






 本文详细介绍了如何使用Python的re库进行HTML文件解析,讲解了正则表达式的常用操作符,如点号、字符集、非字符集等,并列举了re库的主要功能函数,如search、match、findall等。通过实例展示了如何从HTML文本中提取所需信息,为网页抓取和数据提取提供了实用技巧。
本文详细介绍了如何使用Python的re库进行HTML文件解析,讲解了正则表达式的常用操作符,如点号、字符集、非字符集等,并列举了re库的主要功能函数,如search、match、findall等。通过实例展示了如何从HTML文本中提取所需信息,为网页抓取和数据提取提供了实用技巧。
三、解析内容
3.1 对爬取的HTML文件进行解析
3.1.1 制定解析规则
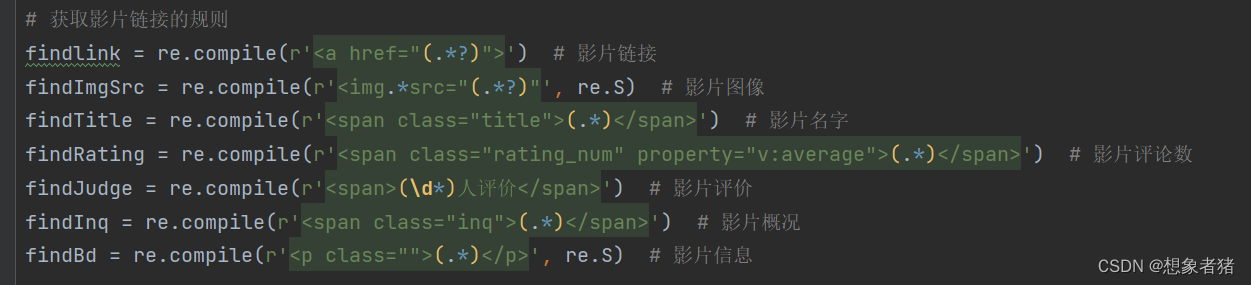
利用正则表达式来检索html文本中所需要的信息。
正则表达式的常用操作符:
| 操作符 | 说明 | 实例 |
| . | 表示任何单个字符 | |
| [] | 字符集,对单个字符给出取值范围 | [abc]表示a、b、c,[a-z]表示a到z单个字符 |
| [^] | 非字符集,对单个字符给出排除范围 | [^abc]表示非a或b或c的单个字符 |
| * | 前一个字符0次或无限次扩展 | abc*表示ab、abc、abcc、abccc等 |
| + | 前一个字符1次或无限次扩展 | abc+表示abc、abcc、abccc等 |
| ? | 前一个字符0次或1次扩展 | abc?表示ab、abc |
| | | 左右表达式任意一个 | abc|def表示abc、def |
| {m} | 扩展前一个字符m次 | ab{2}c表示abbc |
| {m,n} | 扩展前一个字符m至n次(包含n) | ab{1,2}c表示abc、abbc |
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串开头 |
| $ | 匹配字符串结尾 | abc$表示abc且在一个字符串结尾 |
| () | 分组标记,内部只能使用|操作符 |
(abc)表示abc,(abc|def)表示abc、def |
| \d | 数字,等价于[0-9] | |
| \w | 单词字符。等价于[A-Za-z0-9_] | |
re库主要功能函数:
| 函数 | 说明 |
| re.seach() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
修饰符:
| 修饰符 | 描述 |
| re.i | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使匹配包括换行的所有字符 |
| re.U | 根据Unicode字符祭解析字符,这个标志影响\w,\W,\b,\B |
| re.X | 该标志通过给予你更灵活的形式以便你将正则i表达式写的更易于理解 |

















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









