进程调用另外一台计算机上的进程
- 是一个分布式C-S系统的例子
6.4.3 实时传输协议: Realtime Transport Protocol
- 应用于多媒体应用,如网络电台、视频会议RTP的头设有一个序号(Sequence Number)字段,解决了UDP发送无序的问题
- RTP位于应用层,但是使用了UDP的传输协议
6.5 Internet传输协议:TCP/ Transport Control Protocol(重要!)
终于到了本章最后一个也是最重要的部分:TCP协议。我们之前已经简述了三次握手、AIMD等基本概念,下面将深入的展开这些概念,并明白他们是如可确保TCP连接可靠性的。
- TCP是一种可靠的、面向连接的端对端的字节流(Bytestream)(对比UDP)
6.5.1 TCP服务类型
- TCP连接是全双工的、不支持组播或者广播
- TCP的连接是字节流,意味着不保留消息的边界(6.6会详细解释)
6.5.2 TCP报头(head)

注意关注TCP报头的以下几个字段:
-
序号sequence number:用来进行排序,保证数据内容有序
-
序号+确认号:为TCP滑动窗口服务(稍后会提到)
-
TCP头长度TCP header length:标记TCP头具有多少个32位信息,以区分报头和载荷(由于TCP头有两个位置是可选长度,故不确定长度)
-
校验和CheckSum:用于差错控制,保证可靠性,也有IP伪头。
-
8位标志位:SYN用于建立连接;ACK是确认;FIN是释放连接;CWR与ECE用于拥塞控制
-
窗口大小:用于流量控制(滑动窗口)
6.5.3 TCP连接建立
TCP连接建立使用的即是我们之前描述的“三次握手”的过程。注意明确两个主机之前各自的SEQ和ACK序号是怎么确定的。
6.5.4 TCP连接释放
TCP的连接释放属于对称释放,记成“四次握手”
由主机1发送一个断开连接请求,表示内容已经传送完毕,主机2确认。主机2随后也发送一个断开连接请求,主机1确认后连接正式断开。
6.5.5 TCP滑动窗口
我们在之前已经讲过了链路层的滑动窗口。而在传输层,TCP的滑动窗口是依靠TCP报头中的序号字段和确认号字段实现的。通过滑动窗口,TCP可以合理的调整发送的流量,减少拥塞现象的发生。下面用图片来解释。
假设接收方拥有一个大小为4kb的缓冲区。传输层每次接收到消息之后就会发送至这个缓冲区,同时系统也会以另一个速率从缓冲区读取信息。流量控制的目的就是维持一个合适的速率使得整个缓冲区既不溢出也不会浪费资源。此时连接已经建立,由发送方先开始发送数据。每次收到数据后,发回的ACK都包含一个字段提示自己的缓冲区余量。如果缓冲区已满,发送端就会将自己阻塞一段时间。
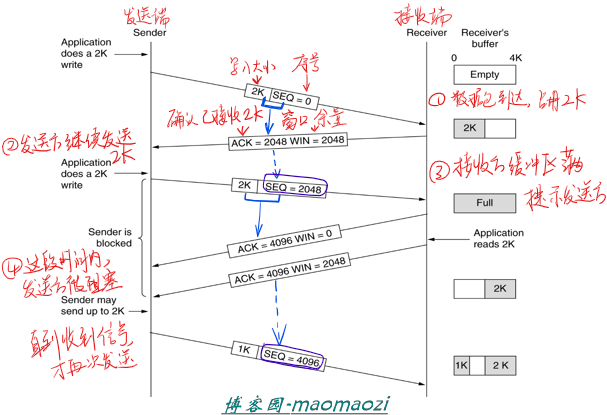
这里需要特别注意的还是ACK与SEQ字段大小该如何设置。SEQ字段只属于发送端,其含义大概可以理解为“已经发送了多少数据”,因此其大小等于上一个数据包中收到的ACK大小;而ACK表示的是“已经接受了多少数据”,其大小等于上一个发送端发来的数据包序列号+本次收到的数据大小。
