








1. 归一化
1.1 距离类模型归一化的需求
什么是归一化呢?我们把X放到数据框中来看一一眼, 你是否观察到,每个特征的均值差异很大?有的特征数值很大。有的特征数值很小,这种现象在机器学习中被称为"星纲不统一"。 NN是距离类模型,欧氏距离的计算公式中存在若特征上的平方和:
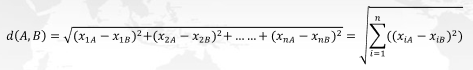
试想看看,如果某个特征x的取值非常大,其他特征的取值和它比起来都不算什么,那距离的大小很大程度上都会由这个巨大特征x来决定,其他的特征之间的距离可能就无法对d(A,B) 的大小产生什么影响了,这种现象会让KNN这样的距离类模型的效果大打折扣。然而在实际分析情景当中,绝大多数数据集都会存在各特征值量纲不同的情况,此时若要使用KNN分类器,则需要先对数据集进行归一化处理, 即是将所有的数据压缩都同一个范围内。
1.2 preprocessing.MinMaxScaler
当数据(x) 按照最小值中心化后,再按极差(最大值最小值)缩放,数据移动了最小值个单位,并且会被收敛到[0,1]之间,而这个过程,就称作数据归一化(Normalization, 又称Min-Max Scaling)
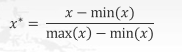
在sklear当中,我们使用preprocessing.MinMaxScaler来实现这个功能。MinMaxScaler有 一个 重要参数,feature. range, 控制我们希望把数据压缩到的范围,默认是[0, 1]。
1.3 先分数据集,再做归一化!
最初的时候,为了让大家能够最快地看到模型的效果变化,这里直接在全数据集X上进行了归一化,然后放入交叉验证绘制学习曲线,这种做法是错误的,只是为了教学目的方便才这样操作。真正正确的方式是,先分训练集和测试集,再归一化!
为什么呢?想想看归一化的处理手段, 我们是使用数据中的最小值和极差在对数据进行压缩处理,如果我们在全数据集上进行归一化,那最小值和极差的选取是会参考测试集中的数据的状况的。因此,当我们归一化后,无论我们如何分割数据,都会由一部分测试集的信息被"泄露”给训练集(当然,也有部分训练集的信息被泄露给了测试集,但我们不关心这个), 这会使得我们的模型效果被高估。在现实业务中,我们只知道训练集的数据,不了解测试集究竟会长什么样,所以我们要利用训练集.上的最小值和极差
来归一化测试集。
1.4 实现归一化
# 归一化
from sklearn.preprocessing import MinMaxScaler
data = [[-1,2],[-0.5,6],[0,10],[1,18]]
# 如果换成表是什么样子?
d = pd.DataFrame(data)
d
# 实现归一化
scaler = MinMaxScaler()
scaler.fit(d)
scaler.transform(d)

或者
# 训练和导出结果一步达成
scaler.fit_transform(d)

from sklearn.preprocessing import MinMaxScaler as mms
data = load_breast_cancer()
x = data.data
y = data.target
MMS = mms()
MMS.fit(x) # 先训练数据
x_new = MMS.transform(x) #再对数据进行归一化
#不能先对数据进行归一化,再对数据进行训练
#因为先做归一化就先知道测试集的信息,导致产生信息的泄露
score = []
var_ = []
krange=range(1,20)
for i in krange:
clf = KNeighborsClassifier(n_neighbors=i)
cvresult = CVS(clf,x_new,y,cv=5)
score.append(cvresult.mean())
var_.append(cvresult.var())
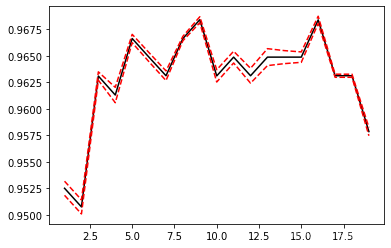
plt.plot(krange,score,color='k')
plt.plot(krange,np.array(score)+np.array(var_)*2,c='red',linestyle='--')
plt.plot(krange,np.array(score)-np.array(var_)*2,c='red',linestyle='--')
# pd.Series(score, index = krange).idxmax()
print(bestindex)
print(score[bestindex])
2.距离的惩罚
2.1 以距离作为惩罚因子的优化
用最近邻点距离远近修正在对未知分类过程中,“- 点一票”的规则是KNN模型优化的一个重要步骤。也就是说,对于原始分类模型而言,在选取最近的k个元素之后,将参考这些点的所属类别,并对其进行简单计数,而在计数的过程中这些点“一 点-票”,这些点每个点对分类目标点的分类过程中影响效力相同。但这实际上是不公平的,就算是最近邻的k个点,每个点的分类目标点的距离仍然有远近之别,而近的点往往和目标分类点有更大的可能性属于同一类别(该假设也是KNN分类模型的基本假设)。因此,我们可以选择合适的惩罚因子,让入选的k个点在最终判别目标点属于某类别过程发挥的作用不相同,即让相对较远的点判别效力更弱,而相对较近的点判别效力更强。这一点也可以减少KNN算法对k取值的敏感度。
2.2 重要参数: weights
关于惩罚因子的选取有很多种方法,最常用的就是根据每个最近邻x;距离的不同对其作加权,加权方法为设置w;权
重,该权重计算公式为:
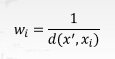
这里需要注意的是,关于模型的优化方法只是在理论上而言进行优化会提升模型判别效力,但实际应用过程中最终能否发挥作用,本质上还是取决于优化方法和实际数据情况的契合程度,如果数据本身存在大量异常值点,则采用距离远近作为惩罚因子则会有较好的效果,反之则不然。因此在实际我们进行模型优化的过程当中,是否起到优化效果还是要以最终模型运行结果为准。
在sklearn中,我们可以通过参数weights来控制是否适用距离作为惩罚因子。
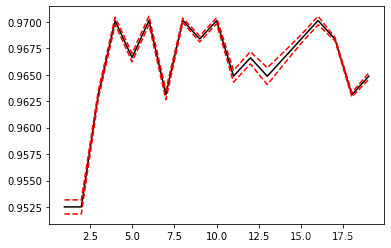
weights = 'distance'
score = []
var_ = []
krange=range(1,20)
for i in krange:
clf = KNeighborsClassifier(n_neighbors=i, weights = 'distance')
cvresult = CVS(clf,x_new,y,cv=5)
score.append(cvresult.mean())
var_.append(cvresult.var())
plt.plot(krange,score,color='k')
plt.plot(krange,np.array(score)+np.array(var_)*2,c='red',linestyle='--')
plt.plot(krange,np.array(score)-np.array(var_)*2,c='red',linestyle='--')
#pd.Series(score, index = krange).idxmax()
print(bestindex)
print(score[bestindex])
结果
12
0.9648657040832169



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









