







正则表达式概述
介绍
在实际开发过程中,经常会查找符合某些复杂规则的字符串需要。比如:邮箱、图片地址、手机号码等,这个时候想匹配或者查找符合某些规则字符串就可以使用正则表达式了。
概念
正则表达式就是就是记录文本规则的代码
re模块
书写格式
import re
# 使用match方法进行匹配操作
result = re.match(正则表达式,要匹配的字符串)
# 如果上一步匹配数据的话,可以使用group方法来提取数据
result.group()
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
#author:tangyl
import re
# 使用match方法进行匹配操作
result = re.match("hel","hello")
# 如果上一步匹配数据的话,可以使用group方法来提取数据
result1 = result.group()
print(result1)
匹配单个字符
| 符号 | 功能 |
|---|---|
| . | 匹配任意一个字符,除\n |
| [] | 匹配[]中列举的字符 |
| \d | 匹配数字即0-9 |
| \D | 匹配非数字 |
| \s | 匹配空白(空格、tab键) |
| \S | 匹配非空白 |
| \w | 匹配非特殊字符,即a-z、A-Z、0-9、汉字 |
| \W | 匹配特殊字符,即非a-z、A-Z、0-9、汉字 |
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
#author:tangyl
import re
from tkinter import W
# 匹配单个字符
# .(匹配任意一个字符,除了\n)
match_obj = re.match("t.o","t\no")
if match_obj:
result = match_obj.group()
print(result)
else:
print("输出失败!")
# [](匹配[]中列举的字符)
match_obj = re.match("葫芦娃[12]","葫芦娃1")
if match_obj:
result = match_obj.group()
print(result)
else:
print("输出失败!")
# /d => 0-9
# 匹配银行卡中的一位
match_obj = re.match("[\d]","74552")
if match_obj:
result = match_obj.group()
print(result)
else:
print("输出失败!")
# \D:匹配一个非数字字符
match_obj = re.match("[\D]","a")
if match_obj:
result = match_obj.group()
print(result)
else:
print("输出失败!")
# \s:匹配空白字符(空格或者tab键)
match_obj = re.match("葫芦娃\s[12]","葫芦娃 1")
if match_obj:
result = match_obj.group()
print(result)
else:
print("输出失败!")
# \S:匹配非空白字符(空格或者tab键)
match_obj = re.match("葫芦娃\S[12]","葫芦娃+1")
if match_obj:
result = match_obj.group()
print("非空白",result)
else:
print("输出失败!")
# \w 匹配特殊字符
# 匹配某网站密码的其中一位,密码又由字母、数字、下划线、汉字组成。
match_obj = re.match("\w", "哈哈")
if match_obj:
result = match_obj.group()
print(result)
else:
print("输出失败!")
# \W:匹配非字母、数字、下划线、汉字
match_obj = re.match("\W", "%")
if match_obj:
result = match_obj.group()
print(result)
else:
print("输出失败!")

匹配多个字符
| 符号 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次,可有可无 |
| + | 匹配前一个字符出现1次或者无限次,即至少有一次 |
| ? | 匹配前一个字符出现1次或者0次,即要么次要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,n} | 匹配前一个字符出现m到n次 |
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
#author:tangyl
import re
# 匹配多个个字符
# *:匹配前一个字符出现0次或者无限次,即可有可无
match_obj = re.match("t.*o","tasdo")
if match_obj:
result = match_obj.group()
print(result)
else:
print("error!")
# +:匹配前一个字符出现1次或者无限次,即至少出现一次
match_obj = re.match("h.+","https")
if match_obj:
result = match_obj.group()
print(result)
else:
print("error!")
# ?:匹配前一个字符串出现0次或者1次
match_obj = re.match("https?","http")
if match_obj:
result = match_obj.group()
print(result)
else:
print("error!")
# {m}:匹配前一个字符串出现m次
match_obj = re.match("ht{2}ps?","http")
if match_obj:
result = match_obj.group()
print(result)
else:
print("error!")
# {m,n}:匹配前一个字符串出现m次,最多出现n次
match_obj = re.match("ht{1,3}ps?","htttp")
if match_obj:
result = match_obj.group()
print(result)
else:
print("error!")
# {m, }:匹配前一个字符串出现m次,
match_obj = re.match("ht{2,}ps?","htttp")
if match_obj:
result = match_obj.group()
print(result)
else:
print("error!")
`