此外,降低TCP性能的另一个原因是低能窗口综合症。当接收端每次只能读取很少的字节(假如在上面这个例子中,接收方每次刚刚读取了0.5k之后就通知发送方),整个系统会产生大量的冗余信息。解决的方法是强制接收方在有了一定大小的空间之后再通知对方。
6.5.6 TCP计时器管理
这一部分的内容主要是关于如何设置一个合适的时间界限判断数据包是否应该由于超时而被丢弃。
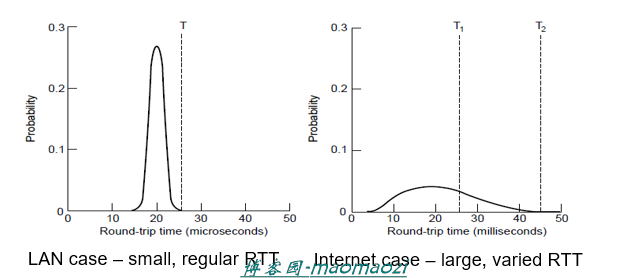
通过上图我们可以看到,再数据链路层中(左图),数据包到达的时间的概率密度函数相对比较集中,因此很容易设置一个界限来判断是否超时;但是在网络层下数据包到达的时间则更加分散,很难设置一个判断标准。解决的方法是使用一个依据网络情况的动态算法。
6.5.7 TCP拥塞控制(重要!)
首先简短回忆一下:网络层检测到拥塞后,会通过丢弃数据包来缓解拥塞。在传输层,我们可以使用AIMD控制法来优化网络容量。TCP的拥塞控制就以AIMD为基础,并加以改进。
拥塞窗口
TCP维护了一个拥塞控制窗口CWND-congestion window,窗口大小是任意时刻,发送端可以向网络发送的字节数。通过使用窗口大小/连接的往返时间,可以得到发送速率。TCP根据AIMD规则调整CWND大小。除此之外,TCP本来就有一个流量控制窗口RWND,指出了接收端可以接受的最大字节数,TCP最终的可能发送字节数就是两个窗口中的最小值。
相比起存放在报头中的RWND,CWND窗口维持在发送端本地,不会随着数据包发送。
确认时钟
确认时钟作用在之前讲到的CWND(拥塞控制窗口)上,其目的是提供一个可靠的发送速率。人们根据观察得出:一条确认消息返回到发送端的速率恰好是数据包通过路径上最慢链路的速率,这个时序就是确认时钟。通过使用确认时钟,数据包不会拥塞链路上的任意一个路由器,使得TCP能够平滑输出流量并且避免不必要的路由器队列。
慢速启动-slow start
之后的几个问题研究的是如何维持一个合适的CWND。尽管AIMD规则提供了一个比较好的思路,但是假如CWND从一个很小的规模就开始应用AIMD,则需要很长的时间才能收敛至最优点。人们因此提出了快速启动的观点:每一个被确认的段允许发送两个段,每经过一个往返时间,拥塞窗口增加一倍。

图中,RTT表示往返时间。如果数据包在一个往返时间内收到,那么表示当前的网络状况为通畅。慢速启动方式其实并不慢,CWND窗口的增长是指数级的。但相比之前的做法(直接发送RWND窗口大小的数据作为开始点),慢速启动又相对的慢一些。此外,还有必要为慢速启动设置一个慢速启动阈值,一旦超出了阈值,TCP就会从慢速启动切换到线性增加-additive increase(也就是我们在AIMD中学到的知识)。在每一个RTT末尾,发送端额外注入一个数据包。

快速重传-fast retransmission
慢速启动的缺陷是必须设置一个更加保守的超时判断时间来防止因重复数据包太多导致的网络拥塞,因此可能会降低网络效率。使用重复确认(duplicate ack)机制可以部分解决这个问题:当丢失数据包的后续数据包到达接收端时,他们所触发的返回确认全部拥有相同的确认号。当发送方收到多个确认号相同的数据包后,那么就可以推断出某个数据包已经丢失(或者至少是超时)。
