







1.词频和词对频率(基础必备知识)
(1)词频(Term Frequency,TF)
词频,指的是某个词在文本中出现的次数,可以用来衡量一个词在文本中的重要性。例如有这样一句话:
我喜欢学习自然语言处理,因为自然语言处理很有趣!则可以通过分词后统计出每个词频有:

(2)词对频率(Bigram Frequency, BF)
词对频率,指的是两个连续的词(词对)在文本中出现的次数,它可以用来捕捉词语之间的关联性。同样使用上面那句话作为案例,可以统计出其词对频率有:

(3)总结
- 词频(TF) ,衡量的是单个词的出现频率;
- 词对频率(BF),衡量的是两个连续词的出现频率;
2.任务描述:对句子“我爱北京天安门”进行分词
(1)语料库准备
首先需要存在一个大型语料库,该语料库拥有海量数据和覆盖多个领域。并且该语料库已经由人工或者其他方法等进行好分词和词频统计,假设该语料库包含但不限于以下词频和词对频率:(此处为了后面计算简单好理解,假设的数字都比较小)

(2)列出可能的分词组合
根据语料库中存在的词,可以推断出该句子有4种可能的分词情况:

(3)计算每个可能组合的概率大小:

无需害怕公式
分词组合1:我 爱 北京 天安门
=p(我 爱 北京 天安门)

总词频是语料库的所有词频和,这里举例20是有问题的,毕竟前面展示的词频加起来已经超过20了,但是对于我们理解这个知识无碍,就这样吧,不想改了。
p(爱|我)的含义是计算当前一个词是“我”的概率下,后一个词是“爱”的概率大小,根据条件概率计算,分子分母都有总词频,所以约掉了,计算时直接利用:“我”的词频,和“我 爱”的词对频数,两个数值相除即可。后面的计算也是一样的。由此,计算出来该组合的概率大小约为0.08.
分词组合2:我爱 北京 天安门

分词组合3:我 爱北京 天安门

分词组合4:我 爱 北京天安门

(4)选择概率最大的分词组合
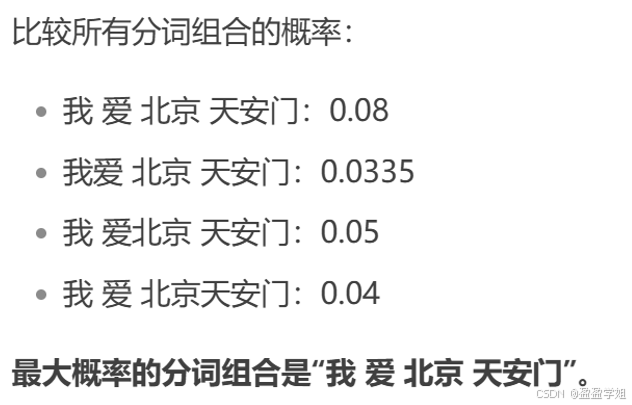
(5)总结
通过二元语法模型,我们可以基本想象到n元语法模型的计算过程。在实际应用中,语料库越大,词频和词对频率统计的越准确,分词效果就越好。
3.练习
相信大家只要认真看了上面的例子,是一定能看懂的,那就来练一练吧!
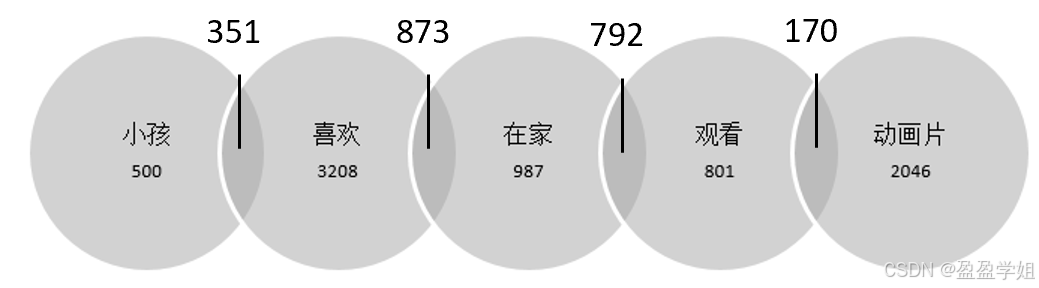
Ø假设语句序列为s={小孩,喜欢,在家,观看,动画片},估计这一语句的概率。以二元语法模型为例,需要检索语料库中每一个词以及和相邻词同时出现的概率。假设语料库中总词数7542,单词出现的次数如下图所示。其中 351,表示“小孩 喜欢”这个词对的频数。
揭晓答案:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