匹配开头和结尾
| 符号 | 功能 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
!/usr/bin/env python3
#-*- coding:utf-8 -*-
#author:tangyl
import re
# ^匹配开头
# 匹配以数字开头所有数据
match_obj = re.match("^\d.*","12dlf")
if match_obj:
result = match_obj.group()
print(result)
else:
print("error!")
# $结尾
# 匹配以数字结尾所有数据
match_obj = re.match(".*\d$","lf2")
if match_obj:
result = match_obj.group()
print(result)
else:
print("error!")
# [^指定字符] 除了指定字符都匹配
# [^47]$c:除了47都匹配
match_obj = re.match("^\d.*[^47]$","2eelf247")
if match_obj:
result = match_obj.group()
print(result)
else:
print("error!")

匹配分组
| 符号 | 功能 |
|---|---|
| I | 匹配左右任意一个表达式 |
| (ab) | 将括号字符串作为一个分组 |
| \num | 引用分组num匹配到字符串 |
| (?< name >) | 分组起别名 |
| (?=name) | 引用别名为name分组匹配的字符串 |
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
#author:tangyl
import re
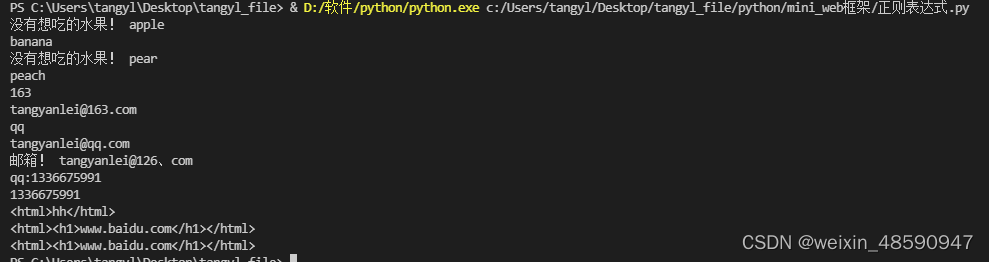
fruit_list = [ 'apple','banana','pear','peach']
# |:匹配多个字符
# 匹配分组
for value in fruit_list:
# 根据每一个字符串,使用正则表达式进行匹配
match_obj = re.match("banana|peach",value)
if match_obj:
result = match_obj.group()
print(result)
else:
print("没有想吃的水果!",value)
# (ab):将括号中字符作为一个分组
fruit_list1 = [ 'tangyanlei@163.com','tangyanlei@qq.com','tangyanlei@126、com']
for value in fruit_list1:
# 根据每一个字符串,使用正则表达式进行匹配
# \.:表示正则表达式中的.进行转译,只能匹配带.的字符
# (163|126|qq)表示一个分组,出现一个小括号就是出现一个分组,分组是从1开始的
match_obj = re.match("[a-zA-Z0-9_]{4,20}@(163|126|qq)\.com",value)
if match_obj:
result = match_obj.group()
type = match_obj.group(1)
print(type)
print(result)
else:
print("邮箱!",value)
# 匹配"qq:1336675991"
match_obj2 = re.match("(qq:)([1-9]\d{4,11})","qq:1336675991")
if match_obj2:
result = match_obj2.group()
print(result)
type = match_obj2.group(2)
print(type)
else:
print("(ab)","error")
# \num :引用分组匹配到数据
# <html>hh</html>
match_obj3 = re.match("<([a-zA-Z1-9]+)>.*</\\1>","<html>hh</html>")
if match_obj3:
result = match_obj3.group()
print(result)
else:
print("num","error")
# <html><h1>www.baudu.com</h1></html>
match_obj4 = re.match("<([a-zA-Z1-9]+)><([a-zA-Z1-9]+)>.*</\\2></\\1>","<html><h1>www.baidu.com</h1></html>")
if match_obj4:
result = match_obj4.group()
print(result)
else:
print("num","error")
# (?P<name>) 分组起别名
match_obj4 = re.match("<(?P<name1>[a-zA-Z1-9]+)><(?P<name2>[a-zA-Z1-9]+)>.*</(?P=name2)></(?P=name1)>","<html><h1>www.baidu.com</h1></html>")
if match_obj4:
result = match_obj4.group()
print(result)
else:
print("num","error")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