在TCP中,这个重复确认的数量通常被设置成3。当收到了三个连续的重复确认,发送端默认这个包已经超时,直接重新发送这个数据包(在判断超时的计时器结束之前),这么一来就缩短了等待时间。这种方法叫做快速重传。当重新发送之后,发送端会把自己的CWND阈值设置为之前CWND值的一半,并从0开始慢速启动。
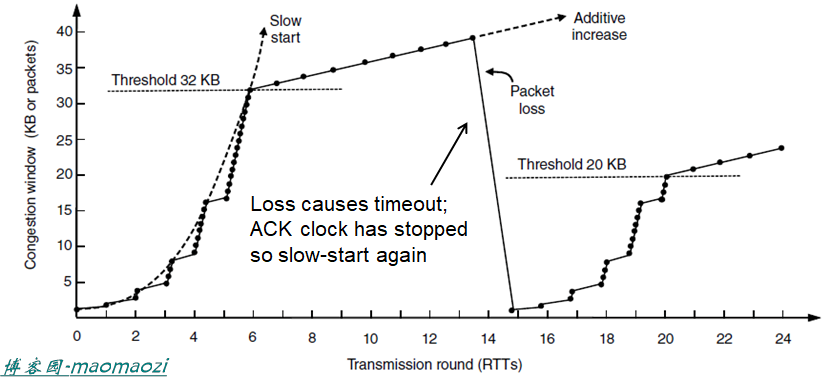
如上图,慢速启动的第一个阈值被设置成32KB,并在CWND=40时发生丢包现象。丢包被检测到之后,确认时钟停止;新的阈值被设置为40KB 的一半-->20KB;重新从0开始,执行慢速启动。这是一种阶梯状的模式。
快速恢复-fast recovery
快速恢复是一种新的机制,用于确保拥塞窗口上能够持续运行确认时钟。也就是说,除非是第一次启动,其他时候不会进入慢速启动,而是直接从阈值开始线性递增。这是一种锯齿状的模式。
现在重新观察TCP拥塞控制的这张图片不难发现,其实线性递增部分就是对应着上一篇博文AIMD中的加法递增部分,而快速恢复机制对应了AIMD中的乘法递减部分(乘以1/2)。只不过上一篇中的AIMD图像表现的是两个发送端的流量变化关系,而上图表现的是一个客户端的流量随着时间的变化关系(时间是横坐标)。
6.6 TCP与UDP区别比较
| TCP | UDP |
|---|---|
| TCP面向连接,提供可靠的服务。 意味着TCP会使用校验和确保数据正确,使用序号确保数据有序到达且不重复,使用ACK机制重新发送丢失的数据包,并且包含连接建立和断开的过程。 | UDP提供的是无连接的服务,并不可靠。 UDP不包含序号和ACK重传等机制。(当应用层拥有一些特殊需求时,应用层可以调整自己的格式以提供一些特殊服务,例如实时传输协议RTP) |
| TCP具有拥塞控制的功能,使用改进的AIMD规则来减少拥塞 | UDP没有拥塞控制,当网络层出现拥塞时,也不会使得源主机的发送速率降低。 |
| TCP连接只支持单播,一定是点到点的。 | UDP可以进行单播、多播、广播。 |
| TCP使用字节流,不保留消息边界。当数据过大的时候会进行拆分。 | UDP面向报文流,会保留应用层提供的消息边界。 |
| TCP的首部更长,传输速度相对较慢 | UDP的首部较短,传输速度也更快。 |
另外关于报文流和字节流,下图可以更方便理解。
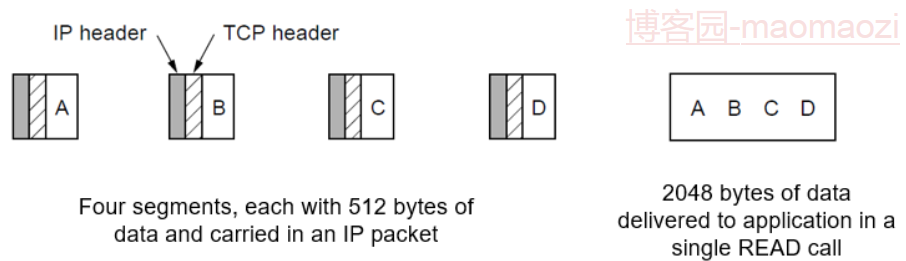
假如应用层提供了一个2048字节大小的数据等待发送,TCP可能会将其拆分成4个512字节大小的数据段,分别发送给网络层,接收方再负责组合。真正发送的数据包并不是应用层的数据,因此称为没有保留消息边界。
再来看另外一个例子,当客户分别发出32B和64B的包,流式的如TCP发送时是将32B+64B=96B的一个包发出,另一边收到的也是96B的包,TCP不再保留原来数据包的边界,而是根据协议的需求将数据统一发送;而对于UDP来说,服务器端收到的就是32B和64B的两个包,保留了从前数据包的边界。当然,包大小取决于协议和网络。
6.7 FAQ 常见问题
为什么要区分网络层和传输层?
的确,传输层和网络层有诸多的相似之处,并且共同负责了包括拥塞控制在内的多个问题的解决。但是分出两个层次依旧是必要的。
一般情况下来说,传输层的代码都运行在用户的机器上,如PC机,或者服务器;而网络层的代码大部分部署在由运营商操作的路由器上。这样的差别是设计区分这两个层次的主要原因:用户对网络层并没有真正的控制权,因为他们不拥有路由器;而另一方面,路由器也没有权限在数据包发生丢失等情况后要求PC机重新发送这个数据包。
UDP和TCP为什么需要伪头(pseudoheader)?
伪头存在的目的是为了帮助传输层的进程再一次确认该数据包确实属于这个进程所在的ip地址。问题在于,为什么传输层还需要再做一遍网络层的工作呢?难道到达网络层的时候不是已经校验过IP地址的准确性了吗?理论上来讲确实是这样的。然而在实际应用中确实会发生错发的现象,网络层可能会把一个数据包发至错误位置。例如路由出错,或者是数据包的ip头被修改了(前一章中的NAT盒子就可能会引起这一点)。
传输层的校验和与链路层的校验和有什么关系?
没有什么关系。传输层的内容会被一路封装下去,成为链路层的载荷之一。而校验和是存在各自的头部,用于校验某一层的数据是否正确。比如连链路层的校验和只管链路层。当然这两层可能采取了同一种算法。
传输层所谓“面向连接的服务、无连接的服务”与网络层“面向连接的服务、无连接的服务”之间有什么不可告人的关系?
在传输层,我们学到了TCP、UDP两种有连接和无连接的服务。同样在网络层,也存在两种以有无连接区分的服务数据报和虚电路。这两层的服务模式有什么关系?传输层使用TCP是否意味着网络层也要使用虚电路?
答案是没什么关系。举一个最简单的例子:在链路层我们了解到了有确认无连接的802.3和无确认无连接的802.11。难道使用TCP的数据段不可以在以太网和无线局域网链路上传输吗?这显然是不可能的。
这个问题部分涉及到了计算机网络分层的原因。在考虑传输层功能的时候,我们可以暂时不考虑其底层的网络层、链路层和物理层,直接想象成应用A把数据发送给了一个黑盒,之后黑盒通过某种方法把数据交给应用B。在这个过程中,A和B可以不考虑小黑盒是如何实现的。根据协议的不同,路由器可以把数据交给不同的链路传送,而所谓连接,并不是一定要有一条固定不变的实际线路。实际上,面向连接的服务只意味着协议需要在发送数据之前建立连接,并在传输结束折后释放连接。例如,在传输层选择了TCP协议,意味着传输层的两个应用之间需要向小黑盒发送一系列的建立和释放连接请求(三次握手和四次握手);而至于网络层如何发送传输层的这些数据、链路层如何发送网络层的这些数据,TCP本身并不关心(甚至也管不着)。当然生活中,我们通常使用TCP/IP协议簇,其中的IP协议是使用数据报的,但并不能理解为“传输层有连接的服务在网络层一定也是有连接的”。归根结底,传输层所谓连接,描述的是一条虚拟的链路。其与网络层连接的交集仅在于涵义上,并不是包含关系。

















 2016
2016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









